 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dual-Stream Transformer Architecture for Illumination-Invariant TIR-LiDAR Person Tracking
Apr 01, 2026Robust person tracking is a critical capability for autonomous mobile robots operating in diverse and unpredictable environments. While RGB-D tracking has shown high precision, its performance severely degrades under challenging illumination conditions, such as total darkness or intense backlighting. To achieve all-weather robustness, this paper proposes a novel Thermal-Infrared and Depth (TIR-D) tracking architecture that leverages the standard sensor suite of SLAM-capable robots, namely LiDAR and TIR cameras. A major challenge in TIR-D tracking is the scarcity of annotated multi-modal datasets. To address this, we introduce a sequential knowledge transfer strategy that evolves structural priors from a large-scale thermal-trained model into the TIR-D domain. By employing a differential learning rate strategy -- referred to as ``Fine-grained Differential Learning Rate Strategy'' -- we effectively preserve pre-trained feature extraction capabilities while enabling rapid adaptation to geometric depth cues. Experimental results demonstrate that our proposed TIR-D tracker achieves superior performance, with an Average Overlap (AO) of 0.700 and a Success Rate (SR) of 58.7\%, significantly outperforming conventional RGB-transfer and single-modality baselines. Our approach provides a practical and resource-efficient solution for robust human-following in all-weather robotics applications.
From Reactive to Map-Based AI: Tuned Local LLMs for Semantic Zone Inference in Object-Goal Navigation
Mar 09, 2026Object-Goal Navigation (ObjectNav) requires an agent to find and navigate to a target object category in unknown environments. While recent Large Language Model (LLM)-based agents exhibit zero-shot reasoning, they often rely on a "reactive" paradigm that lacks explicit spatial memory, leading to redundant exploration and myopic behaviors. To address these limitations, we propose a transition from reactive AI to "Map-Based AI" by integrating LLM-based semantic inference with a hybrid topological-grid mapping system. Our framework employs a fine-tuned Llama-2 model via Low-Rank Adaptation (LoRA) to infer semantic zone categories and target existence probabilities from verbalized object observations. In this study, a "zone" is defined as a functional area described by the set of observed objects, providing crucial semantic co-occurrence cues for finding the target. This semantic information is integrated into a topological graph, enabling the agent to prioritize high-probability areas and perform systematic exploration via Traveling Salesman Problem (TSP) optimization. Evaluations in the AI2-THOR simulator demonstrate that our approach significantly outperforms traditional frontier exploration and reactive LLM baselines, achieving a superior Success Rate (SR) and Success weighted by Path Length (SPL).
Pole-centric Descriptors for Robust Robot Localization: Evaluation under Pole-at-Distance (PaD) Observations using the Small Pole Landmark (SPL) Dataset
Dec 29, 2025While pole-like structures are widely recognized as stable geometric anchors for long-term robot localization, their identification reliability degrades significantly under Pole-at-Distance (Pad) observations typical of large-scale urban environments. This paper shifts the focus from descriptor design to a systematic investigation of descriptor robustness. Our primary contribution is the establishment of a specialized evaluation framework centered on the Small Pole Landmark (SPL) dataset. This dataset is constructed via an automated tracking-based association pipeline that captures multi-view, multi-distance observations of the same physical landmarks without manual annotation. Using this framework, we present a comparative analysis of Contrastive Learning (CL) and Supervised Learning (SL) paradigms. Our findings reveal that CL induces a more robust feature space for sparse geometry, achieving superior retrieval performance particularly in the 5--10m range. This work provides an empirical foundation and a scalable methodology for evaluating landmark distinctiveness in challenging real-world scenarios.
MOON: Multi-Objective Optimization-Driven Object-Goal Navigation Using a Variable-Horizon Set-Orienteering Planner
May 19, 2025Object-goal navigation (ON) enables autonomous robots to locate and reach user-specified objects in previously unknown environments, offering promising applications in domains such as assistive care and disaster response. Existing ON methods -- including training-free approaches, reinforcement learning, and zero-shot planners -- generally depend on active exploration to identify landmark objects (e.g., kitchens or desks), followed by navigation toward semantically related targets (e.g., a specific mug). However, these methods often lack strategic planning and do not adequately address trade-offs among multiple objectives. To overcome these challenges, we propose a novel framework that formulates ON as a multi-objective optimization problem (MOO), balancing frontier-based knowledge exploration with knowledge exploitation over previously observed landmarks; we call this framework MOON (MOO-driven ON). We implement a prototype MOON system that integrates three key components: (1) building on QOM [IROS05], a classical ON system that compactly and discriminatively encodes landmarks based on their semantic relevance to the target; (2) integrating StructNav [RSS23], a recently proposed training-free planner, to enhance the navigation pipeline; and (3) introducing a variable-horizon set orienteering problem formulation to enable global optimization over both exploration and exploitation strategies. This work represents an important first step toward developing globally optimized, next-generation object-goal navigation systems.
