 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-view Self-localization from Synthesized Scene-graphs
Oct 24, 2023Cross-view self-localization is a challenging scenario of visual place recognition in which database images are provided from sparse viewpoints. Recently, an approach for synthesizing database images from unseen viewpoints using NeRF (Neural Radiance Fields) technology has emerged with impressive performance. However, synthesized images provided by these techniques are often of lower quality than the original images, and furthermore they significantly increase the storage cost of the database. In this study, we explore a new hybrid scene model that combines the advantages of view-invariant appearance features computed from raw images and view-dependent spatial-semantic features computed from synthesized images. These two types of features are then fused into scene graphs, and compressively learned and recognized by a graph neural network. The effectiveness of the proposed method was verified using a novel cross-view self-localization dataset with many unseen views generated using a photorealistic Habitat simulator.
Active Robot Vision for Distant Object Change Detection: A Lightweight Training Simulator Inspired by Multi-Armed Bandits
Jul 26, 2023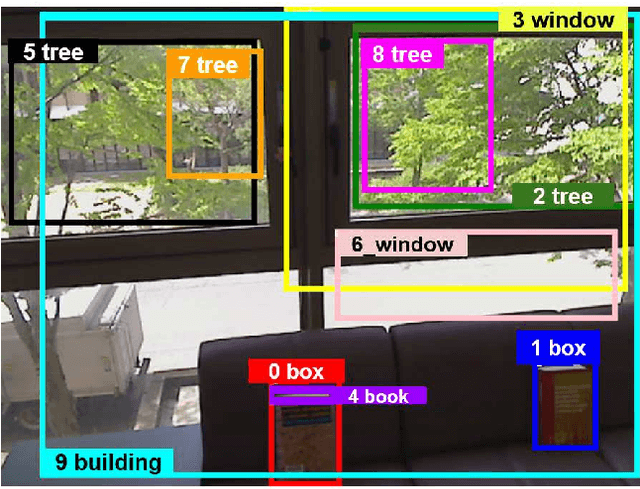
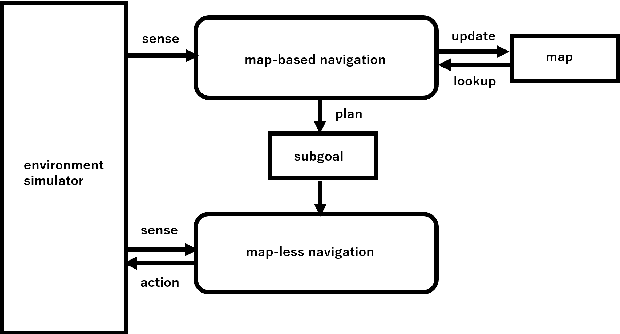
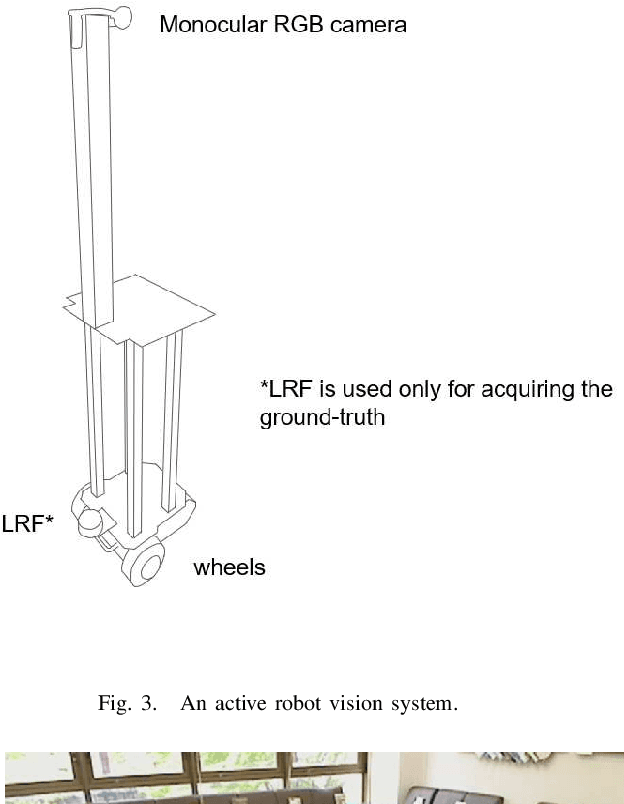
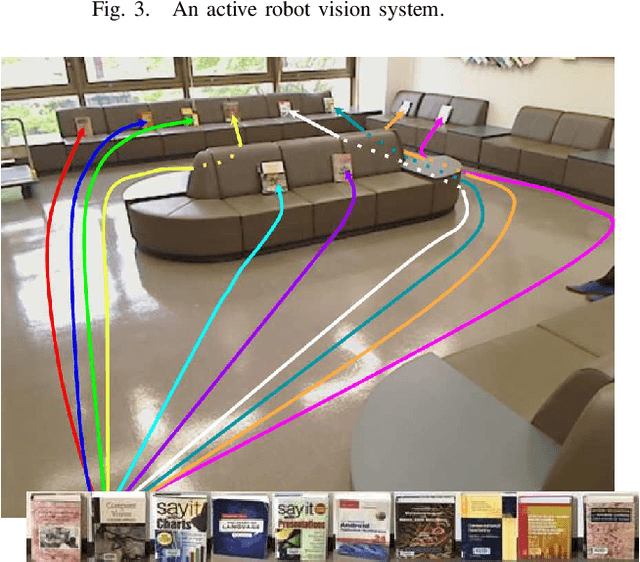
In ground-view object change detection, the recently emerging map-less navigation has great potential as a means of navigating a robot to distantly detected objects and identifying their changing states (appear/disappear/no-change) with high resolution imagery. However, the brute-force naive action strategy of navigating to every distant object requires huge sense/plan/action costs proportional to the number of objects. In this work, we study this new problem of ``Which distant objects should be prioritized for map-less navigation?" and in order to speed up the R{\&}D cycle, propose a