 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-efficient Continual Learning with Neural Collapse Contrastive
Dec 05, 2024



Contrastive learning has significantly improved representation quality, enhancing knowledge transfer across tasks in continual learning (CL). However, catastrophic forgetting remains a key challenge, as contrastive based methods primarily focus on "soft relationships" or "softness" between samples, which shift with changing data distributions and lead to representation overlap across tasks. Recently, the newly identified Neural Collapse phenomenon has shown promise in CL by focusing on "hard relationships" or "hardness" between samples and fixed prototypes. However, this approach overlooks "softness", crucial for capturing intra-class variability, and this rigid focus can also pull old class representations toward current ones, increasing forgetting. Building on these insights, we propose Focal Neural Collapse Contrastive (FNC2), a novel representation learning loss that effectively balances both soft and hard relationships. Additionally, we introduce the Hardness-Softness Distillation (HSD) loss to progressively preserve the knowledge gained from these relationships across tasks. Our method outperforms state-of-the-art approaches, particularly in minimizing memory reliance. Remarkably, even without the use of memory, our approach rivals rehearsal-based methods, offering a compelling solution for data privacy concerns.
Towards Explainable Clustering: A Constrained Declarative based Approach
Mar 26, 2024The domain of explainable AI is of interest in all Machine Learning fields, and it is all the more important in clustering, an unsupervised task whose result must be validated by a domain expert. We aim at finding a clustering that has high quality in terms of classic clustering criteria and that is explainable, and we argue that these two dimensions must be considered when building the clustering. We consider that a good global explanation of a clustering should give the characteristics of each cluster taking into account their abilities to describe its objects (coverage) while distinguishing it from the other clusters (discrimination). Furthermore, we aim at leveraging expert knowledge, at different levels, on the structure of the expected clustering or on its explanations. In our framework an explanation of a cluster is a set of patterns, and we propose a novel interpretable constrained clustering method called ECS for declarative clustering with Explainabilty-driven Cluster Selection that integrates structural or domain expert knowledge expressed by means of constraints. It is based on the notion of coverage and discrimination that are formalized at different levels (cluster / clustering), each allowing for exceptions through parameterized thresholds. Our method relies on four steps: generation of a set of partitions, computation of frequent patterns for each cluster, pruning clusters that violates some constraints, and selection of clusters and associated patterns to build an interpretable clustering. This last step is combinatorial and we have developed a Constraint-Programming (CP) model to solve it. The method can integrate prior knowledge in the form of user constraints, both before or in the CP model.
Convolutional Shapelet Transform: A new approach for time series shapelets
Sep 28, 2021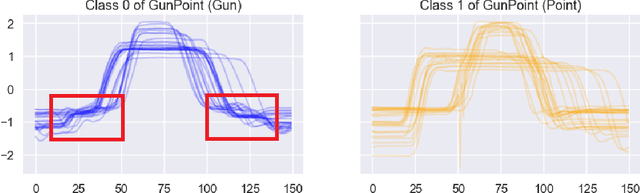
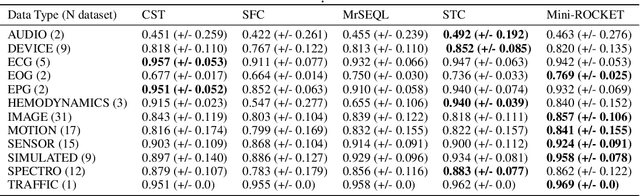
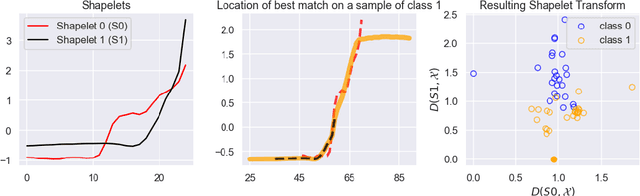
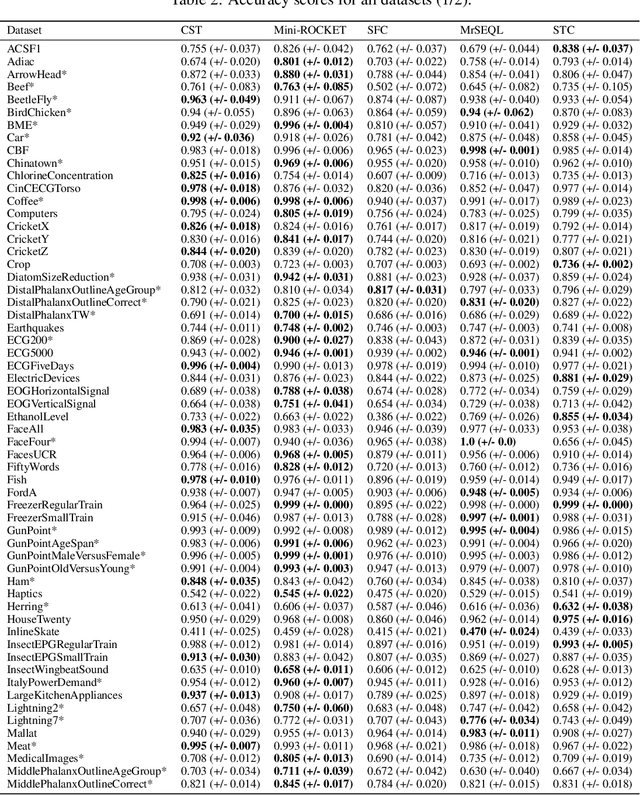
Shapelet-based algorithms are widely used for time series classification because of their ease of interpretation, but they are currently outperformed, notably by methods using convolutional kernels, capable of reaching state-of-the-art performance while being highly scalable. We present a new formulation of time series shapelets including the notion of dilation, and a shapelet extraction method based on convolutional kernels, which is able to target the discriminant information identified by convolutional kernels. Experiments performed on 108 datasets show that our method improves on the state-of-the-art for shapelet algorithms, and we show that it can be used to interpret results from convolutional kernels.
