 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Degree of Ill-posedness Estimation for Active Small Object Change Detection
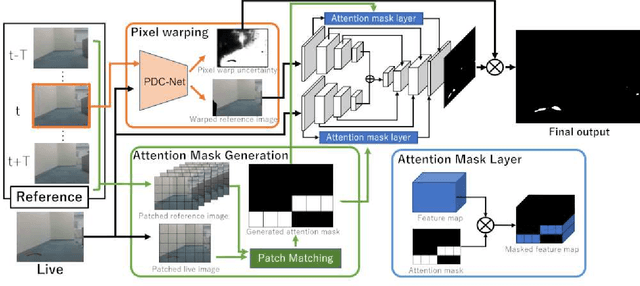
May 10, 2024In everyday indoor navigation, robots often needto detect non-distinctive small-change objects (e.g., stationery,lost items, and junk, etc.) to maintain domain knowledge. Thisis most relevant to ground-view change detection (GVCD), a recently emerging research area in the field of computer vision.However, these existing techniques rely on high-quality class-specific object priors to regularize a change detector modelthat cannot be applied to semantically nondistinctive smallobjects. To address ill-posedness, in this study, we explorethe concept of degree-of-ill-posedness (DoI) from the newperspective of GVCD, aiming to improve both passive and activevision. This novel DoI problem is highly domain-dependent,and manually collecting fine-grained annotated training datais expensive. To regularize this problem, we apply the conceptof self-supervised learning to achieve efficient DoI estimationscheme and investigate its generalization to diverse datasets.Specifically, we tackle the challenging issue of obtaining self-supervision cues for semantically non-distinctive unseen smallobjects and show that novel "oversegmentation cues" from openvocabulary semantic segmentation can be effectively exploited.When applied to diverse real datasets, the proposed DoI modelcan boost state-of-the-art change detection models, and it showsstable and consistent improvements when evaluated on real-world datasets.
Lifelong Change Detection: Continuous Domain Adaptation for Small Object Change Detection in Every Robot Navigation
Jun 28, 2023



The recently emerging research area in robotics, ground view change detection, suffers from its ill-posed-ness because of visual uncertainty combined with complex nonlinear perspective projection. To regularize the ill-posed-ness, the commonly applied supervised learning methods (e.g., CSCD-Net) rely on manually annotated high-quality object-class-specific priors. In this work, we consider general application domains where no manual annotation is available and present a fully self-supervised approach. The present approach adopts the powerful and versatile idea that object changes detected during everyday robot navigation can be reused as additional priors to improve future change detection tasks. Furthermore, a robustified framework is implemented and verified experimentally in a new challenging practical application scenario: ground-view small object change detection.
Domain Invariant Siamese Attention Mask for Small Object Change Detection via Everyday Indoor Robot Navigation
Mar 29, 2022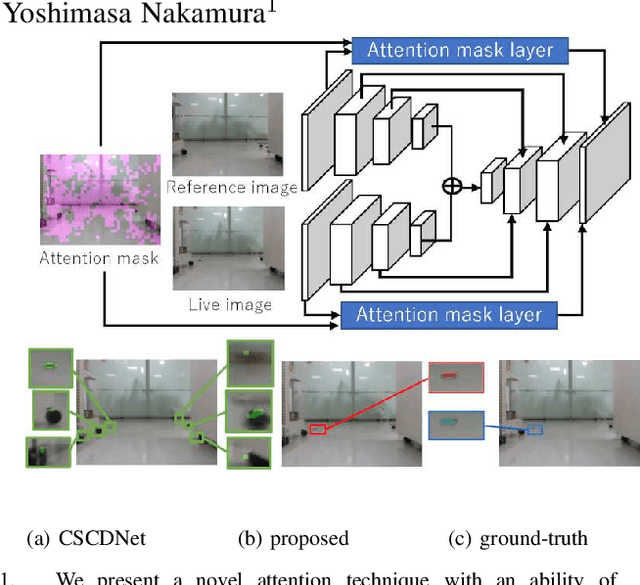


The problem of image change detection via everyday indoor robot navigation is explored from a novel perspective of the self-attention technique. Detecting semantically non-distinctive and visually small changes remains a key challenge in the robotics community. Intuitively, these small non-distinctive changes may be better handled by the recent paradigm of the attention mechanism, which is the basic idea of this work. However, existing self-attention models require significant retraining cost per domain, so it is not directly applicable to robotics applications. We propose a new self-attention technique with an ability of unsupervised on-the-fly domain adaptation, which introduces an attention mask into the intermediate layer of an image change detection model, without modifying the input and output layers of the model. Experiments, in which an indoor robot aims to detect visually small changes in everyday navigation, demonstrate that our attention technique significantly boosts the state-of-the-art image change detection model.