 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking the Fusion Strategy of Multi-reference Face Reenactment
Paper and Code
Feb 22, 2022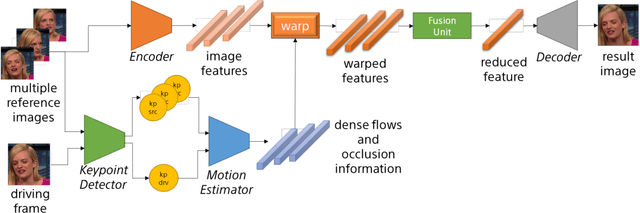



In recent advances of deep generative models, face reenactment -manipulating and controlling human face, including their head movement-has drawn much attention for its wide range of applicability. Despite its strong expressiveness, it is inevitable that the models fail to reconstruct or accurately generate unseen side of the face of a given single reference image. Most of existing methods alleviate this problem by learning appearances of human faces from large amount of data and generate realistic texture at inference time. Rather than completely relying on what generative models learn, we show that simple extension by using multiple reference images significantly improves generation quality. We show this by 1) conducting the reconstruction task on publicly available dataset, 2) conducting facial motion transfer on our original dataset which consists of multi-person's head movement video sequences, and 3) using a newly proposed evaluation metric to validate that our method achieves better quantitative results.