 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow critically can an AI think? A framework for evaluating the quality of thinking of generative artificial intelligence
Paper and Code
Jun 20, 2024

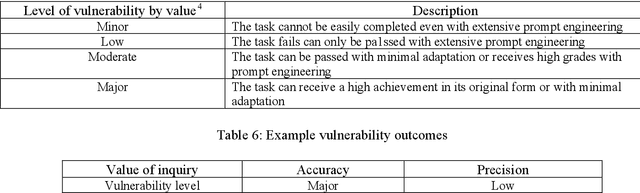
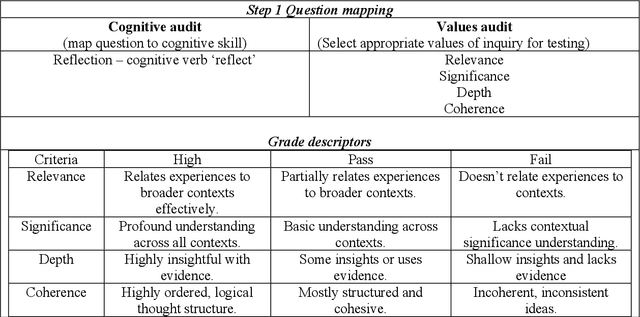
Generative AI such as those with large language models have created opportunities for innovative assessment design practices. Due to recent technological developments, there is a need to know the limits and capabilities of generative AI in terms of simulating cognitive skills. Assessing student critical thinking skills has been a feature of assessment for time immemorial, but the demands of digital assessment create unique challenges for equity, academic integrity and assessment authorship. Educators need a framework for determining their assessments vulnerability to generative AI to inform assessment design practices. This paper presents a framework that explores the capabilities of the LLM ChatGPT4 application, which is the current industry benchmark. This paper presents the Mapping of questions, AI vulnerability testing, Grading, Evaluation (MAGE) framework to methodically critique their assessments within their own disciplinary contexts. This critique will provide specific and targeted indications of their questions vulnerabilities in terms of the critical thinking skills. This can go on to form the basis of assessment design for their tasks.