highly-simplified approach that is easy to implement and easy to extend. In our approach, a new layer called map-based navigation is added on top of the map-less navigation, which constitutes a hierarchical planner. First, a dataset consisting of $N$ view sequences is acquired by a real robot via map-less navigation. Then, an environment simulator was built to simulate a simple action planning problem: ``Which view sequence should the robot select next?". Then, a solver was built inspired by the analogy to the multi-armed bandit problem: ``Which arm should the player select next?". Finally, the effectiveness of the proposed framework was verified using the semantically non-trivial scenario ``sofa as bookshelf".
Active Semantic Localization with Graph Neural Embedding
May 15, 2023Semantic localization, i.e., robot self-localization with semantic image modality, is critical in recently emerging embodied AI applications such as point-goal navigation, object-goal navigation and vision language navigation. However, most existing works on semantic localization focus on passive vision tasks without viewpoint planning, or rely on additional rich modalities (e.g., depth measurements). Thus, the problem is largely unsolved. In this work, we explore a lightweight, entirely CPU-based, domain-adaptive semantic localization framework, called graph neural localizer.Our approach is inspired by two recently emerging technologies: (1) Scene graph, which combines the viewpoint- and appearance- invariance of local and global features; (2) Graph neural network, which enables direct learning/recognition of graph data (i.e., non-vector data). Specifically, a graph convolutional neural network is first trained as a scene graph classifier for passive vision, and then its knowledge is transferred to a reinforcement-learning planner for active vision. Experiments on two scenarios, self-supervised learning and unsupervised domain adaptation, using a photo-realistic Habitat simulator validate the effectiveness of the proposed method.
