 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUse of First and Third Person Views for Deep Intersection Classification
Paper and Code
Jan 22, 2019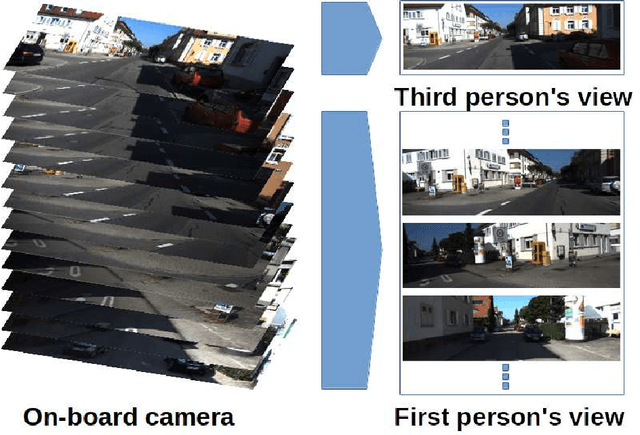
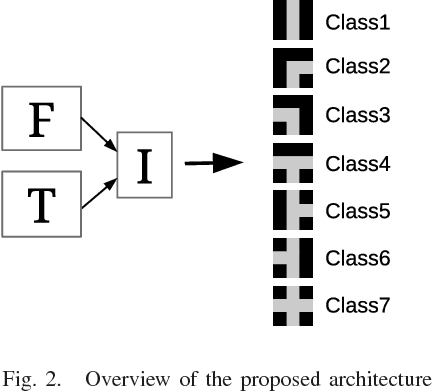
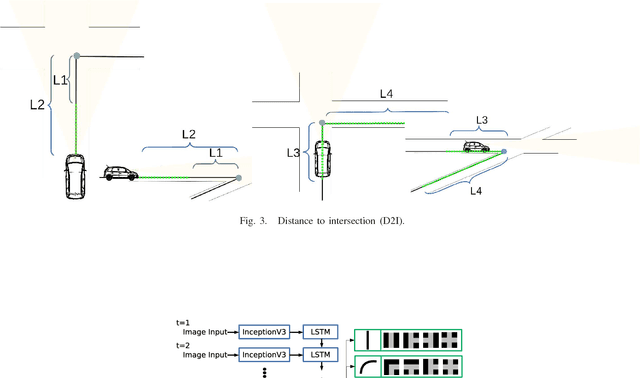
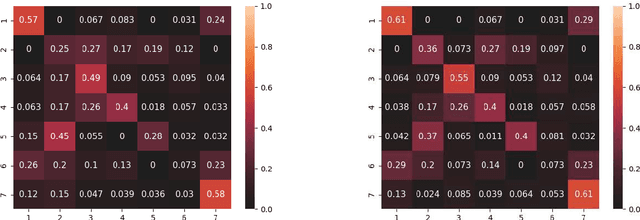
We explore the problem of intersection classification using monocular on-board passive vision, with the goal of classifying traffic scenes with respect to road topology. We divide the existing approaches into two broad categories according to the type of input data: (a) first person vision (FPV) approaches, which use an egocentric view sequence as the intersection is passed; and (b) third person vision (TPV) approaches, which use a single view immediately before entering the intersection. The FPV and TPV approaches each have advantages and disadvantages. Therefore, we aim to combine them into a unified deep learning framework. Experimental results show that the proposed FPV-TPV scheme outperforms previous methods and only requires minimal FPV/TPV measurements.