 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Relational Question Answering from Narratives: Machine Reading and Reasoning in Simulated Worlds
Feb 25, 2019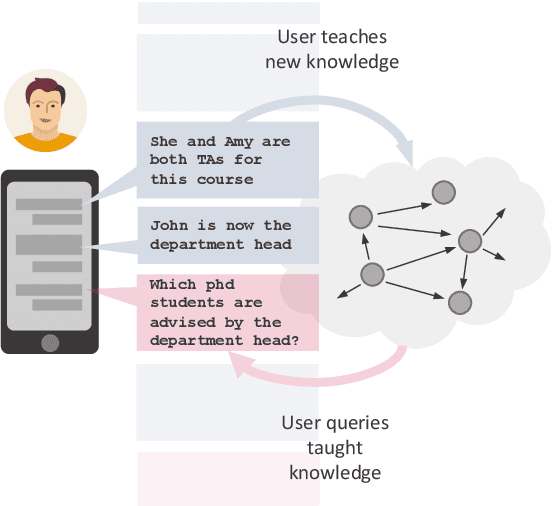
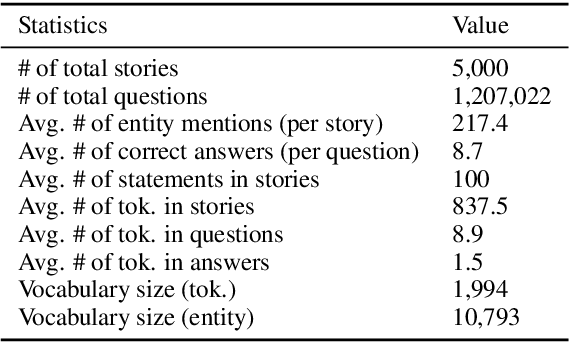

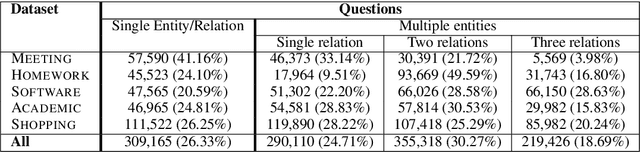
Question Answering (QA), as a research field, has primarily focused on either knowledge bases (KBs) or free text as a source of knowledge. These two sources have historically shaped the kinds of questions that are asked over these sources, and the methods developed to answer them. In this work, we look towards a practical use-case of QA over user-instructed knowledge that uniquely combines elements of both structured QA over knowledge bases, and unstructured QA over narrative, introducing the task of multi-relational QA over personal narrative. As a first step towards this goal, we make three key contributions: (i) we generate and release TextWorldsQA, a set of five diverse datasets, where each dataset contains dynamic narrative that describes entities and relations in a simulated world, paired with variably compositional questions over that knowledge, (ii) we perform a thorough evaluation and analysis of several state-of-the-art QA models and their variants at this task, and (iii) we release a lightweight Python-based framework we call TextWorlds for easily generating arbitrary additional worlds and narrative, with the goal of allowing the community to create and share a growing collection of diverse worlds as a test-bed for this task.
* published at ACL 2018
Leveraging Knowledge Bases in LSTMs for Improving Machine Reading
Feb 25, 2019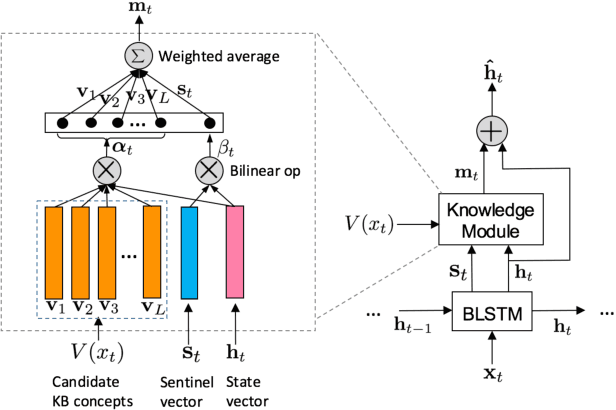
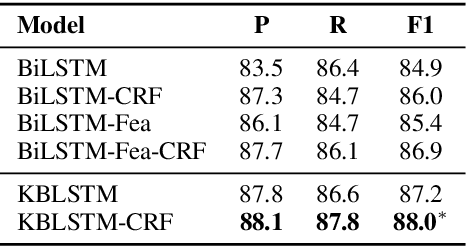
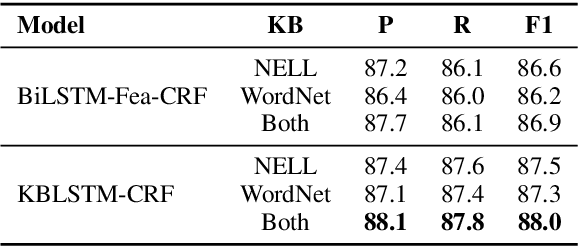
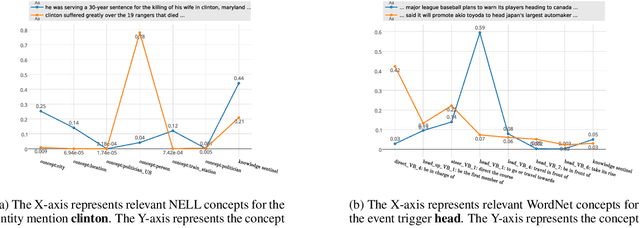
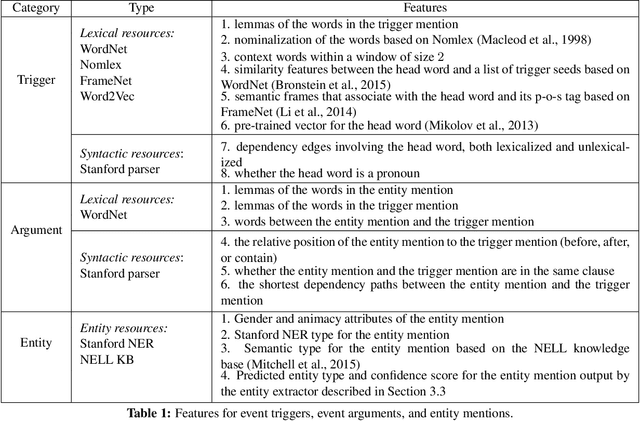
This paper focuses on how to take advantage of external knowledge bases (KBs) to improve recurrent neural networks for machine reading. Traditional methods that exploit knowledge from KBs encode knowledge as discrete indicator features. Not only do these features generalize poorly, but they require task-specific feature engineering to achieve good performance. We propose KBLSTM, a novel neural model that leverages continuous representations of KBs to enhance the learning of recurrent neural networks for machine reading. To effectively integrate background knowledge with information from the currently processed text, our model employs an attention mechanism with a sentinel to adaptively decide whether to attend to background knowledge and which information from KBs is useful. Experimental results show that our model achieves accuracies that surpass the previous state-of-the-art results for both entity extraction and event extraction on the widely used ACE2005 dataset.
