 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Lookahead Encoding and Abstracted Width for Learning General Policies in Classical Planning
May 18, 2026Generalized planning aims to learn policies that generalize across collections of instances within a classical planning domain. Recent Graph Neural Network (GNN) approaches have learned nearly perfect policies for several domains. This work improves on the recently published idea of Iterated Width (IW) policies. Therein, the policy broadens its successor scope through an IW-lookahead search that can "jump" over multiple transitions, simplifying the problem structure. Yet, each transition is evaluated individually, leading to unscalable compute costs and expressivity limitations. Furthermore, although IW(1) is attractive because it scales linearly with the number of atoms, it becomes inefficient once thousands of objects are considered, as in the International Planning Competition (IPC) 2023 benchmark. We address both limitations. First, we introduce a vastly more efficient holistic encoding of the entire search tree. It jointly represents IW(1)-reachable states only by their relational differences to the current state, enabling Relational GNNs (R-GNNs) to score all transitions in a single forward pass. Second, we define Abstracted IW(1) to improve scaling through relational abstraction during novelty checks. Rather than testing fully instantiated atoms, it abstracts each atom by replacing all but one argument with its type. The original atom is novel if any of its abstracted forms is novel. This structural compression shifts novelty search scaling from atoms to objects, while preserving meaningful subgoal structure. We evaluate our contributions on the hyperscaling IPC 2023 benchmark and across diverse domains, including domains requiring features beyond the $C_2$ logic fragment. Our policies achieve new state-of-the-art performance, significantly surpassing prior work, including the classical planner LAMA.
Learning to Ground Existentially Quantified Goals
Sep 30, 2024Goal instructions for autonomous AI agents cannot assume that objects have unique names. Instead, objects in goals must be referred to by providing suitable descriptions. However, this raises problems in both classical planning and generalized planning. The standard approach to handling existentially quantified goals in classical planning involves compiling them into a DNF formula that encodes all possible variable bindings and adding dummy actions to map each DNF term into the new, dummy goal. This preprocessing is exponential in the number of variables. In generalized planning, the problem is different: even if general policies can deal with any initial situation and goal, executing a general policy requires the goal to be grounded to define a value for the policy features. The problem of grounding goals, namely finding the objects to bind the goal variables, is subtle: it is a generalization of classical planning, which is a special case when there are no goal variables to bind, and constraint reasoning, which is a special case when there are no actions. In this work, we address the goal grounding problem with a novel supervised learning approach. A GNN architecture, trained to predict the cost of partially quantified goals over small domain instances is tested on larger instances involving more objects and different quantified goals. The proposed architecture is evaluated experimentally over several planning domains where generalization is tested along several dimensions including the number of goal variables and objects that can bind such variables. The scope of the approach is also discussed in light of the known relationship between GNNs and C2 logics.
CiteBench: A benchmark for Scientific Citation Text Generation
Dec 19, 2022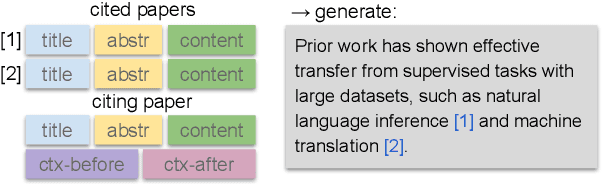


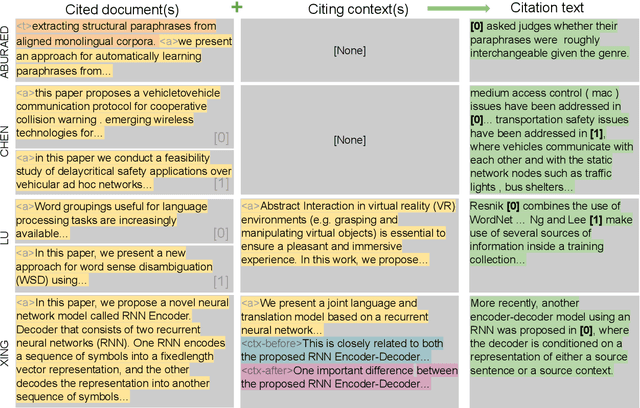
The publication rates are skyrocketing across many fields of science, and it is difficult to stay up to date with the latest research. This makes automatically summarizing the latest findings and helping scholars to synthesize related work in a given area an attractive research objective. In this paper we study the problem of citation text generation, where given a set of cited papers and citing context the model should generate a citation text. While citation text generation has been tackled in prior work, existing studies use different datasets and task definitions, which makes it hard to study citation text generation systematically. To address this, we propose CiteBench: a benchmark for citation text generation that unifies the previous datasets and enables standardized evaluation of citation text generation models across task settings and domains. Using the new benchmark, we investigate the performance of multiple strong baselines, test their transferability between the datasets, and deliver new insights into task definition and evaluation to guide the future research in citation text generation. We make CiteBench publicly available at https://github.com/UKPLab/citebench.