 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRectifying Adversarial Examples Using Their Vulnerabilities
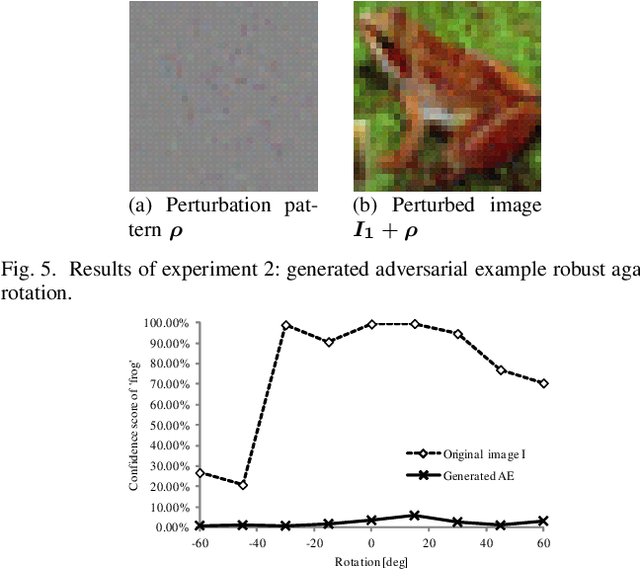
Jan 01, 2026Deep neural network-based classifiers are prone to errors when processing adversarial examples (AEs). AEs are minimally perturbed input data undetectable to humans posing significant risks to security-dependent applications. Hence, extensive research has been undertaken to develop defense mechanisms that mitigate their threats. Most existing methods primarily focus on discriminating AEs based on the input sample features, emphasizing AE detection without addressing the correct sample categorization before an attack. While some tasks may only require mere rejection on detected AEs, others necessitate identifying the correct original input category such as traffic sign recognition in autonomous driving. The objective of this study is to propose a method for rectifying AEs to estimate the correct labels of their original inputs. Our method is based on re-attacking AEs to move them beyond the decision boundary for accurate label prediction, effectively addressing the issue of rectifying minimally perceptible AEs created using white-box attack methods. However, challenge remains with respect to effectively rectifying AEs produced by black-box attacks at a distance from the boundary, or those misclassified into low-confidence categories by targeted attacks. By adopting a straightforward approach of only considering AEs as inputs, the proposed method can address diverse attacks while avoiding the requirement of parameter adjustments or preliminary training. Results demonstrate that the proposed method exhibits consistent performance in rectifying AEs generated via various attack methods, including targeted and black-box attacks. Moreover, it outperforms conventional rectification and input transformation methods in terms of stability against various attacks.
Vehicle Painting Robot Path Planning Using Hierarchical Optimization
Jan 01, 2026In vehicle production factories, the vehicle painting process employs multiple robotic arms to simultaneously apply paint to car bodies advancing along a conveyor line. Designing paint paths for these robotic arms, which involves assigning car body areas to arms and determining paint sequences for each arm, remains a time-consuming manual task for engineers, indicating the demand for automation and design time reduction. The unique constraints of the painting process hinder the direct application of conventional robotic path planning techniques, such as those used in welding. Therefore, this paper formulates the design of paint paths as a hierarchical optimization problem, where the upper-layer subproblem resembles a vehicle routing problem (VRP), and the lower-layer subproblem involves detailed path planning. This approach allows the use of different optimization algorithms at each layer, and permits flexible handling of constraints specific to the vehicle painting process through the design of variable representation, constraints, repair operators, and an initialization process at the upper and lower layers. Experiments with three commercially available vehicle models demonstrated that the proposed method can automatically design paths that satisfy all constraints for vehicle painting with quality comparable to those created manually by engineers.
Projection-based Adversarial Attack using Physics-in-the-Loop Optimization for Monocular Depth Estimation
Dec 31, 2025Deep neural networks (DNNs) remain vulnerable to adversarial attacks that cause misclassification when specific perturbations are added to input images. This vulnerability also threatens the reliability of DNN-based monocular depth estimation (MDE) models, making robustness enhancement a critical need in practical applications. To validate the vulnerability of DNN-based MDE models, this study proposes a projection-based adversarial attack method that projects perturbation light onto a target object. The proposed method employs physics-in-the-loop (PITL) optimization -- evaluating candidate solutions in actual environments to account for device specifications and disturbances -- and utilizes a distributed covariance matrix adaptation evolution strategy. Experiments confirmed that the proposed method successfully created adversarial examples that lead to depth misestimations, resulting in parts of objects disappearing from the target scene.
