 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Degree of Ill-posedness Estimation for Active Small Object Change Detection
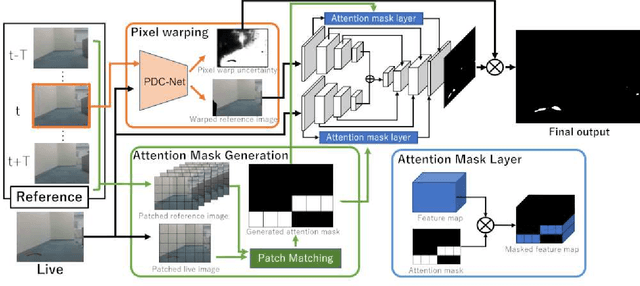
May 10, 2024In everyday indoor navigation, robots often needto detect non-distinctive small-change objects (e.g., stationery,lost items, and junk, etc.) to maintain domain knowledge. Thisis most relevant to ground-view change detection (GVCD), a recently emerging research area in the field of computer vision.However, these existing techniques rely on high-quality class-specific object priors to regularize a change detector modelthat cannot be applied to semantically nondistinctive smallobjects. To address ill-posedness, in this study, we explorethe concept of degree-of-ill-posedness (DoI) from the newperspective of GVCD, aiming to improve both passive and activevision. This novel DoI problem is highly domain-dependent,and manually collecting fine-grained annotated training datais expensive. To regularize this problem, we apply the conceptof self-supervised learning to achieve efficient DoI estimationscheme and investigate its generalization to diverse datasets.Specifically, we tackle the challenging issue of obtaining self-supervision cues for semantically non-distinctive unseen smallobjects and show that novel "oversegmentation cues" from openvocabulary semantic segmentation can be effectively exploited.When applied to diverse real datasets, the proposed DoI modelcan boost state-of-the-art change detection models, and it showsstable and consistent improvements when evaluated on real-world datasets.
Lifelong Change Detection: Continuous Domain Adaptation for Small Object Change Detection in Every Robot Navigation
Jun 28, 2023



The recently emerging research area in robotics, ground view change detection, suffers from its ill-posed-ness because of visual uncertainty combined with complex nonlinear perspective projection. To regularize the ill-posed-ness, the commonly applied supervised learning methods (e.g., CSCD-Net) rely on manually annotated high-quality object-class-specific priors. In this work, we consider general application domains where no manual annotation is available and present a fully self-supervised approach. The present approach adopts the powerful and versatile idea that object changes detected during everyday robot navigation can be reused as additional priors to improve future change detection tasks. Furthermore, a robustified framework is implemented and verified experimentally in a new challenging practical application scenario: ground-view small object change detection.
Domain Invariant Siamese Attention Mask for Small Object Change Detection via Everyday Indoor Robot Navigation
Mar 29, 2022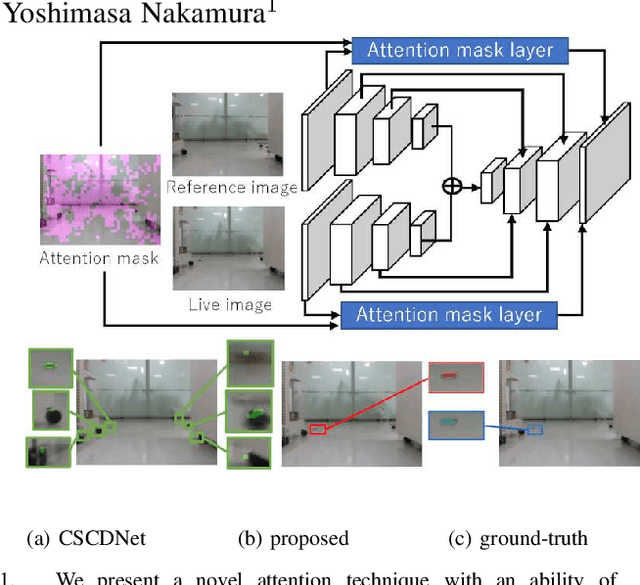


