 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS3G-ARM: Highly Compressive Visual Self-localization from Sequential Semantic Scene Graph Using Absolute and Relative Measurements
Paper and Code
Sep 09, 2021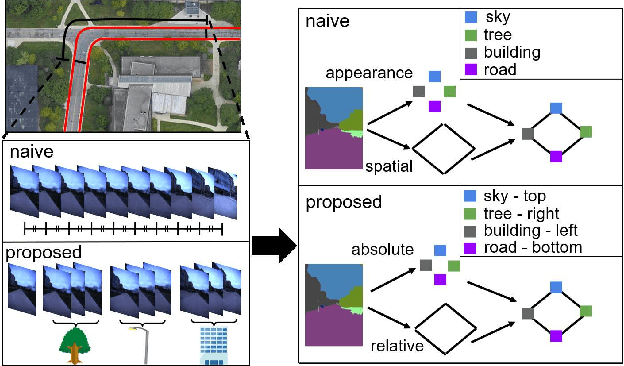
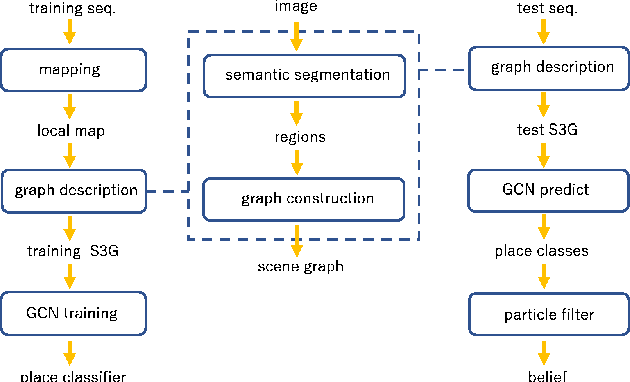
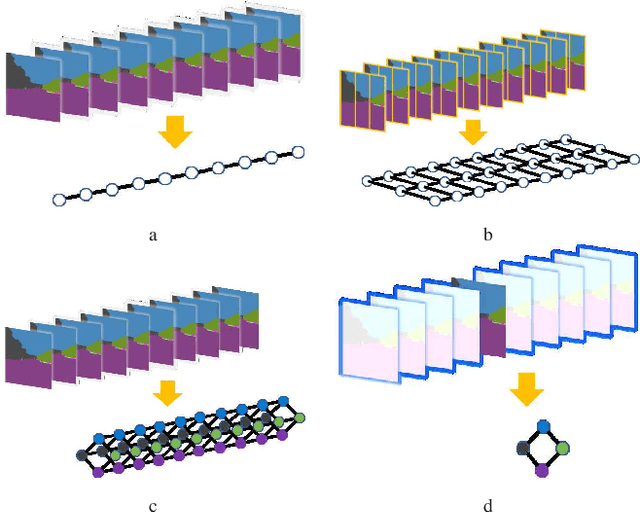
In this paper, we address the problem of image sequence-based self-localization (ISS) from a new highly compressive scene representation called sequential semantic scene graph (S3G). Recent developments in deep graph convolutional neural networks (GCNs) have enabled a highly compressive visual place classifier (VPC) that can use a scene graph as the input modality. However, in such a highly compressive application, the amount of information lost in the image-to-graph mapping is significant and can damage the classification performance. To address this issue, we propose a pair of similarity-preserving mappings, image-to-nodes and image-to-edges, such that the nodes and edges act as absolute and relative features, respectively, that complement each other. Moreover, the proposed GCN-VPC is applied to a new task of viewpoint planning (VP) of the query image sequence, which contributes to further improvement in the VPC performance. Experiments using the public NCLT dataset validated the effectiveness of the proposed method.