 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Workflow for Full Traceability of AI Decisions
Nov 17, 2025An ever increasing number of high-stake decisions are made or assisted by automated systems employing brittle artificial intelligence technology. There is a substantial risk that some of these decision induce harm to people, by infringing their well-being or their fundamental human rights. The state-of-the-art in AI systems makes little effort with respect to appropriate documentation of the decision process. This obstructs the ability to trace what went into a decision, which in turn is a prerequisite to any attempt of reconstructing a responsibility chain. Specifically, such traceability is linked to a documentation that will stand up in court when determining the cause of some AI-based decision that inadvertently or intentionally violates the law. This paper takes a radical, yet practical, approach to this problem, by enforcing the documentation of each and every component that goes into the training or inference of an automated decision. As such, it presents the first running workflow supporting the generation of tamper-proof, verifiable and exhaustive traces of AI decisions. In doing so, we expand the DBOM concept into an effective running workflow leveraging confidential computing technology. We demonstrate the inner workings of the workflow in the development of an app to tell poisonous and edible mushrooms apart, meant as a playful example of high-stake decision support.
Keep your Distance: Determining Sampling and Distance Thresholds in Machine Learning Monitoring
Jul 11, 2022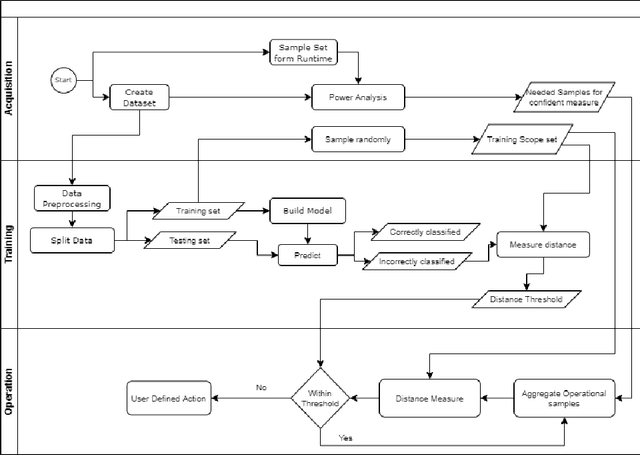

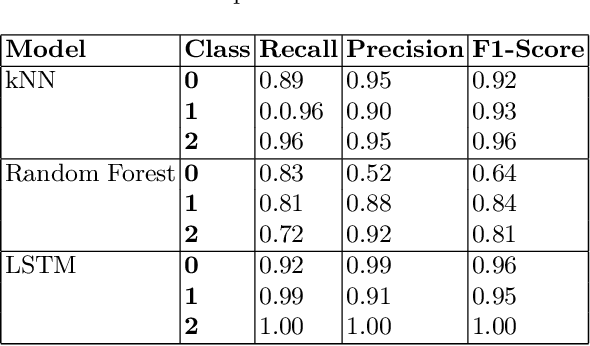
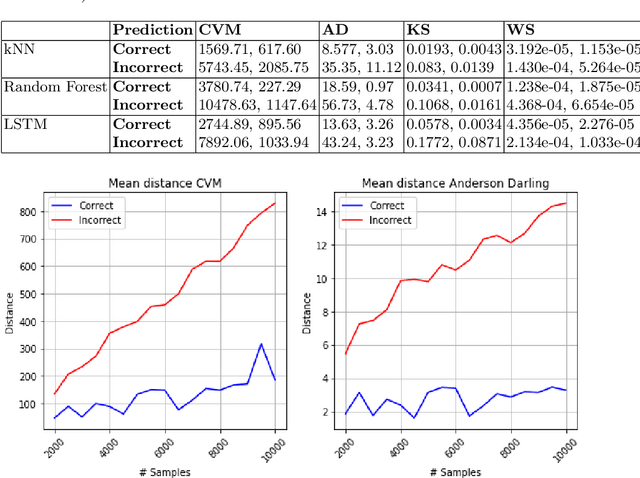
Machine Learning~(ML) has provided promising results in recent years across different applications and domains. However, in many cases, qualities such as reliability or even safety need to be ensured. To this end, one important aspect is to determine whether or not ML components are deployed in situations that are appropriate for their application scope. For components whose environments are open and variable, for instance those found in autonomous vehicles, it is therefore important to monitor their operational situation to determine its distance from the ML components' trained scope. If that distance is deemed too great, the application may choose to consider the ML component outcome unreliable and switch to alternatives, e.g. using human operator input instead. SafeML is a model-agnostic approach for performing such monitoring, using distance measures based on statistical testing of the training and operational datasets. Limitations in setting SafeML up properly include the lack of a systematic approach for determining, for a given application, how many operational samples are needed to yield reliable distance information as well as to determine an appropriate distance threshold. In this work, we address these limitations by providing a practical approach and demonstrate its use in a well known traffic sign recognition problem, and on an example using the CARLA open-source automotive simulator.