A study on constraint extraction and exception exclusion in care worker scheduling
Dec 31, 2025Technologies for automatically generating work schedules have been extensively studied; however, in long-term care facilities, the conditions vary between facilities, making it essential to interview the managers who create shift schedules to design facility-specific constraint conditions. The proposed method utilizes constraint templates to extract combinations of various components, such as shift patterns for consecutive days or staff combinations. The templates can extract a variety of constraints by changing the number of days and the number of staff members to focus on and changing the extraction focus to patterns or frequency. In addition, unlike existing constraint extraction techniques, this study incorporates mechanisms to exclude exceptional constraints. The extracted constraints can be employed by a constraint programming solver to create care worker schedules. Experiments demonstrated that our proposed method successfully created schedules that satisfied all hard constraints and reduced the number of violations for soft constraints by circumventing the extraction of exceptional constraints.
Neural Radiance Field Image Refinement through End-to-End Sampling Point Optimization
Oct 19, 2024Neural Radiance Field (NeRF), capable of synthesizing high-quality novel viewpoint images, suffers from issues like artifact occurrence due to its fixed sampling points during rendering. This study proposes a method that optimizes sampling points to reduce artifacts and produce more detailed images.
EvolBA: Evolutionary Boundary Attack under Hard-label Black Box condition
Jul 02, 2024Research has shown that deep neural networks (DNNs) have vulnerabilities that can lead to the misrecognition of Adversarial Examples (AEs) with specifically designed perturbations. Various adversarial attack methods have been proposed to detect vulnerabilities under hard-label black box (HL-BB) conditions in the absence of loss gradients and confidence scores.However, these methods fall into local solutions because they search only local regions of the search space. Therefore, this study proposes an adversarial attack method named EvolBA to generate AEs using Covariance Matrix Adaptation Evolution Strategy (CMA-ES) under the HL-BB condition, where only a class label predicted by the target DNN model is available. Inspired by formula-driven supervised learning, the proposed method introduces domain-independent operators for the initialization process and a jump that enhances search exploration. Experimental results confirmed that the proposed method could determine AEs with smaller perturbations than previous methods in images where the previous methods have difficulty.