LGR: LLM-Guided Ranking of Frontiers for Object Goal Navigation
Mar 26, 2025Object Goal Navigation (OGN) is a fundamental task for robots and AI, with key applications such as mobile robot image databases (MRID). In particular, mapless OGN is essential in scenarios involving unknown or dynamic environments. This study aims to enhance recent modular mapless OGN systems by leveraging the commonsense reasoning capabilities of large language models (LLMs). Specifically, we address the challenge of determining the visiting order in frontier-based exploration by framing it as a frontier ranking problem. Our approach is grounded in recent findings that, while LLMs cannot determine the absolute value of a frontier, they excel at evaluating the relative value between multiple frontiers viewed within a single image using the view image as context. We dynamically manage the frontier list by adding and removing elements, using an LLM as a ranking model. The ranking results are represented as reciprocal rank vectors, which are ideal for multi-view, multi-query information fusion. We validate the effectiveness of our method through evaluations in Habitat-Sim.
Dynamic-Dark SLAM: RGB-Thermal Cooperative Robot Vision Strategy for Multi-Person Tracking in Both Well-Lit and Low-Light Scenes
Mar 17, 2025


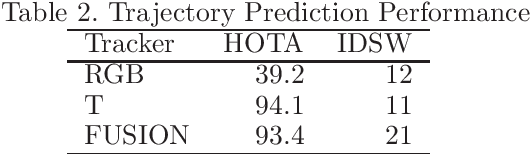
In robot vision, thermal cameras have significant potential for recognizing humans even in complete darkness. However, their application to multi-person tracking (MPT) has lagged due to data scarcity and difficulties in individual identification. In this study, we propose a cooperative MPT system that utilizes co-located RGB and thermal cameras, using pseudo-annotations (bounding boxes + person IDs) to train RGB and T trackers. Evaluation experiments demonstrate that the T tracker achieves remarkable performance in both bright and dark scenes. Furthermore, results suggest that a tracker-switching approach using a binary brightness classifier is more suitable than a tracker-fusion approach for information integration. This study marks a crucial first step toward ``Dynamic-Dark SLAM," enabling effective recognition, understanding, and reconstruction of individuals, occluding objects, and traversable areas in dynamic environments, both bright and dark.
Continual Multi-Robot Learning from Black-Box Visual Place Recognition Models
Mar 04, 2025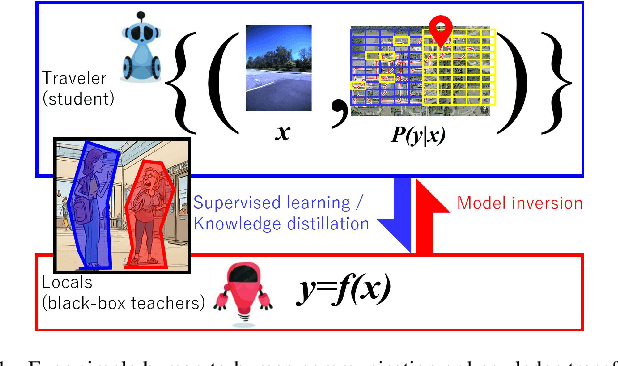

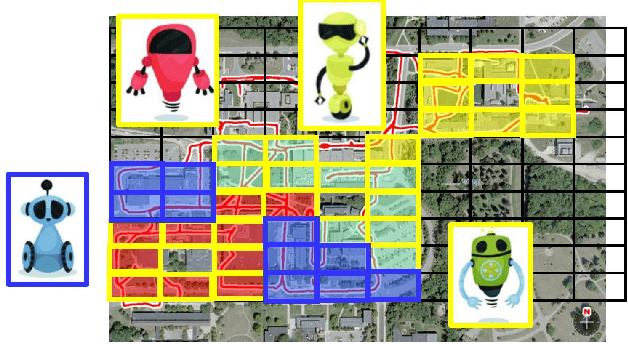
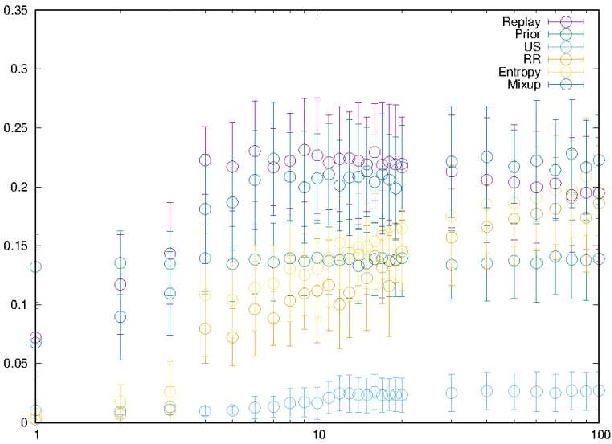
In the context of visual place recognition (VPR), continual learning (CL) techniques offer significant potential for avoiding catastrophic forgetting when learning new places. However, existing CL methods often focus on knowledge transfer from a known model to a new one, overlooking the existence of unknown black-box models. We explore a novel multi-robot CL approach that enables knowledge transfer from black-box VPR models (teachers), such as those of local robots encountered by traveler robots (students) in unknown environments. Specifically, we introduce Membership Inference Attack, or MIA, the only major privacy attack applicable to black-box models, and leverage it to reconstruct pseudo training sets, which serve as the key knowledge to be exchanged between robots, from black-box VPR models. Furthermore, we aim to overcome the inherently low sampling efficiency of MIA by leveraging insights on place class prediction distribution and un-learned class detection imported from the VPR literature as a prior distribution. We also analyze both the individual effects of these methods and their combined impact. Experimental results demonstrate that our black-box MIA (BB-MIA) approach is remarkably powerful despite its simplicity, significantly enhancing the VPR capability of lower-performing robots through brief communication with other robots. This study contributes to optimizing knowledge sharing between robots in VPR and enhancing autonomy in open-world environments with multi-robot systems that are fault-tolerant and scalable.
