 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic-Dark SLAM: RGB-Thermal Cooperative Robot Vision Strategy for Multi-Person Tracking in Both Well-Lit and Low-Light Scenes
Mar 17, 2025


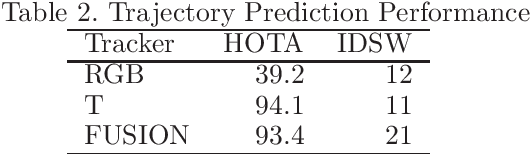
In robot vision, thermal cameras have significant potential for recognizing humans even in complete darkness. However, their application to multi-person tracking (MPT) has lagged due to data scarcity and difficulties in individual identification. In this study, we propose a cooperative MPT system that utilizes co-located RGB and thermal cameras, using pseudo-annotations (bounding boxes + person IDs) to train RGB and T trackers. Evaluation experiments demonstrate that the T tracker achieves remarkable performance in both bright and dark scenes. Furthermore, results suggest that a tracker-switching approach using a binary brightness classifier is more suitable than a tracker-fusion approach for information integration. This study marks a crucial first step toward ``Dynamic-Dark SLAM," enabling effective recognition, understanding, and reconstruction of individuals, occluding objects, and traversable areas in dynamic environments, both bright and dark.
Continual Multi-Robot Learning from Black-Box Visual Place Recognition Models
Mar 04, 2025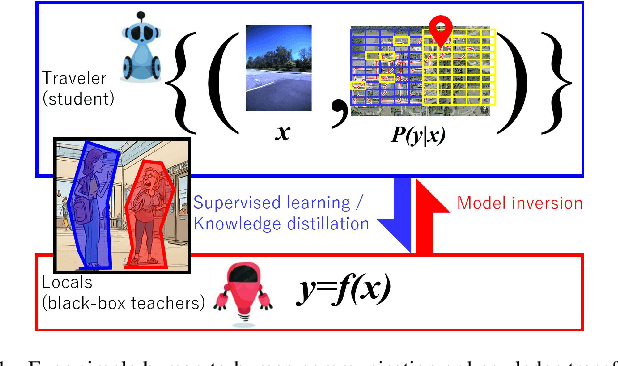

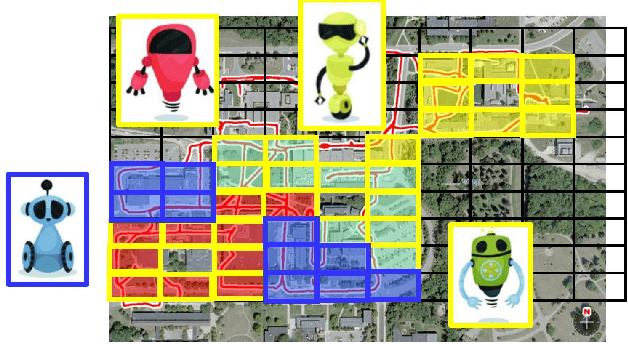
In the context of visual place recognition (VPR), continual learning (CL) techniques offer significant potential for avoiding catastrophic forgetting when learning new places. However, existing CL methods often focus on knowledge transfer from a known model to a new one, overlooking the existence of unknown black-box models. We explore a novel multi-robot CL approach that enables knowledge transfer from black-box VPR models (teachers), such as those of local robots encountered by traveler robots (students) in unknown environments. Specifically, we introduce Membership Inference Attack, or MIA, the only major privacy attack applicable to black-box models, and leverage it to reconstruct pseudo training sets, which serve as the key knowledge to be exchanged between robots, from black-box VPR models. Furthermore, we aim to overcome the inherently low sampling efficiency of MIA by leveraging insights on place class prediction distribution and un-learned class detection imported from the VPR literature as a prior distribution. We also analyze both the individual effects of these methods and their combined impact. Experimental results demonstrate that our black-box MIA (BB-MIA) approach is remarkably powerful despite its simplicity, significantly enhancing the VPR capability of lower-performing robots through brief communication with other robots. This study contributes to optimizing knowledge sharing between robots in VPR and enhancing autonomy in open-world environments with multi-robot systems that are fault-tolerant and scalable.