It's AI Match: A Two-Step Approach for Schema Matching Using Embeddings
Mar 08, 2022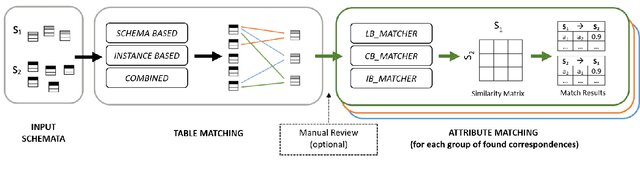
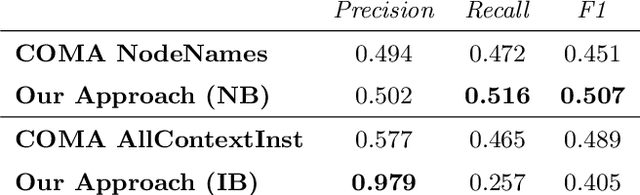
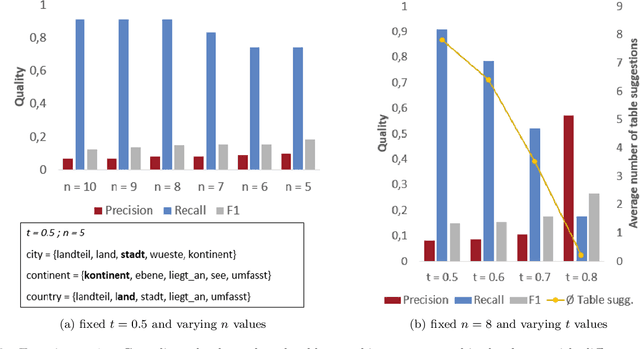
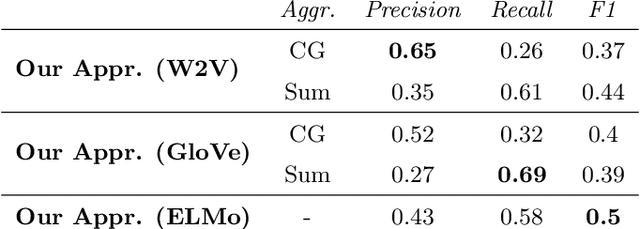
Since data is often stored in different sources, it needs to be integrated to gather a global view that is required in order to create value and derive knowledge from it. A critical step in data integration is schema matching which aims to find semantic correspondences between elements of two schemata. In order to reduce the manual effort involved in schema matching, many solutions for the automatic determination of schema correspondences have already been developed. In this paper, we propose a novel end-to-end approach for schema matching based on neural embeddings. The main idea is to use a two-step approach consisting of a table matching step followed by an attribute matching step. In both steps we use embeddings on different levels either representing the whole table or single attributes. Our results show that our approach is able to determine correspondences in a robust and reliable way and compared to traditional schema matching approaches can find non-trivial correspondences.