 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferring ConvNet Features from Passive to Active Robot Self-Localization: The Use of Ego-Centric and World-Centric Views
Apr 22, 2022
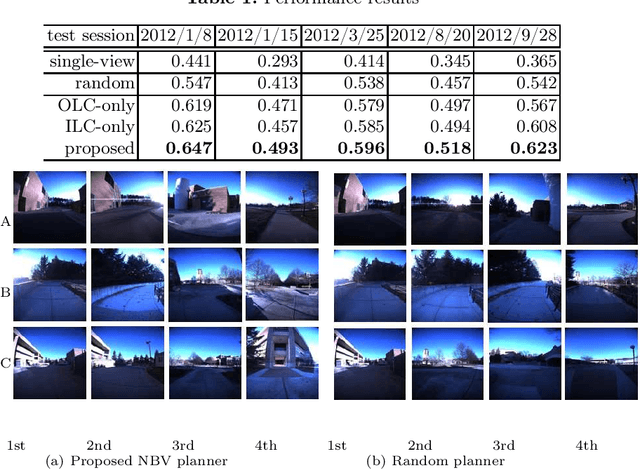
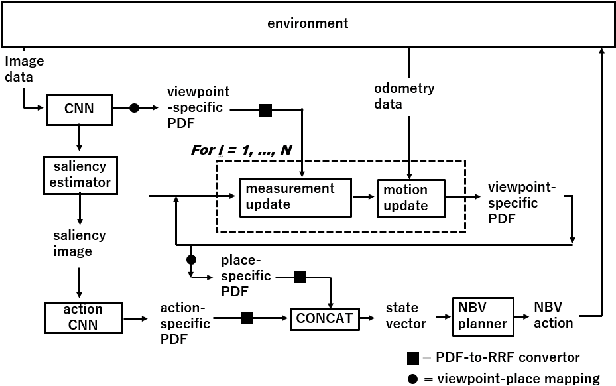
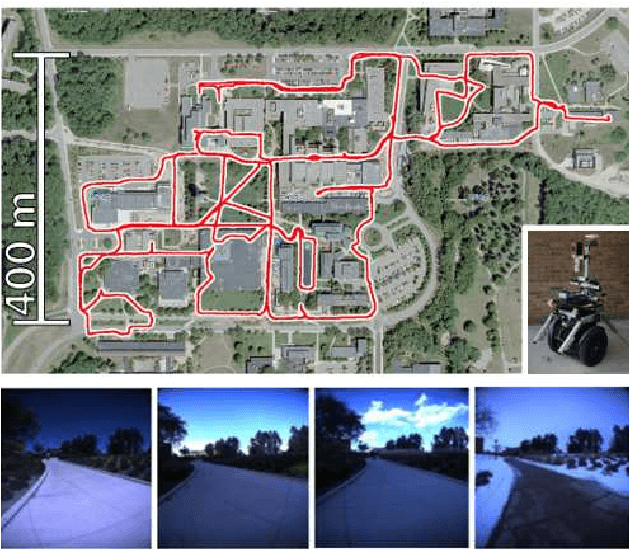
The training of a next-best-view (NBV) planner for visual place recognition (VPR) is a fundamentally important task in autonomous robot navigation, for which a typical approach is the use of visual experiences that are collected in the target domain as training data. However, the collection of a wide variety of visual experiences in everyday navigation is costly and prohibitive for real-time robotic applications. We address this issue by employing a novel {\it domain-invariant} NBV planner. A standard VPR subsystem based on a convolutional neural network (CNN) is assumed to be available, and its domain-invariant state recognition ability is proposed to be transferred to train the domain-invariant NBV planner. Specifically, we divide the visual cues that are available from the CNN model into two types: the output layer cue (OLC) and intermediate layer cue (ILC). The OLC is available at the output layer of the CNN model and aims to estimate the state of the robot (e.g., the robot viewpoint) with respect to the world-centric view coordinate system. The ILC is available within the middle layers of the CNN model as a high-level description of the visual content (e.g., a saliency image) with respect to the ego-centric view. In our framework, the ILC and OLC are mapped to a state vector and subsequently used to train a multiview NBV planner via deep reinforcement learning. Experiments using the public NCLT dataset validate the effectiveness of the proposed method.