Walking = Traversable? : Traversability Prediction via Multiple Human Object Tracking under Occlusion
Sep 30, 2023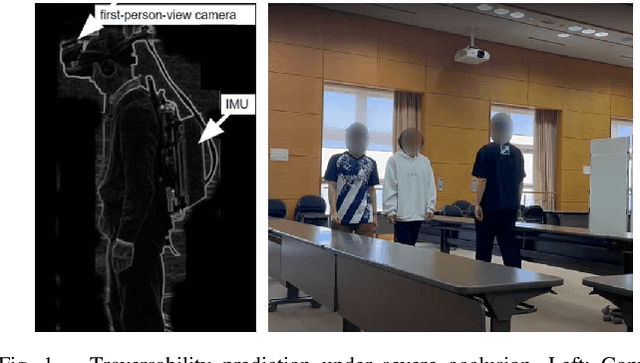
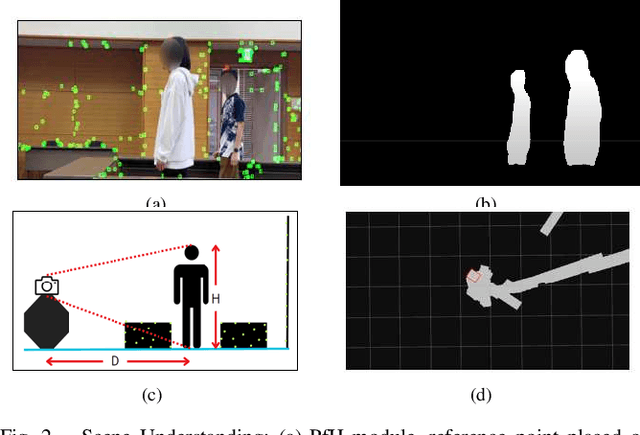

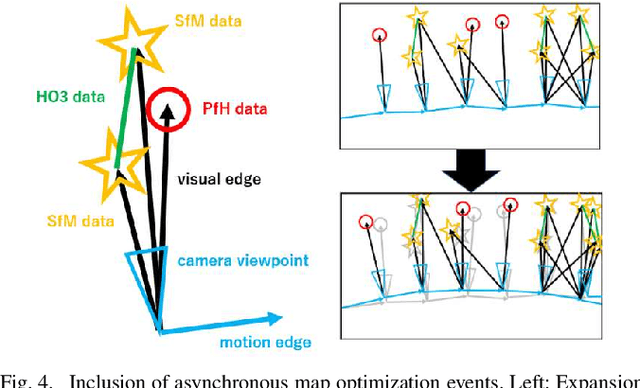
The emerging ``Floor plan from human trails (PfH)" technique has great potential for improving indoor robot navigation by predicting the traversability of occluded floors. This study presents an innovative approach that replaces first-person-view sensors with a third-person-view monocular camera mounted on the observer robot. This approach can gather measurements from multiple humans, expanding its range of applications. The key idea is to use two types of trackers, SLAM and MOT, to monitor stationary objects and moving humans and assess their interactions. This method achieves stable predictions of traversability even in challenging visual scenarios, such as occlusions, nonlinear perspectives, depth uncertainty, and intersections involving multiple humans. Additionally, we extend map quality metrics to apply to traversability maps, facilitating future research. We validate our proposed method through fusion and comparison with established techniques.
Active Robot Vision for Distant Object Change Detection: A Lightweight Training Simulator Inspired by Multi-Armed Bandits
Jul 26, 2023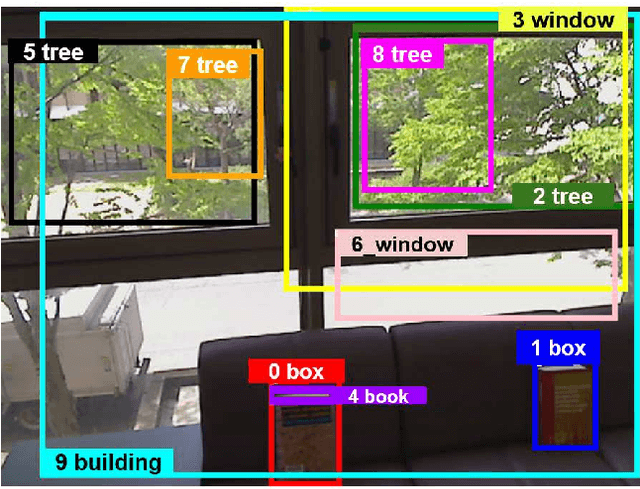
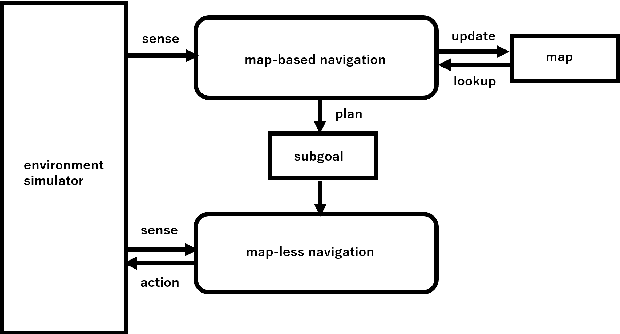
