 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Cross-Distillation for Membership Privacy
Paper and Code
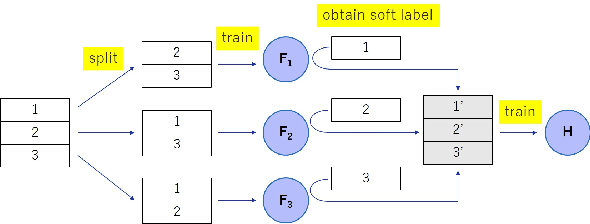
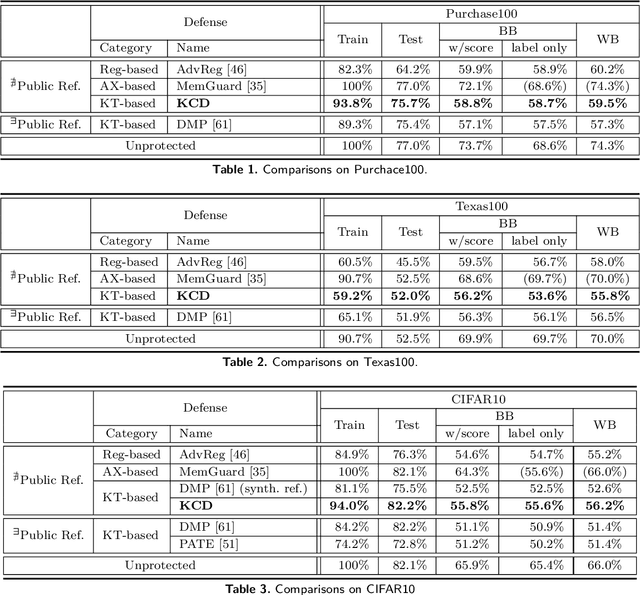
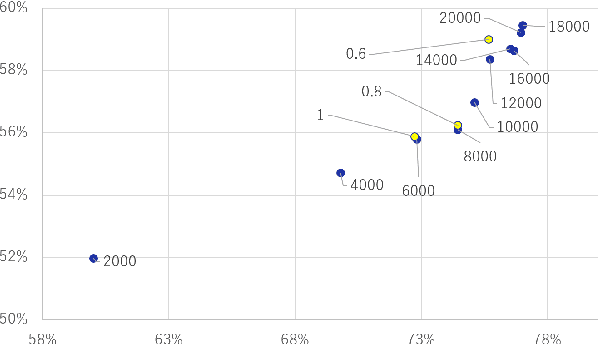
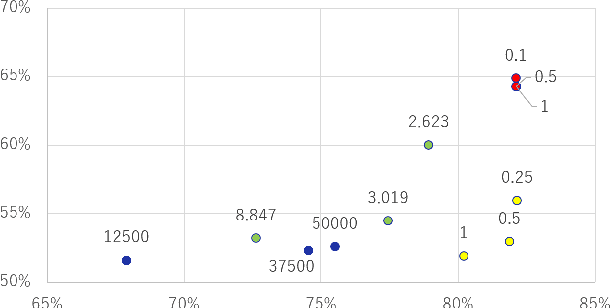
A membership inference attack (MIA) poses privacy risks on the training data of a machine learning model. With an MIA, an attacker guesses if the target data are a member of the training dataset. The state-of-the-art defense against MIAs, distillation for membership privacy (DMP), requires not only private data to protect but a large amount of unlabeled public data. However, in certain privacy-sensitive domains, such as medical and financial, the availability of public data is not obvious. Moreover, a trivial method to generate the public data by using generative adversarial networks significantly decreases the model accuracy, as reported by the authors of DMP. To overcome this problem, we propose a novel defense against MIAs using knowledge distillation without requiring public data. Our experiments show that the privacy protection and accuracy of our defense are comparable with those of DMP for the benchmark tabular datasets used in MIA researches, Purchase100 and Texas100, and our defense has much better privacy-utility trade-off than those of the existing defenses without using public data for image dataset CIFAR10.