 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to Use Future Information in Simultaneous Translation
Paper and Code
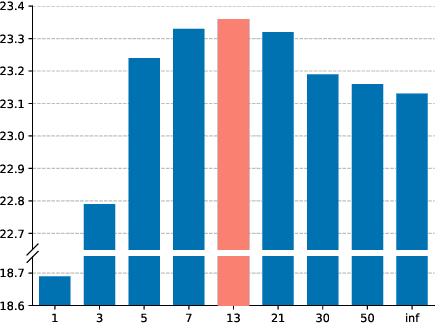
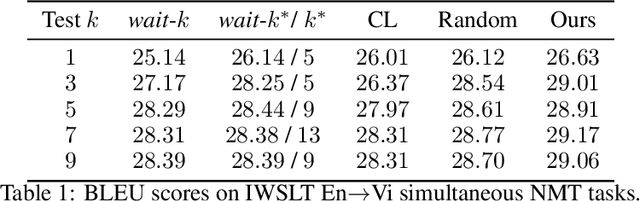
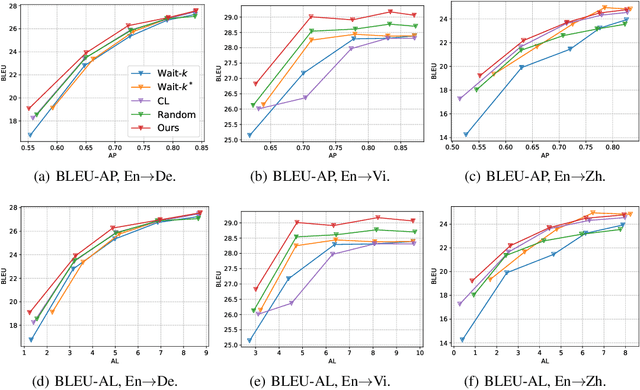

Simultaneous neural machine translation (briefly, NMT) has attracted much attention recently. In contrast to standard NMT, where the NMT system can utilize the full input sentence, simultaneous NMT is formulated as a prefix-to-prefix problem, where the system can only utilize the prefix of the input sentence and more uncertainty is introduced to decoding. Wait-$k$ is a simple yet effective strategy for simultaneous NMT, where the decoder generates the output sequence $k$ words behind the input words. We observed that training simultaneous NMT systems with future information (i.e., trained with a larger $k$) generally outperforms the standard ones (i.e., trained with the given $k$). Based on this observation, we propose a framework that automatically learns how much future information to use in training for simultaneous NMT. We first build a series of tasks where each one is associated with a different $k$, and then learn a model on these tasks guided by a controller. The controller is jointly trained with the translation model through bi-level optimization. We conduct experiments on four datasets to demonstrate the effectiveness of our method.