* published at ACL 2017
Learning to Learn Semantic Parsers from Natural Language Supervision
Feb 22, 2019


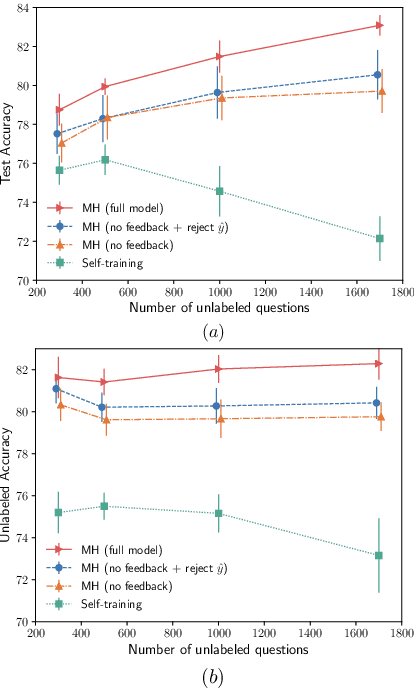
As humans, we often rely on language to learn language. For example, when corrected in a conversation, we may learn from that correction, over time improving our language fluency. Inspired by this observation, we propose a learning algorithm for training semantic parsers from supervision (feedback) expressed in natural language. Our algorithm learns a semantic parser from users' corrections such as "no, what I really meant was before his job, not after", by also simultaneously learning to parse this natural language feedback in order to leverage it as a form of supervision. Unlike supervision with gold-standard logical forms, our method does not require the user to be familiar with the underlying logical formalism, and unlike supervision from denotation, it does not require the user to know the correct answer to their query. This makes our learning algorithm naturally scalable in settings where existing conversational logs are available and can be leveraged as training data. We construct a novel dataset of natural language feedback in a conversational setting, and show that our method is effective at learning a semantic parser from such natural language supervision.
End-to-End Learning for Structured Prediction Energy Networks
Jul 15, 2017
Structured Prediction Energy Networks (SPENs) are a simple, yet expressive family of structured prediction models (Belanger and McCallum, 2016). An energy function over candidate structured outputs is given by a deep network, and predictions are formed by gradient-based optimization. This paper presents end-to-end learning for SPENs, where the energy function is discriminatively trained by back-propagating through gradient-based prediction. In our experience, the approach is substantially more accurate than the structured SVM method of Belanger and McCallum (2016), as it allows us to use more sophisticated non-convex energies. We provide a collection of techniques for improving the speed, accuracy, and memory requirements of end-to-end SPENs, and demonstrate the power of our method on 7-Scenes image denoising and CoNLL-2005 semantic role labeling tasks. In both, inexact minimization of non-convex SPEN energies is superior to baseline methods that use simplistic energy functions that can be minimized exactly.
