 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOON: Multi-Objective Optimization-Driven Object-Goal Navigation Using a Variable-Horizon Set-Orienteering Planner
May 19, 2025Object-goal navigation (ON) enables autonomous robots to locate and reach user-specified objects in previously unknown environments, offering promising applications in domains such as assistive care and disaster response. Existing ON methods -- including training-free approaches, reinforcement learning, and zero-shot planners -- generally depend on active exploration to identify landmark objects (e.g., kitchens or desks), followed by navigation toward semantically related targets (e.g., a specific mug). However, these methods often lack strategic planning and do not adequately address trade-offs among multiple objectives. To overcome these challenges, we propose a novel framework that formulates ON as a multi-objective optimization problem (MOO), balancing frontier-based knowledge exploration with knowledge exploitation over previously observed landmarks; we call this framework MOON (MOO-driven ON). We implement a prototype MOON system that integrates three key components: (1) building on QOM [IROS05], a classical ON system that compactly and discriminatively encodes landmarks based on their semantic relevance to the target; (2) integrating StructNav [RSS23], a recently proposed training-free planner, to enhance the navigation pipeline; and (3) introducing a variable-horizon set orienteering problem formulation to enable global optimization over both exploration and exploitation strategies. This work represents an important first step toward developing globally optimized, next-generation object-goal navigation systems.
LGR: LLM-Guided Ranking of Frontiers for Object Goal Navigation
Mar 26, 2025Object Goal Navigation (OGN) is a fundamental task for robots and AI, with key applications such as mobile robot image databases (MRID). In particular, mapless OGN is essential in scenarios involving unknown or dynamic environments. This study aims to enhance recent modular mapless OGN systems by leveraging the commonsense reasoning capabilities of large language models (LLMs). Specifically, we address the challenge of determining the visiting order in frontier-based exploration by framing it as a frontier ranking problem. Our approach is grounded in recent findings that, while LLMs cannot determine the absolute value of a frontier, they excel at evaluating the relative value between multiple frontiers viewed within a single image using the view image as context. We dynamically manage the frontier list by adding and removing elements, using an LLM as a ranking model. The ranking results are represented as reciprocal rank vectors, which are ideal for multi-view, multi-query information fusion. We validate the effectiveness of our method through evaluations in Habitat-Sim.
ON as ALC: Active Loop Closing Object Goal Navigation
Dec 16, 2024In simultaneous localization and mapping, active loop closing (ALC) is an active vision problem that aims to visually guide a robot to maximize the chances of revisiting previously visited points, thereby resetting the drift errors accumulated in the incrementally built map during travel. However, current mainstream navigation strategies that leverage such incomplete maps as workspace prior knowledge often fail in modern long-term autonomy long-distance travel scenarios where map accumulation errors become significant. To address these limitations of map-based navigation, this paper is the first to explore mapless navigation in the embodied AI field, in particular, to utilize object-goal navigation (commonly abbreviated as ON, ObjNav, or OGN) techniques that efficiently explore target objects without using such a prior map. Specifically, in this work, we start from an off-the-shelf mapless ON planner, extend it to utilize a prior map, and further show that the performance in long-distance ALC (LD-ALC) can be maximized by minimizing ``ALC loss" and ``ON loss". This study highlights a simple and effective approach, called ALC-ON (ALCON), to accelerate the progress of challenging long-distance ALC technology by leveraging the growing frontier-guided, data-driven, and LLM-guided ON technologies.