LMD-PGN: Cross-Modal Knowledge Distillation from First-Person-View Images to Third-Person-View BEV Maps for Universal Point Goal Navigation
Dec 23, 2024Point goal navigation (PGN) is a mapless navigation approach that trains robots to visually navigate to goal points without relying on pre-built maps. Despite significant progress in handling complex environments using deep reinforcement learning, current PGN methods are designed for single-robot systems, limiting their generalizability to multi-robot scenarios with diverse platforms. This paper addresses this limitation by proposing a knowledge transfer framework for PGN, allowing a teacher robot to transfer its learned navigation model to student robots, including those with unknown or black-box platforms. We introduce a novel knowledge distillation (KD) framework that transfers first-person-view (FPV) representations (view images, turning/forward actions) to universally applicable third-person-view (TPV) representations (local maps, subgoals). The state is redefined as reconstructed local maps using SLAM, while actions are mapped to subgoals on a predefined grid. To enhance training efficiency, we propose a sampling-efficient KD approach that aligns training episodes via a noise-robust local map descriptor (LMD). Although validated on 2D wheeled robots, this method can be extended to 3D action spaces, such as drones. Experiments conducted in Habitat-Sim demonstrate the feasibility of the proposed framework, requiring minimal implementation effort. This study highlights the potential for scalable and cross-platform PGN solutions, expanding the applicability of embodied AI systems in multi-robot scenarios.
ON as ALC: Active Loop Closing Object Goal Navigation
Dec 16, 2024In simultaneous localization and mapping, active loop closing (ALC) is an active vision problem that aims to visually guide a robot to maximize the chances of revisiting previously visited points, thereby resetting the drift errors accumulated in the incrementally built map during travel. However, current mainstream navigation strategies that leverage such incomplete maps as workspace prior knowledge often fail in modern long-term autonomy long-distance travel scenarios where map accumulation errors become significant. To address these limitations of map-based navigation, this paper is the first to explore mapless navigation in the embodied AI field, in particular, to utilize object-goal navigation (commonly abbreviated as ON, ObjNav, or OGN) techniques that efficiently explore target objects without using such a prior map. Specifically, in this work, we start from an off-the-shelf mapless ON planner, extend it to utilize a prior map, and further show that the performance in long-distance ALC (LD-ALC) can be maximized by minimizing ``ALC loss" and ``ON loss". This study highlights a simple and effective approach, called ALC-ON (ALCON), to accelerate the progress of challenging long-distance ALC technology by leveraging the growing frontier-guided, data-driven, and LLM-guided ON technologies.
DRIP: Discriminative Rotation-Invariant Pole Landmark Descriptor for 3D LiDAR Localization
Jun 17, 2024In 3D LiDAR-based robot self-localization, pole-like landmarks are gaining popularity as lightweight and discriminative landmarks. This work introduces a novel approach called "discriminative rotation-invariant poles," which enhances the discriminability of pole-like landmarks while maintaining their lightweight nature. Unlike conventional methods that model a pole landmark as a 3D line segment perpendicular to the ground, we propose a simple yet powerful approach that includes not only the line segment's main body but also its surrounding local region of interest (ROI) as part of the pole landmark. Specifically, we describe the appearance, geometry, and semantic features within this ROI to improve the discriminability of the pole landmark. Since such pole landmarks are no longer rotation-invariant, we introduce a novel rotation-invariant convolutional neural network that automatically and efficiently extracts rotation-invariant features from input point clouds for recognition. Furthermore, we train a pole dictionary through unsupervised learning and use it to compress poles into compact pole words, thereby significantly reducing real-time costs while maintaining optimal self-localization performance. Monte Carlo localization experiments using publicly available NCLT dataset demonstrate that the proposed method improves a state-of-the-art pole-based localization framework.