Transferring ConvNet Features from Passive to Active Robot Self-Localization: The Use of Ego-Centric and World-Centric Views
Apr 22, 2022
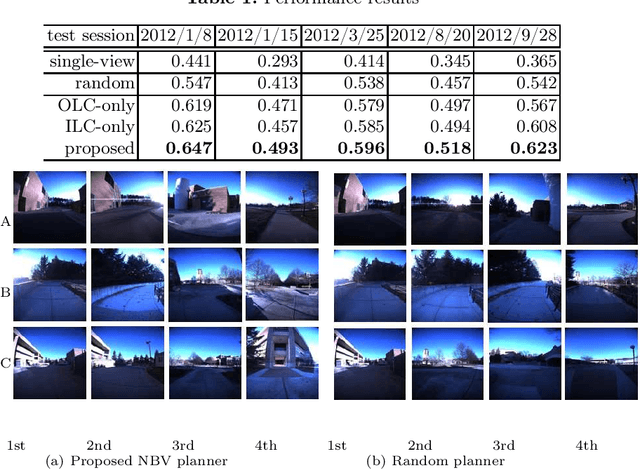
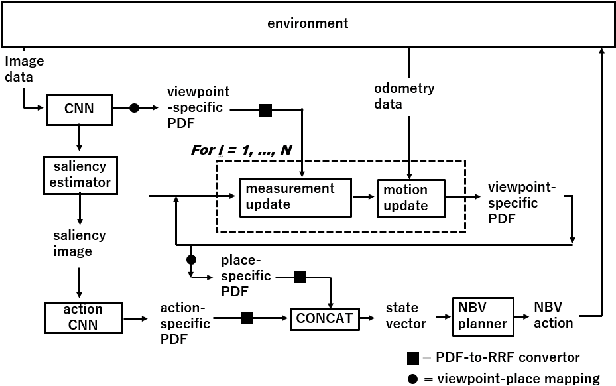
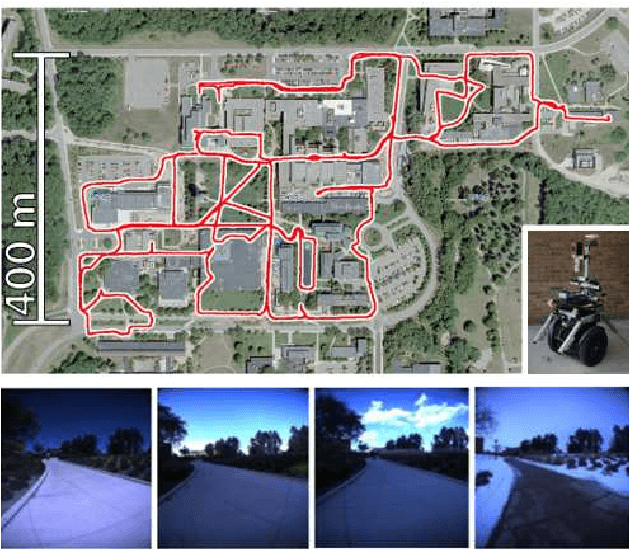
The training of a next-best-view (NBV) planner for visual place recognition (VPR) is a fundamentally important task in autonomous robot navigation, for which a typical approach is the use of visual experiences that are collected in the target domain as training data. However, the collection of a wide variety of visual experiences in everyday navigation is costly and prohibitive for real-time robotic applications. We address this issue by employing a novel {\it domain-invariant} NBV planner. A standard VPR subsystem based on a convolutional neural network (CNN) is assumed to be available, and its domain-invariant state recognition ability is proposed to be transferred to train the domain-invariant NBV planner. Specifically, we divide the visual cues that are available from the CNN model into two types: the output layer cue (OLC) and intermediate layer cue (ILC). The OLC is available at the output layer of the CNN model and aims to estimate the state of the robot (e.g., the robot viewpoint) with respect to the world-centric view coordinate system. The ILC is available within the middle layers of the CNN model as a high-level description of the visual content (e.g., a saliency image) with respect to the ego-centric view. In our framework, the ILC and OLC are mapped to a state vector and subsequently used to train a multiview NBV planner via deep reinforcement learning. Experiments using the public NCLT dataset validate the effectiveness of the proposed method.