Active Robot Vision for Distant Object Change Detection: A Lightweight Training Simulator Inspired by Multi-Armed Bandits
Jul 26, 2023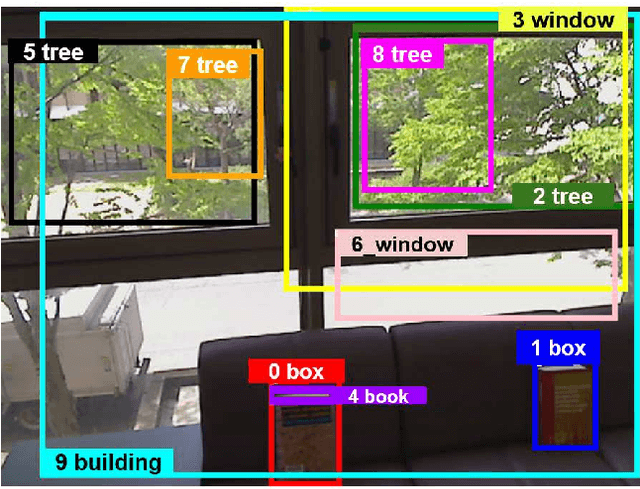
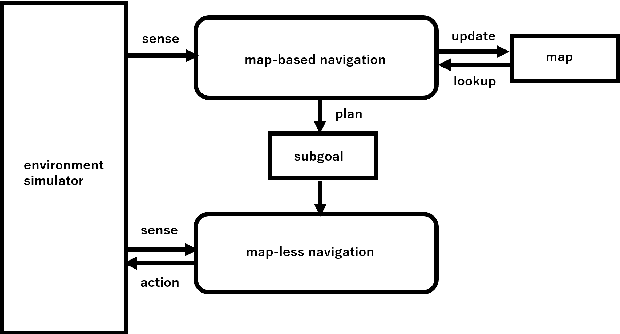
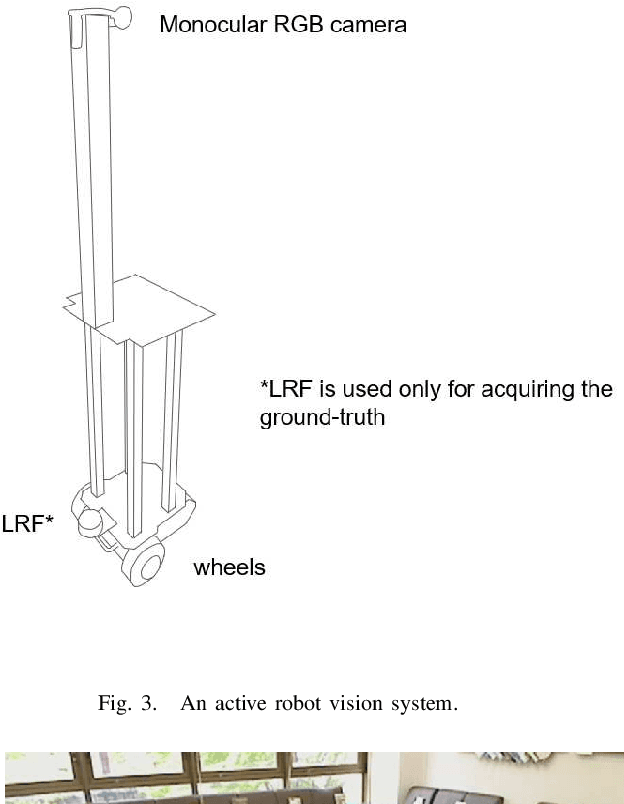
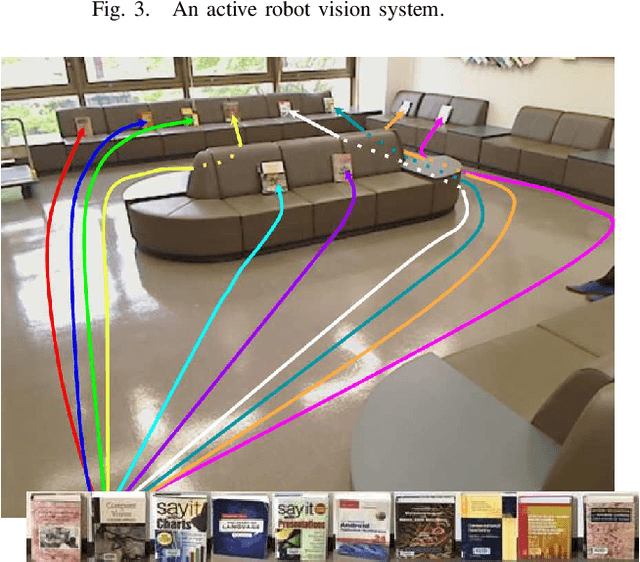
In ground-view object change detection, the recently emerging map-less navigation has great potential as a means of navigating a robot to distantly detected objects and identifying their changing states (appear/disappear/no-change) with high resolution imagery. However, the brute-force naive action strategy of navigating to every distant object requires huge sense/plan/action costs proportional to the number of objects. In this work, we study this new problem of ``Which distant objects should be prioritized for map-less navigation?" and in order to speed up the R{\&}D cycle, propose a highly-simplified approach that is easy to implement and easy to extend. In our approach, a new layer called map-based navigation is added on top of the map-less navigation, which constitutes a hierarchical planner. First, a dataset consisting of $N$ view sequences is acquired by a real robot via map-less navigation. Then, an environment simulator was built to simulate a simple action planning problem: ``Which view sequence should the robot select next?". Then, a solver was built inspired by the analogy to the multi-armed bandit problem: ``Which arm should the player select next?". Finally, the effectiveness of the proposed framework was verified using the semantically non-trivial scenario ``sofa as bookshelf".