 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Semantic Localization with Graph Neural Embedding
May 15, 2023Semantic localization, i.e., robot self-localization with semantic image modality, is critical in recently emerging embodied AI applications such as point-goal navigation, object-goal navigation and vision language navigation. However, most existing works on semantic localization focus on passive vision tasks without viewpoint planning, or rely on additional rich modalities (e.g., depth measurements). Thus, the problem is largely unsolved. In this work, we explore a lightweight, entirely CPU-based, domain-adaptive semantic localization framework, called graph neural localizer.Our approach is inspired by two recently emerging technologies: (1) Scene graph, which combines the viewpoint- and appearance- invariance of local and global features; (2) Graph neural network, which enables direct learning/recognition of graph data (i.e., non-vector data). Specifically, a graph convolutional neural network is first trained as a scene graph classifier for passive vision, and then its knowledge is transferred to a reinforcement-learning planner for active vision. Experiments on two scenarios, self-supervised learning and unsupervised domain adaptation, using a photo-realistic Habitat simulator validate the effectiveness of the proposed method.
Transferring ConvNet Features from Passive to Active Robot Self-Localization: The Use of Ego-Centric and World-Centric Views
Apr 22, 2022
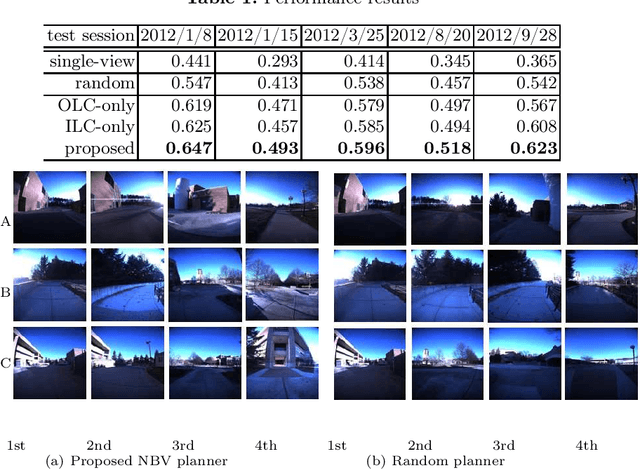
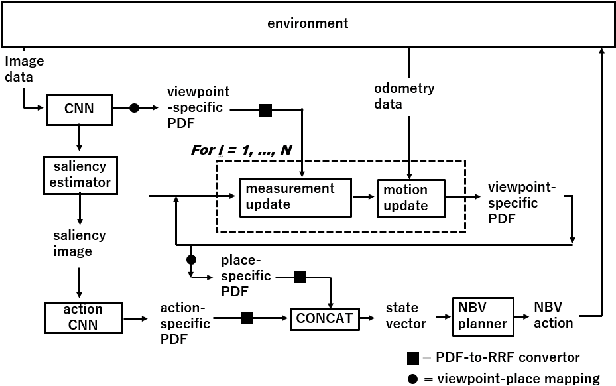
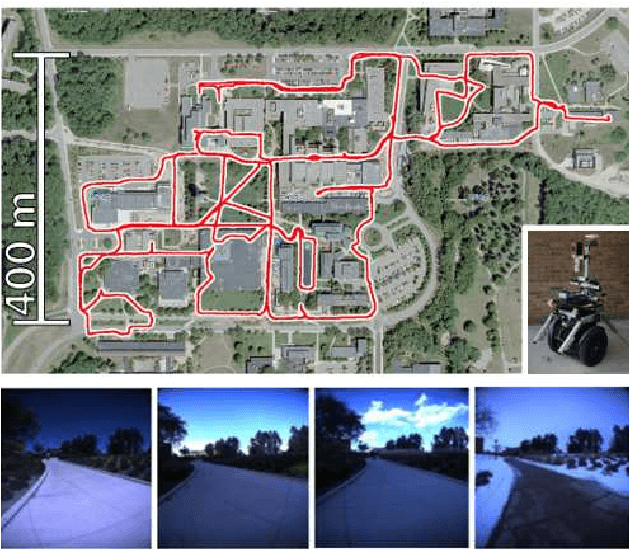
The training of a next-best-view (NBV) planner for visual place recognition (VPR) is a fundamentally important task in autonomous robot navigation, for which a typical approach is the use of visual experiences that are collected in the target domain as training data. However, the collection of a wide variety of visual experiences in everyday navigation is costly and prohibitive for real-time robotic applications. We address this issue by employing a novel {\it domain-invariant} NBV planner. A standard VPR subsystem based on a convolutional neural network (CNN) is assumed to be available, and its domain-invariant state recognition ability is proposed to be transferred to train the domain-invariant NBV planner. Specifically, we divide the visual cues that are available from the CNN model into two types: the output layer cue (OLC) and intermediate layer cue (ILC). The OLC is available at the output layer of the CNN model and aims to estimate the state of the robot (e.g., the robot viewpoint) with respect to the world-centric view coordinate system. The ILC is available within the middle layers of the CNN model as a high-level description of the visual content (e.g., a saliency image) with respect to the ego-centric view. In our framework, the ILC and OLC are mapped to a state vector and subsequently used to train a multiview NBV planner via deep reinforcement learning. Experiments using the public NCLT dataset validate the effectiveness of the proposed method.