Minimum Cost Multicuts for Incorrect Landmark Edge Detection in Pose-graph SLAM
Mar 06, 2022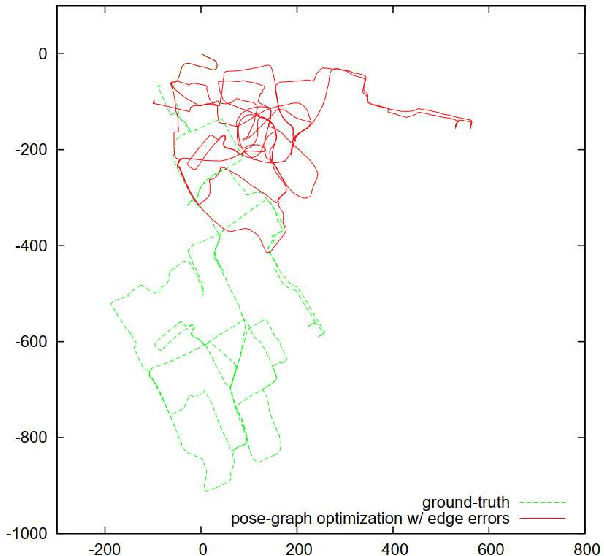
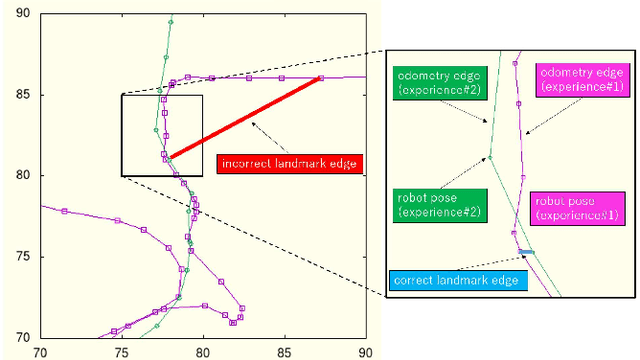
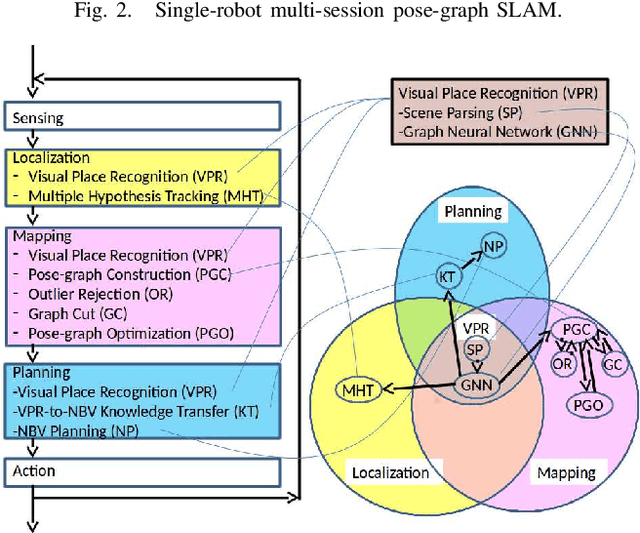
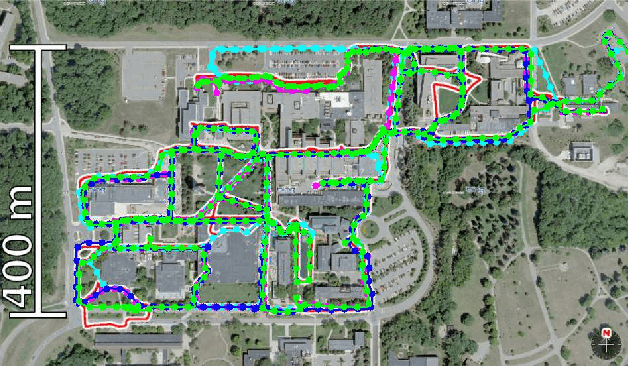
Pose-graph SLAM is the de facto standard framework for constructing large-scale maps from multi-session experiences of relative observations and motions during visual robot navigation. It has received increasing attention in the context of recent advanced SLAM frameworks such as graph neural SLAM. One remaining challenge is landmark misrecognition errors (i.e., incorrect landmark edges) that can have catastrophic effects on the inferred pose-graph map. In this study, we present comprehensive criteria to maximize global consistency in the pose graph using a new robust graph cut technique. Our key idea is to formulate the problem as a minimum-cost multi-cut that enables us to optimize not only landmark correspondences but also the number of landmarks while allowing for a varying number of landmarks. This makes our proposed approach invariant against the type of landmark measurement, graph topology, and metric information, such as the speed of the robot motion. The proposed graph cut technique was integrated into a practical SLAM framework and verified experimentally using the public NCLT dataset.