The problem of image change detection via everyday indoor robot navigation is explored from a novel perspective of the self-attention technique. Detecting semantically non-distinctive and visually small changes remains a key challenge in the robotics community. Intuitively, these small non-distinctive changes may be better handled by the recent paradigm of the attention mechanism, which is the basic idea of this work. However, existing self-attention models require significant retraining cost per domain, so it is not directly applicable to robotics applications. We propose a new self-attention technique with an ability of unsupervised on-the-fly domain adaptation, which introduces an attention mask into the intermediate layer of an image change detection model, without modifying the input and output layers of the model. Experiments, in which an indoor robot aims to detect visually small changes in everyday navigation, demonstrate that our attention technique significantly boosts the state-of-the-art image change detection model.
Exploring Self-Attention for Visual Intersection Classification
Mar 26, 2022
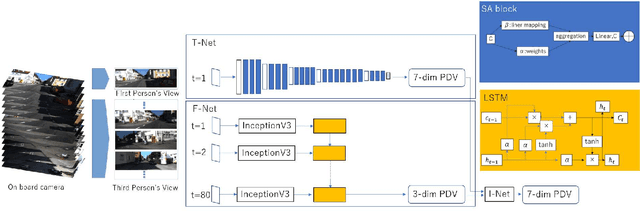


In robot vision, self-attention has recently emerged as a technique for capturing non-local contexts. In this study, we introduced a self-attention mechanism into the intersection recognition system as a method to capture the non-local contexts behind the scenes. An intersection classification system comprises two distinctive modules: (a) a first-person vision (FPV) module, which uses a short egocentric view sequence as the intersection is passed, and (b) a third-person vision (TPV) module, which uses a single view immediately before entering the intersection. The self-attention mechanism is effective in the TPV module because most parts of the local pattern (e.g., road edges, buildings, and sky) are similar to each other, and thus the use of a non-local context (e.g., the angle between two diagonal corners around an intersection) would be effective. This study makes three major contributions. First, we proposed a self-attention-based approach for intersection classification using TPVs. Second, we presented a practical system in which a self-attention-based TPV module is combined with an FPV module to improve the overall recognition performance. Finally, experiments using the public KITTI dataset show that the above self-attention-based system outperforms conventional recognition based on local patterns and recognition based on convolution operations.
TaylorMade VDD: Domain-adaptive Visual Defect Detector for High-mix Low-volume Production of Non-convex Cylindrical Metal Objects
Apr 09, 2021



Visual defect detection (VDD) for high-mix low-volume production of non-convex metal objects, such as high-pressure cylindrical piping joint parts (VDD-HPPPs), is challenging because subtle difference in domain (e.g., metal objects, imaging device, viewpoints, lighting) significantly affects the specular reflection characteristics of individual metal object types. In this paper, we address this issue by introducing a tailor-made VDD framework that can be automatically adapted to a new domain. Specifically, we formulate this adaptation task as the problem of network architecture search (NAS) on a deep object-detection network, in which the network architecture is searched via reinforcement learning. We demonstrate the effectiveness of the proposed framework using the VDD-HPPPs task as a factory case study. Experimental results show that the proposed method achieved higher burr detection accuracy compared with the baseline method for data with different training/test domains for the non-convex HPPPs, which are particularly affected by domain shifts.
Dark Reciprocal-Rank: Boosting Graph-Convolutional Self-Localization Network via Teacher-to-student Knowledge Transfer
Nov 01, 2020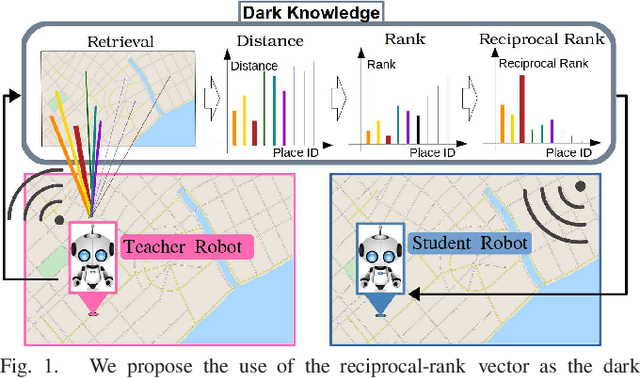

