 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Neural Strategy-Proof Matching Mechanism from Examples
Oct 25, 2024
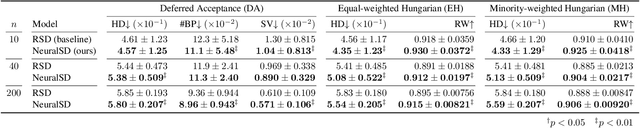


Designing effective two-sided matching mechanisms is a major problem in mechanism design, and the goodness of matching cannot always be formulated. The existing work addresses this issue by searching over a parameterized family of mechanisms with certain properties by learning to fit a human-crafted dataset containing examples of preference profiles and matching results. However, this approach does not consider a strategy-proof mechanism, implicitly assumes the number of agents to be a constant, and does not consider the public contextual information of the agents. In this paper, we propose a new parametric family of strategy-proof matching mechanisms by extending the serial dictatorship (SD). We develop a novel attention-based neural network called NeuralSD, which can learn a strategy-proof mechanism from a human-crafted dataset containing public contextual information. NeuralSD is constructed by tensor operations that make SD differentiable and learns a parameterized mechanism by estimating an order of SD from the contextual information. We conducted experiments to learn a strategy-proof matching from matching examples with different numbers of agents. We demonstrated that our method shows the superiority of learning with context-awareness over a baseline in terms of regression performance and other metrics.
Learning Fair and Preferable Allocations through Neural Network
Oct 23, 2024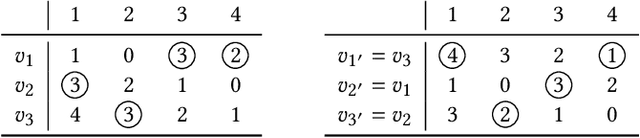



The fair allocation of indivisible resources is a fundamental problem. Existing research has developed various allocation mechanisms or algorithms to satisfy different fairness notions. For example, round robin (RR) was proposed to meet the fairness criterion known as envy-freeness up to one good (EF1). Expert algorithms without mathematical formulations are used in real-world resource allocation problems to find preferable outcomes for users. Therefore, we aim to design mechanisms that strictly satisfy good properties with replicating expert knowledge. However, this problem is challenging because such heuristic rules are often difficult to formalize mathematically, complicating their integration into theoretical frameworks. Additionally, formal algorithms struggle to find preferable outcomes, and directly replicating these implicit rules can result in unfair allocations because human decision-making can introduce biases. In this paper, we aim to learn implicit allocation mechanisms from examples while strictly satisfying fairness constraints, specifically focusing on learning EF1 allocation mechanisms through supervised learning on examples of reported valuations and corresponding allocation outcomes produced by implicit rules. To address this, we developed a neural RR (NRR), a novel neural network that parameterizes RR. NRR is built from a differentiable relaxation of RR and can be trained to learn the agent ordering used for RR. We conducted experiments to learn EF1 allocation mechanisms from examples, demonstrating that our method outperforms baselines in terms of the proximity of predicted allocations and other metrics.