Joint Extraction of Events and Entities within a Document Context
Sep 12, 2016
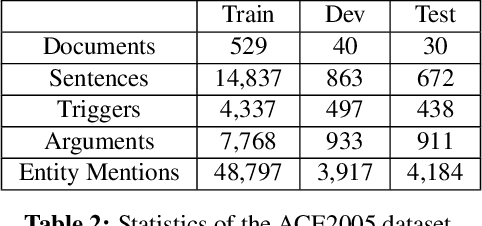
Events and entities are closely related; entities are often actors or participants in events and events without entities are uncommon. The interpretation of events and entities is highly contextually dependent. Existing work in information extraction typically models events separately from entities, and performs inference at the sentence level, ignoring the rest of the document. In this paper, we propose a novel approach that models the dependencies among variables of events, entities, and their relations, and performs joint inference of these variables across a document. The goal is to enable access to document-level contextual information and facilitate context-aware predictions. We demonstrate that our approach substantially outperforms the state-of-the-art methods for event extraction as well as a strong baseline for entity extraction.
* 11 pages, 2 figures, published at NAACL 2016
A Hierarchical Distance-dependent Bayesian Model for Event Coreference Resolution
Sep 25, 2015We present a novel hierarchical distance-dependent Bayesian model for event coreference resolution. While existing generative models for event coreference resolution are completely unsupervised, our model allows for the incorporation of pairwise distances between event mentions -- information that is widely used in supervised coreference models to guide the generative clustering processing for better event clustering both within and across documents. We model the distances between event mentions using a feature-rich learnable distance function and encode them as Bayesian priors for nonparametric clustering. Experiments on the ECB+ corpus show that our model outperforms state-of-the-art methods for both within- and cross-document event coreference resolution.
Embedding Entities and Relations for Learning and Inference in Knowledge Bases
Aug 29, 2015
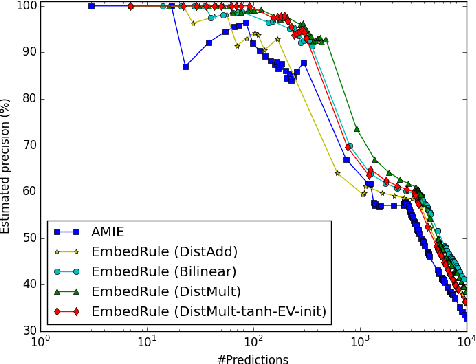
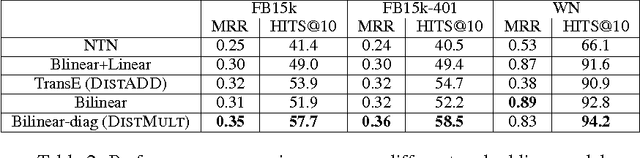
We consider learning representations of entities and relations in KBs using the neural-embedding approach. We show that most existing models, including NTN (Socher et al., 2013) and TransE (Bordes et al., 2013b), can be generalized under a unified learning framework, where entities are low-dimensional vectors learned from a neural network and relations are bilinear and/or linear mapping functions. Under this framework, we compare a variety of embedding models on the link prediction task. We show that a simple bilinear formulation achieves new state-of-the-art results for the task (achieving a top-10 accuracy of 73.2% vs. 54.7% by TransE on Freebase). Furthermore, we introduce a novel approach that utilizes the learned relation embeddings to mine logical rules such as "BornInCity(a,b) and CityInCountry(b,c) => Nationality(a,c)". We find that embeddings learned from the bilinear objective are particularly good at capturing relational semantics and that the composition of relations is characterized by matrix multiplication. More interestingly, we demonstrate that our embedding-based rule extraction approach successfully outperforms a state-of-the-art confidence-based rule mining approach in mining Horn rules that involve compositional reasoning.
Learning Multi-Relational Semantics Using Neural-Embedding Models
Nov 14, 2014
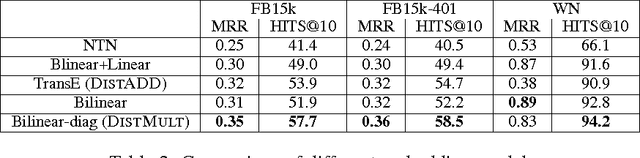
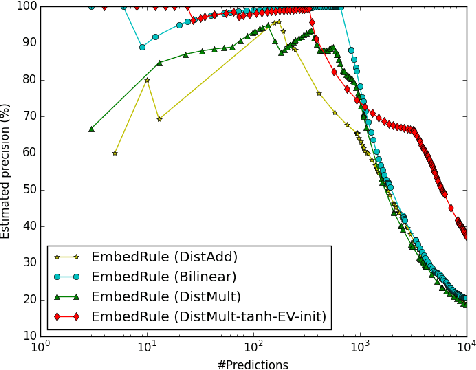
In this paper we present a unified framework for modeling multi-relational representations, scoring, and learning, and conduct an empirical study of several recent multi-relational embedding models under the framework. We investigate the different choices of relation operators based on linear and bilinear transformations, and also the effects of entity representations by incorporating unsupervised vectors pre-trained on extra textual resources. Our results show several interesting findings, enabling the design of a simple embedding model that achieves the new state-of-the-art performance on a popular knowledge base completion task evaluated on Freebase.