Black-box Adversarial Attacks on Monocular Depth Estimation Using Evolutionary Multi-objective Optimization
Dec 29, 2020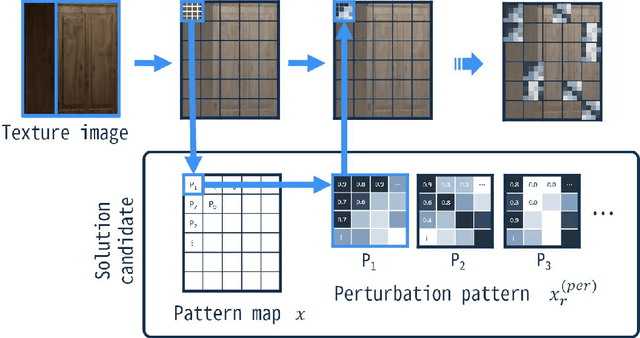


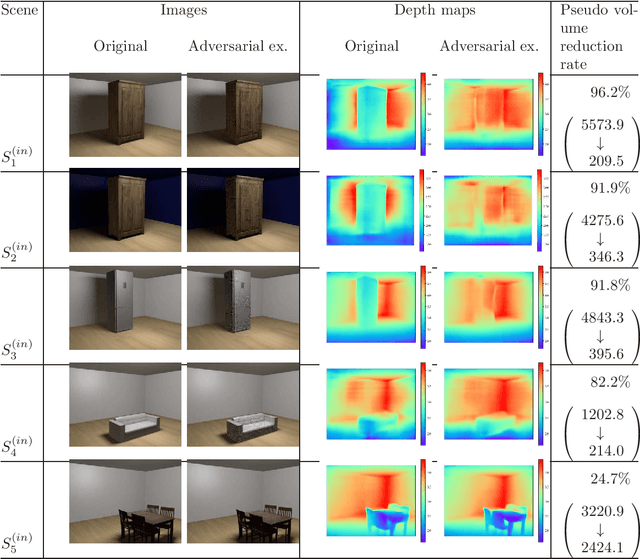
This paper proposes an adversarial attack method to deep neural networks (DNNs) for monocular depth estimation, i.e., estimating the depth from a single image. Single image depth estimation has improved drastically in recent years due to the development of DNNs. However, vulnerabilities of DNNs for image classification have been revealed by adversarial attacks, and DNNs for monocular depth estimation could contain similar vulnerabilities. Therefore, research on vulnerabilities of DNNs for monocular depth estimation has spread rapidly, but many of them assume white-box conditions where inside information of DNNs is available, or are transferability-based black-box attacks that require a substitute DNN model and a training dataset. Utilizing Evolutionary Multi-objective Optimization, the proposed method in this paper analyzes DNNs under the black-box condition where only output depth maps are available. In addition, the proposed method does not require a substitute DNN that has a similar architecture to the target DNN nor any knowledge about training data used to train the target model. Experimental results showed that the proposed method succeeded in attacking two DNN-based methods that were trained with indoor and outdoor scenes respectively.
Adjust-free adversarial example generation in speech recognition using evolutionary multi-objective optimization under black-box condition
Dec 22, 2020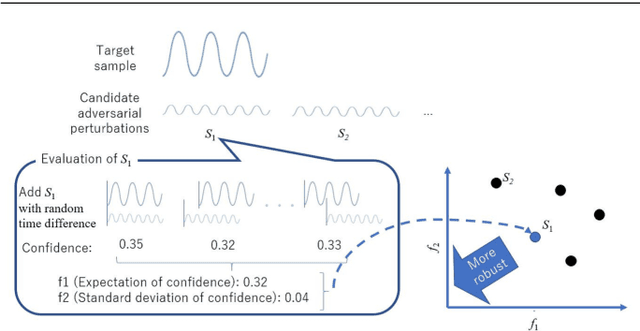


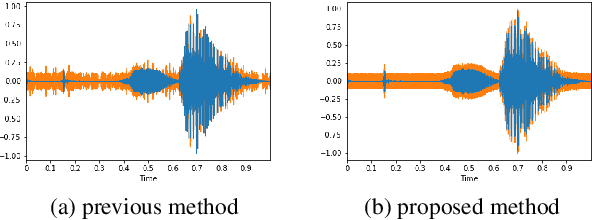
This paper proposes a black-box adversarial attack method to automatic speech recognition systems. Some studies have attempted to attack neural networks for speech recognition; however, these methods did not consider the robustness of generated adversarial examples against timing lag with a target speech. The proposed method in this paper adopts Evolutionary Multi-objective Optimization (EMO)that allows it generating robust adversarial examples under black-box scenario. Experimental results showed that the proposed method successfully generated adjust-free adversarial examples, which are sufficiently robust against timing lag so that an attacker does not need to take the timing of playing it against the target speech.