S3G-ARM: Highly Compressive Visual Self-localization from Sequential Semantic Scene Graph Using Absolute and Relative Measurements
Sep 09, 2021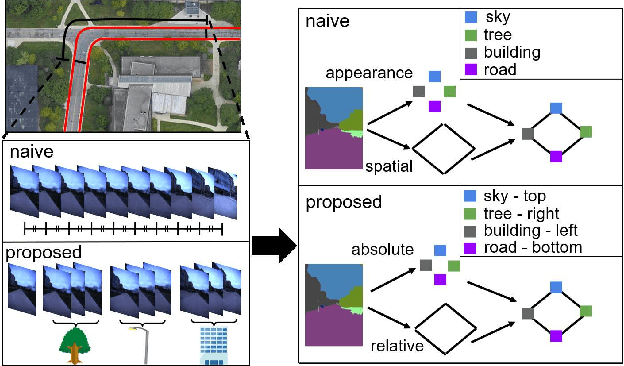
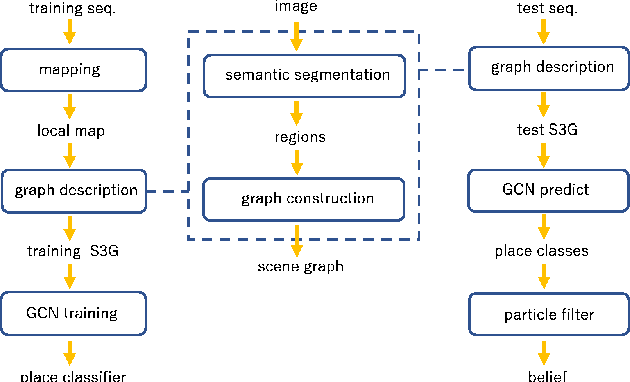
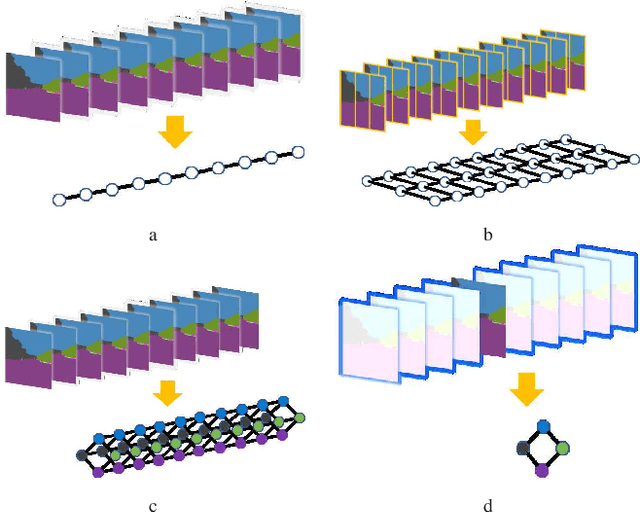
In this paper, we address the problem of image sequence-based self-localization (ISS) from a new highly compressive scene representation called sequential semantic scene graph (S3G). Recent developments in deep graph convolutional neural networks (GCNs) have enabled a highly compressive visual place classifier (VPC) that can use a scene graph as the input modality. However, in such a highly compressive application, the amount of information lost in the image-to-graph mapping is significant and can damage the classification performance. To address this issue, we propose a pair of similarity-preserving mappings, image-to-nodes and image-to-edges, such that the nodes and edges act as absolute and relative features, respectively, that complement each other. Moreover, the proposed GCN-VPC is applied to a new task of viewpoint planning (VP) of the query image sequence, which contributes to further improvement in the VPC performance. Experiments using the public NCLT dataset validated the effectiveness of the proposed method.