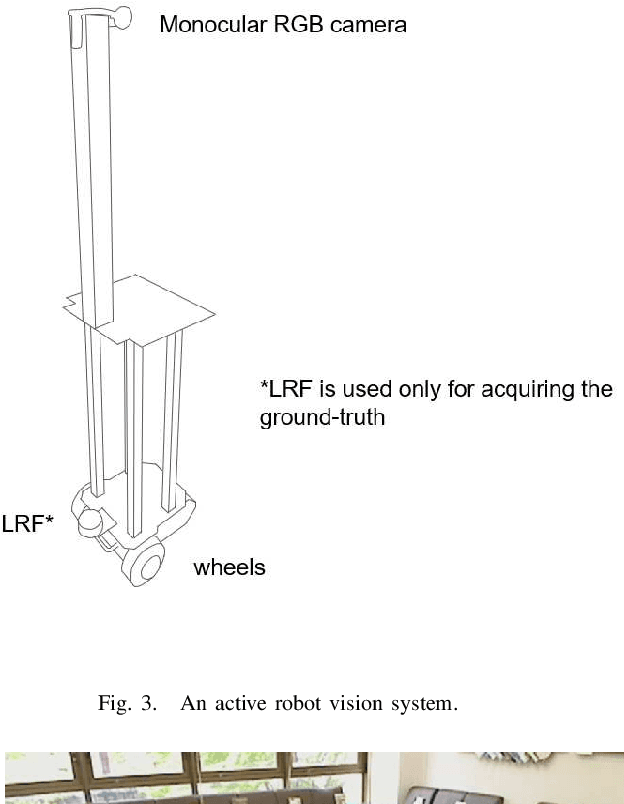
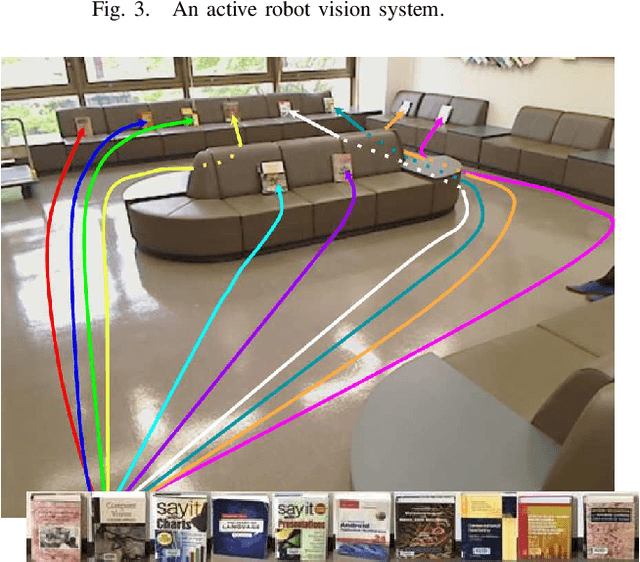
In ground-view object change detection, the recently emerging map-less navigation has great potential as a means of navigating a robot to distantly detected objects and identifying their changing states (appear/disappear/no-change) with high resolution imagery. However, the brute-force naive action strategy of navigating to every distant object requires huge sense/plan/action costs proportional to the number of objects. In this work, we study this new problem of ``Which distant objects should be prioritized for map-less navigation?" and in order to speed up the R{\&}D cycle, propose a highly-simplified approach that is easy to implement and easy to extend. In our approach, a new layer called map-based navigation is added on top of the map-less navigation, which constitutes a hierarchical planner. First, a dataset consisting of $N$ view sequences is acquired by a real robot via map-less navigation. Then, an environment simulator was built to simulate a simple action planning problem: ``Which view sequence should the robot select next?". Then, a solver was built inspired by the analogy to the multi-armed bandit problem: ``Which arm should the player select next?". Finally, the effectiveness of the proposed framework was verified using the semantically non-trivial scenario ``sofa as bookshelf".