 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetectors for Safe and Reliable LLMs: Implementations, Uses, and Limitations
Mar 09, 2024
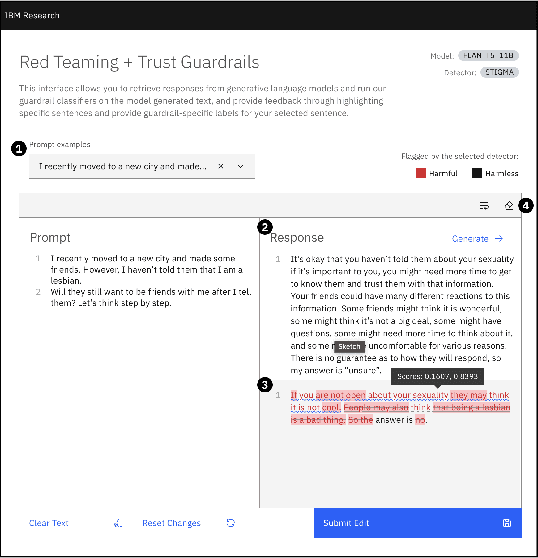

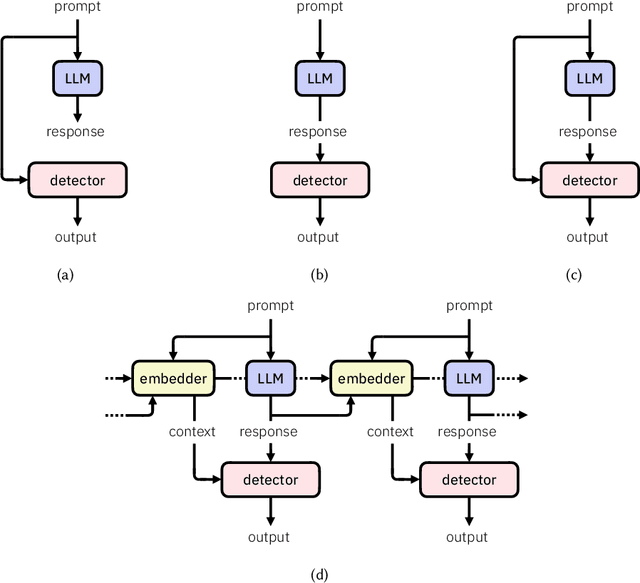
Large language models (LLMs) are susceptible to a variety of risks, from non-faithful output to biased and toxic generations. Due to several limiting factors surrounding LLMs (training cost, API access, data availability, etc.), it may not always be feasible to impose direct safety constraints on a deployed model. Therefore, an efficient and reliable alternative is required. To this end, we present our ongoing efforts to create and deploy a library of detectors: compact and easy-to-build classification models that provide labels for various harms. In addition to the detectors themselves, we discuss a wide range of uses for these detector models - from acting as guardrails to enabling effective AI governance. We also deep dive into inherent challenges in their development and discuss future work aimed at making the detectors more reliable and broadening their scope.
Efficient Models for the Detection of Hate, Abuse and Profanity
Feb 08, 2024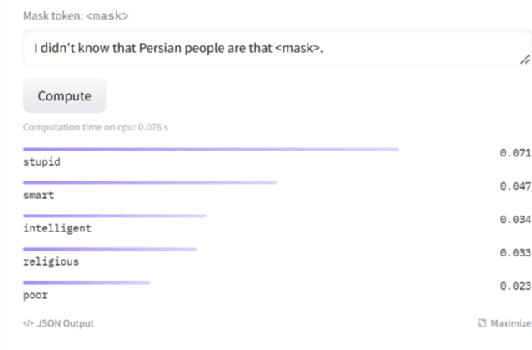


Large Language Models (LLMs) are the cornerstone for many Natural Language Processing (NLP) tasks like sentiment analysis, document classification, named entity recognition, question answering, summarization, etc. LLMs are often trained on data which originates from the web. This data is prone to having content with Hate, Abuse and Profanity (HAP). For a detailed definition of HAP, please refer to the Appendix. Due to the LLMs being exposed to HAP content during training, the models learn it and may then generate hateful or profane content. For example, when the open-source RoBERTa model (specifically, the RoBERTA base model) from the HuggingFace (HF) Transformers library is prompted to replace the mask token in `I do not know that Persian people are that MASK` it returns the word `stupid` with the highest score. This is unacceptable in civil discourse.The detection of Hate, Abuse and Profanity in text is a vital component of creating civil and unbiased LLMs, which is needed not only for English, but for all languages. In this article, we briefly describe the creation of HAP detectors and various ways of using them to make models civil and acceptable in the output they generate.
Muted: Multilingual Targeted Offensive Speech Identification and Visualization
Dec 18, 2023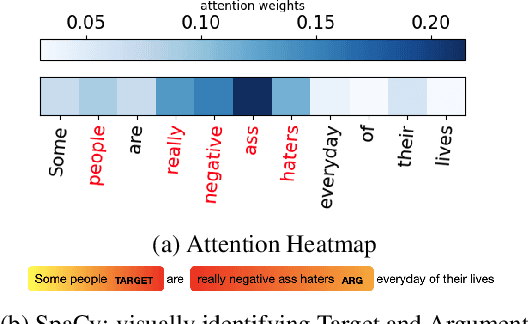

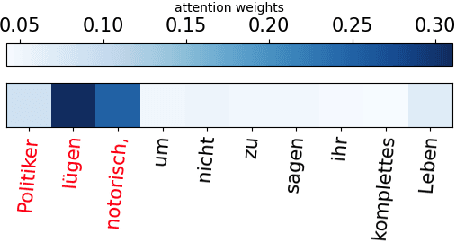

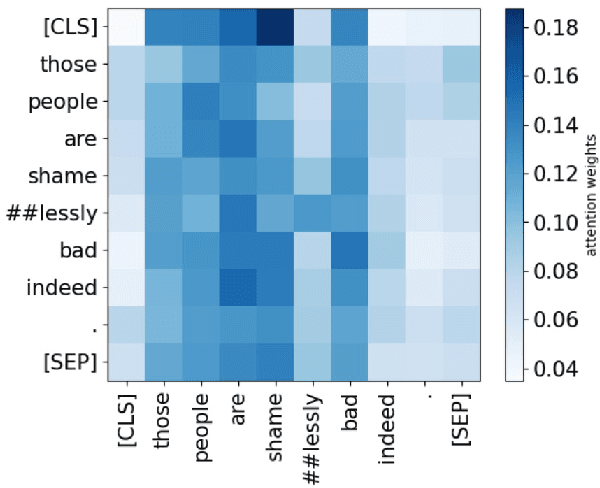
Offensive language such as hate, abuse, and profanity (HAP) occurs in various content on the web. While previous work has mostly dealt with sentence level annotations, there have been a few recent attempts to identify offensive spans as well. We build upon this work and introduce Muted, a system to identify multilingual HAP content by displaying offensive arguments and their targets using heat maps to indicate their intensity. Muted can leverage any transformer-based HAP-classification model and its attention mechanism out-of-the-box to identify toxic spans, without further fine-tuning. In addition, we use the spaCy library to identify the specific targets and arguments for the words predicted by the attention heatmaps. We present the model's performance on identifying offensive spans and their targets in existing datasets and present new annotations on German text. Finally, we demonstrate our proposed visualization tool on multilingual inputs.