Depth estimation from 4D light field videos
Dec 08, 2020
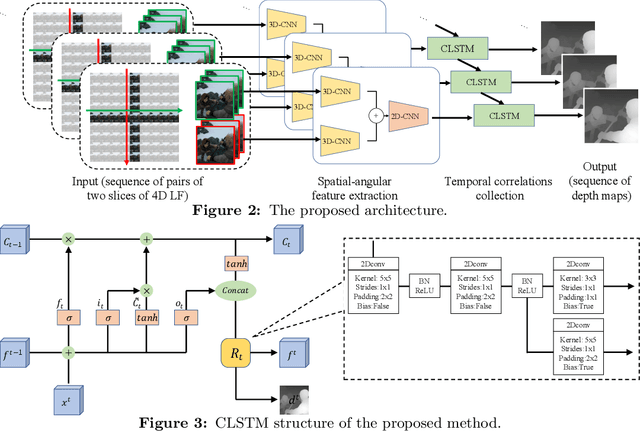


Depth (disparity) estimation from 4D Light Field (LF) images has been a research topic for the last couple of years. Most studies have focused on depth estimation from static 4D LF images while not considering temporal information, i.e., LF videos. This paper proposes an end-to-end neural network architecture for depth estimation from 4D LF videos. This study also constructs a medium-scale synthetic 4D LF video dataset that can be used for training deep learning-based methods. Experimental results using synthetic and real-world 4D LF videos show that temporal information contributes to the improvement of depth estimation accuracy in noisy regions. Dataset and code is available at: https://mediaeng-lfv.github.io/LFV_Disparity_Estimation
Adversarial Example Generation using Evolutionary Multi-objective Optimization
Dec 30, 2019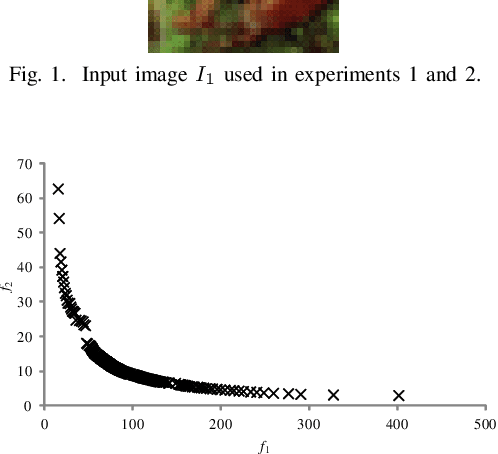
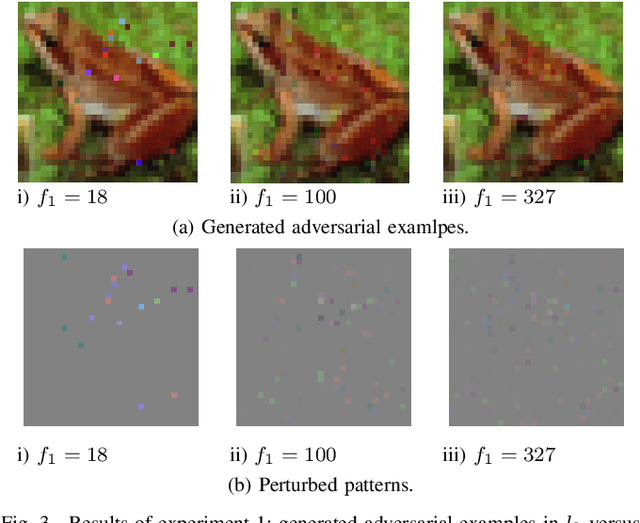
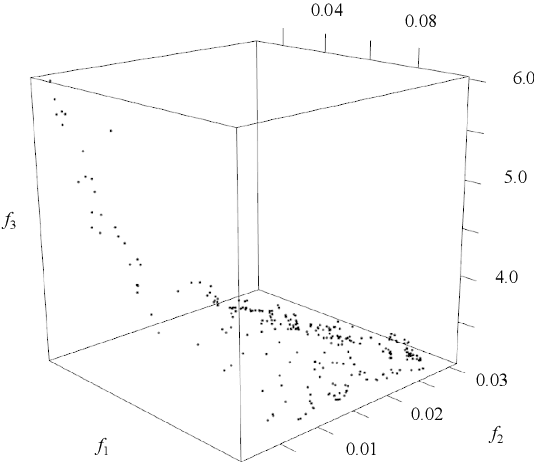
This paper proposes Evolutionary Multi-objective Optimization (EMO)-based Adversarial Example (AE) design method that performs under black-box setting. Previous gradient-based methods produce AEs by changing all pixels of a target image, while previous EC-based method changes small number of pixels to produce AEs. Thanks to EMO's property of population based-search, the proposed method produces various types of AEs involving ones locating between AEs generated by the previous two approaches, which helps to know the characteristics of a target model or to know unknown attack patterns. Experimental results showed the potential of the proposed method, e.g., it can generate robust AEs and, with the aid of DCT-based perturbation pattern generation, AEs for high resolution images.