 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribute or Abstain: Large Language Models as Long Document Assistants
Paper and Code

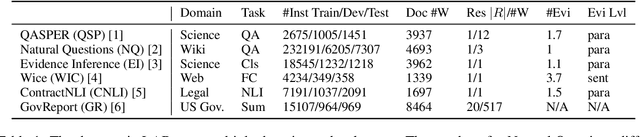
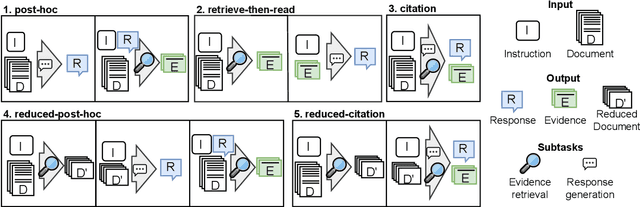
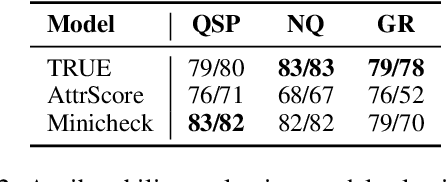
LLMs can help humans working with long documents, but are known to hallucinate. Attribution can increase trust in LLM responses: The LLM provides evidence that supports its response, which enhances verifiability. Existing approaches to attribution have only been evaluated in RAG settings, where the initial retrieval confounds LLM performance. This is crucially different from the long document setting, where retrieval is not needed, but could help. Thus, a long document specific evaluation of attribution is missing. To fill this gap, we present LAB, a benchmark of 6 diverse long document tasks with attribution, and experiment with different approaches to attribution on 4 LLMs of different sizes, both prompted and fine-tuned. We find that citation, i.e. response generation and evidence extraction in one step, mostly performs best. We investigate whether the ``Lost in the Middle'' phenomenon exists for attribution, but do not find this. We also find that evidence quality can predict response quality on datasets with simple responses, but not so for complex responses, as models struggle with providing evidence for complex claims. We release code and data for further investigation.