S3G-ARM: Highly Compressive Visual Self-localization from Sequential Semantic Scene Graph Using Absolute and Relative Measurements
Sep 09, 2021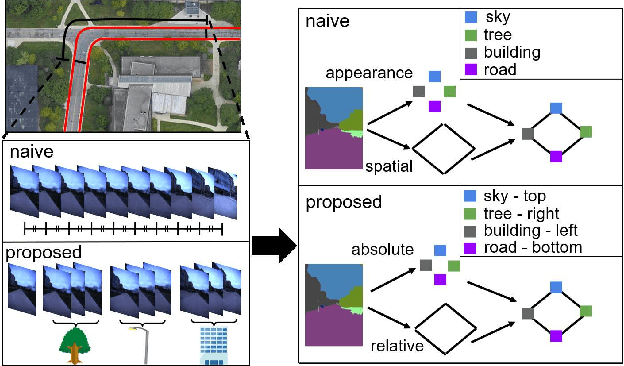
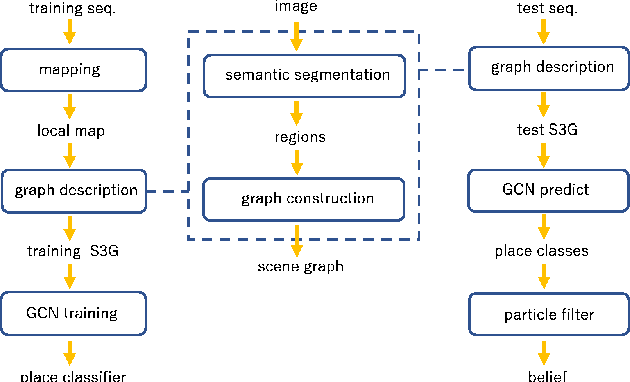
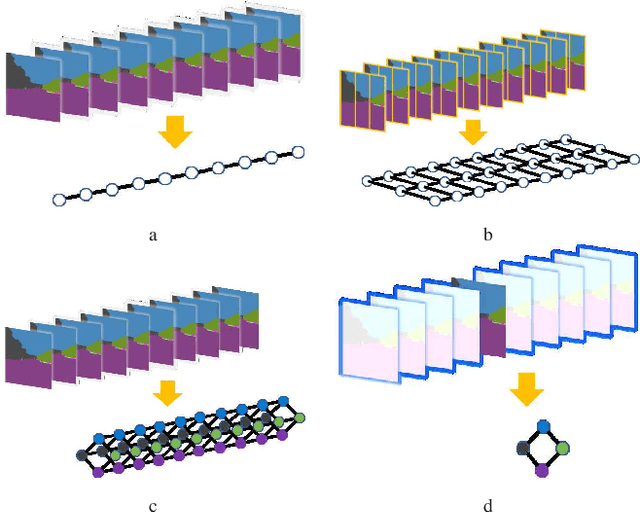
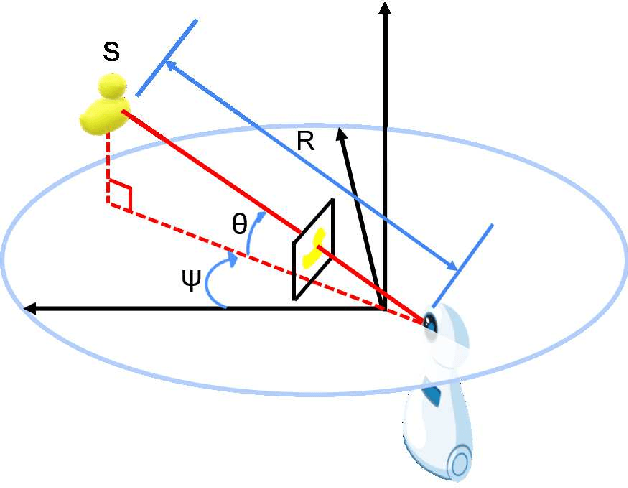
In this paper, we address the problem of image sequence-based self-localization (ISS) from a new highly compressive scene representation called sequential semantic scene graph (S3G). Recent developments in deep graph convolutional neural networks (GCNs) have enabled a highly compressive visual place classifier (VPC) that can use a scene graph as the input modality. However, in such a highly compressive application, the amount of information lost in the image-to-graph mapping is significant and can damage the classification performance. To address this issue, we propose a pair of similarity-preserving mappings, image-to-nodes and image-to-edges, such that the nodes and edges act as absolute and relative features, respectively, that complement each other. Moreover, the proposed GCN-VPC is applied to a new task of viewpoint planning (VP) of the query image sequence, which contributes to further improvement in the VPC performance. Experiments using the public NCLT dataset validated the effectiveness of the proposed method.