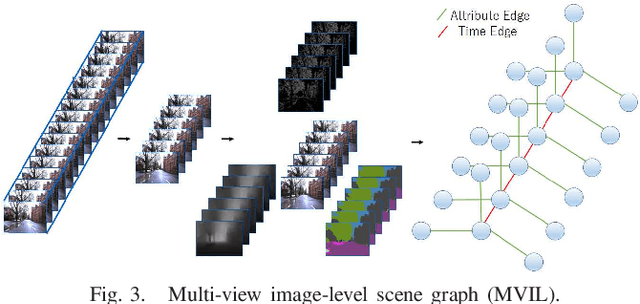
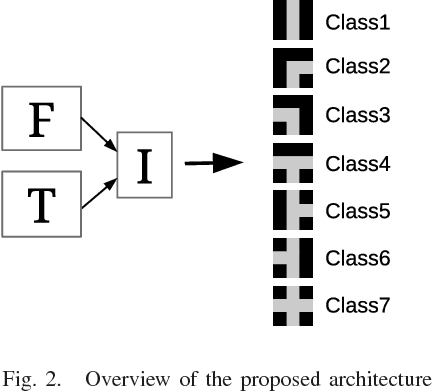
In visual robot self-localization, graph-based scene representation and matching have recently attracted research interest as robust and discriminative methods for selflocalization. Although effective, their computational and storage costs do not scale well to large-size environments. To alleviate this problem, we formulate self-localization as a graph classification problem and attempt to use the graph convolutional neural network (GCN) as a graph classification engine. A straightforward approach is to use visual feature descriptors that are employed by state-of-the-art self-localization systems, directly as graph node features. However, their superior performance in the original self-localization system may not necessarily be replicated in GCN-based self-localization. To address this issue, we introduce a novel teacher-to-student knowledge-transfer scheme based on rank matching, in which the reciprocal-rank vector output by an off-the-shelf state-of-the-art teacher self-localization model is used as the dark knowledge to transfer. Experiments indicate that the proposed graph-convolutional self-localization network can significantly outperform state-of-the-art self-localization systems, as well as the teacher classifier.
Use of First and Third Person Views for Deep Intersection Classification
Jan 22, 2019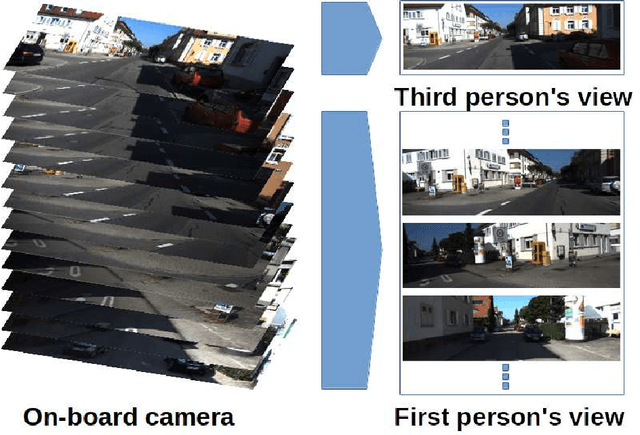
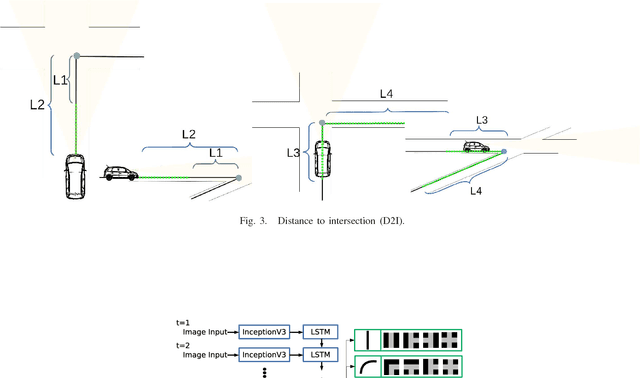
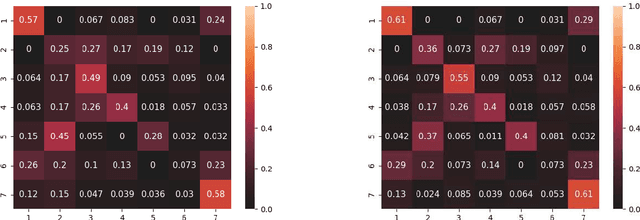
We explore the problem of intersection classification using monocular on-board passive vision, with the goal of classifying traffic scenes with respect to road topology. We divide the existing approaches into two broad categories according to the type of input data: (a) first person vision (FPV) approaches, which use an egocentric view sequence as the intersection is passed; and (b) third person vision (TPV) approaches, which use a single view immediately before entering the intersection. The FPV and TPV approaches each have advantages and disadvantages. Therefore, we aim to combine them into a unified deep learning framework. Experimental results show that the proposed FPV-TPV scheme outperforms previous methods and only requires minimal FPV/TPV measurements.