 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree Energy Risk Metrics for Systemically Safe AI: Gatekeeping Multi-Agent Study
Feb 06, 2025We investigate the Free Energy Principle as a foundation for measuring risk in agentic and multi-agent systems. From these principles we introduce a Cumulative Risk Exposure metric that is flexible to differing contexts and needs. We contrast this to other popular theories for safe AI that hinge on massive amounts of data or describing arbitrarily complex world models. In our framework, stakeholders need only specify their preferences over system outcomes, providing straightforward and transparent decision rules for risk governance and mitigation. This framework naturally accounts for uncertainty in both world model and preference model, allowing for decision-making that is epistemically and axiologically humble, parsimonious, and future-proof. We demonstrate this novel approach in a simplified autonomous vehicle environment with multi-agent vehicles whose driving policies are mediated by gatekeepers that evaluate, in an online fashion, the risk to the collective safety in their neighborhood, and intervene through each vehicle's policy when appropriate. We show that the introduction of gatekeepers in an AV fleet, even at low penetration, can generate significant positive externalities in terms of increased system safety.
An active inference model of collective intelligence
Apr 02, 2021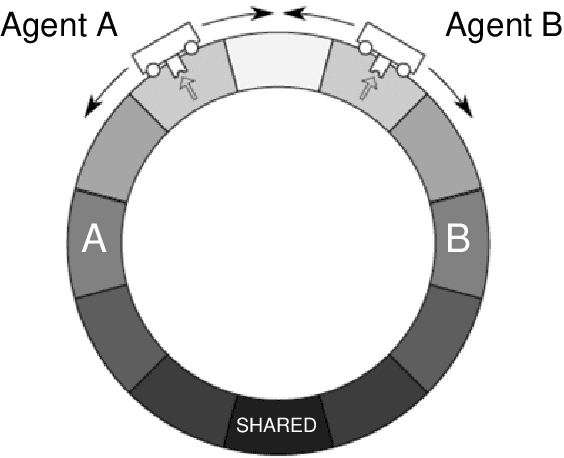

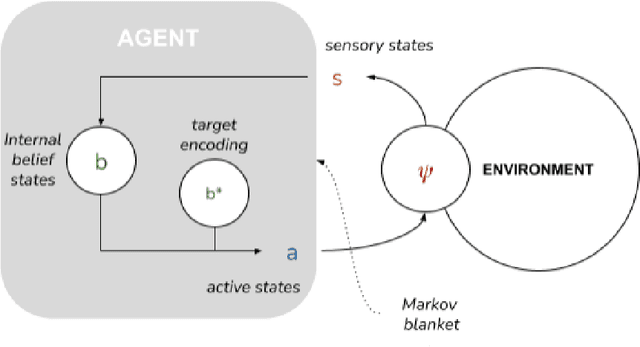
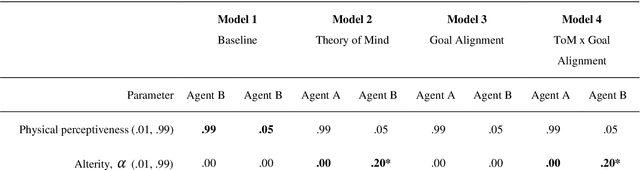
To date, formal models of collective intelligence have lacked a plausible mathematical description of the relationship between local-scale interactions between highly autonomous sub-system components (individuals) and global-scale behavior of the composite system (the collective). In this paper we use the Active Inference Formulation (AIF), a framework for explaining the behavior of any non-equilibrium steady state system at any scale, to posit a minimal agent-based model that simulates the relationship between local individual-level interaction and collective intelligence (operationalized as system-level performance). We explore the effects of providing baseline AIF agents (Model 1) with specific cognitive capabilities: Theory of Mind (Model 2); Goal Alignment (Model 3), and Theory of Mind with Goal Alignment (Model 4). These stepwise transitions in sophistication of cognitive ability are motivated by the types of advancements plausibly required for an AIF agent to persist and flourish in an environment populated by other AIF agents, and have also recently been shown to map naturally to canonical steps in human cognitive ability. Illustrative results show that stepwise cognitive transitions increase system performance by providing complementary mechanisms for alignment between agents' local and global optima. Alignment emerges endogenously from the dynamics of interacting AIF agents themselves, rather than being imposed exogenously by incentives to agents' behaviors (contra existing computational models of collective intelligence) or top-down priors for collective behavior (contra existing multiscale simulations of AIF). These results shed light on the types of generic information-theoretic patterns conducive to collective intelligence in human and other complex adaptive systems.