Time series classification for predictive maintenance on event logs
Nov 24, 2020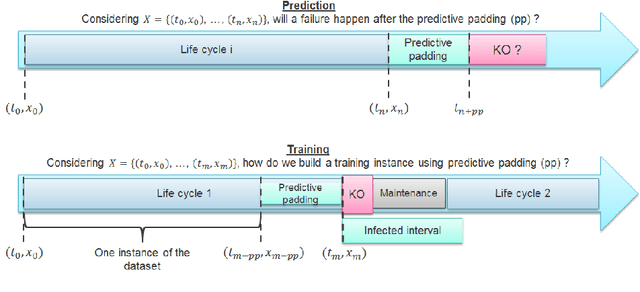
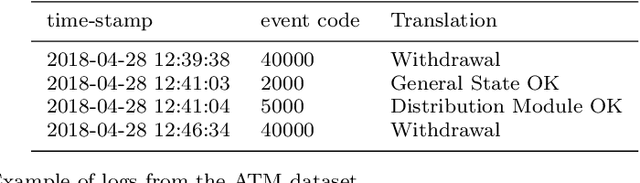
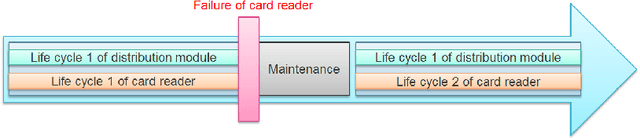
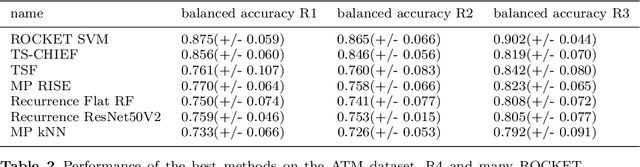
Time series classification (TSC) gained a lot of attention in the past decade and number of methods for representing and classifying time series have been proposed. Nowadays, methods based on convolutional networks and ensemble techniques represent the state of the art for time series classification. Techniques transforming time series to image or text also provide reliable ways to extract meaningful features or representations of time series. We compare the state-of-the-art representation and classification methods on a specific application, that is predictive maintenance from sequences of event logs. The contributions of this paper are twofold: introducing a new data set for predictive maintenance on automated teller machines (ATMs) log data and comparing the performance of different representation methods for predicting the occurrence of a breakdown. The problem is difficult since unlike the classic case of predictive maintenance via signals from sensors, we have sequences of discrete event logs occurring at any time and the lengths of the sequences, corresponding to life cycles, vary a lot.
From Shallow to Deep Interactions Between Knowledge Representation, Reasoning and Machine Learning (Kay R. Amel group)
Dec 13, 2019This paper proposes a tentative and original survey of meeting points between Knowledge Representation and Reasoning (KRR) and Machine Learning (ML), two areas which have been developing quite separately in the last three decades. Some common concerns are identified and discussed such as the types of used representation, the roles of knowledge and data, the lack or the excess of information, or the need for explanations and causal understanding. Then some methodologies combining reasoning and learning are reviewed (such as inductive logic programming, neuro-symbolic reasoning, formal concept analysis, rule-based representations and ML, uncertainty in ML, or case-based reasoning and analogical reasoning), before discussing examples of synergies between KRR and ML (including topics such as belief functions on regression, EM algorithm versus revision, the semantic description of vector representations, the combination of deep learning with high level inference, knowledge graph completion, declarative frameworks for data mining, or preferences and recommendation). This paper is the first step of a work in progress aiming at a better mutual understanding of research in KRR and ML, and how they could cooperate.