 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPACR: Single-Pass Adaptive Training of Uncertainty-Aware Conformal Regressors
Jun 09, 2026Conformal Prediction (CP) provides robust uncertainty guarantees for predictive models, but is typically applied post hoc, which misaligns model training with the conformal goal of producing efficient (i.e, narrow) intervals. We propose SPACR (Single-Pass Adaptive Conformal Regressor), a novel method for directly training uncertainty-aware regressors within a differentiable loss. SPACR jointly optimizes efficiency and validity without batch-splitting or a predefined confidence levels during training. As a result, a single SPACR model yields valid prediction intervals at multiple confidence levels during inference, avoiding the costly retraining required by methods like DOICR. Experiments on diverse datasets show that SPACR consistently gives tighter intervals and better coverage-efficiency trade-offs compared to standard CP and DOICR, while significantly reducing computational costs.
Quantification of Credal Uncertainty: A Distance-Based Approach
Mar 28, 2026Credal sets, i.e., closed convex sets of probability measures, provide a natural framework to represent aleatoric and epistemic uncertainty in machine learning. Yet how to quantify these two types of uncertainty for a given credal set, particularly in multiclass classification, remains underexplored. In this paper, we propose a distance-based approach to quantify total, aleatoric, and epistemic uncertainty for credal sets. Concretely, we introduce a family of such measures within the framework of Integral Probability Metrics (IPMs). The resulting quantities admit clear semantic interpretations, satisfy natural theoretical desiderata, and remain computationally tractable for common choices of IPMs. We instantiate the framework with the total variation distance and obtain simple, efficient uncertainty measures for multiclass classification. In the binary case, this choice recovers established uncertainty measures, for which a principled multiclass generalization has so far been missing. Empirical results confirm practical usefulness, with favorable performance at low computational cost.
Upper Entropy for 2-Monotone Lower Probabilities
Mar 23, 2026Uncertainty quantification is a key aspect in many tasks such as model selection/regularization, or quantifying prediction uncertainties to perform active learning or OOD detection. Within credal approaches that consider modeling uncertainty as probability sets, upper entropy plays a central role as an uncertainty measure. This paper is devoted to the computational aspect of upper entropies, providing an exhaustive algorithmic and complexity analysis of the problem. In particular, we show that the problem has a strongly polynomial solution, and propose many significant improvements over past algorithms proposed for 2-monotone lower probabilities and their specific cases.
Guaranteed confidence-band enclosures for PDE surrogates
Jan 30, 2025



We propose a method for obtaining statistically guaranteed confidence bands for functional machine learning techniques: surrogate models which map between function spaces, motivated by the need build reliable PDE emulators. The method constructs nested confidence sets on a low-dimensional representation (an SVD) of the surrogate model's prediction error, and then maps these sets to the prediction space using set-propagation techniques. The result are conformal-like coverage guaranteed prediction sets for functional surrogate models. We use zonotopes as basis of the set construction, due to their well studied set-propagation and verification properties. The method is model agnostic and can thus be applied to complex Sci-ML models, including Neural Operators, but also in simpler settings. We also elicit a technique to capture the truncation error of the SVD, ensuring the guarantees of the method.
Reducing Aleatoric and Epistemic Uncertainty through Multi-modal Data Acquisition
Jan 30, 2025



To generate accurate and reliable predictions, modern AI systems need to combine data from multiple modalities, such as text, images, audio, spreadsheets, and time series. Multi-modal data introduces new opportunities and challenges for disentangling uncertainty: it is commonly assumed in the machine learning community that epistemic uncertainty can be reduced by collecting more data, while aleatoric uncertainty is irreducible. However, this assumption is challenged in modern AI systems when information is obtained from different modalities. This paper introduces an innovative data acquisition framework where uncertainty disentanglement leads to actionable decisions, allowing sampling in two directions: sample size and data modality. The main hypothesis is that aleatoric uncertainty decreases as the number of modalities increases, while epistemic uncertainty decreases by collecting more observations. We provide proof-of-concept implementations on two multi-modal datasets to showcase our data acquisition framework, which combines ideas from active learning, active feature acquisition and uncertainty quantification.
Robust Confidence Intervals in Stereo Matching using Possibility Theory
Apr 09, 2024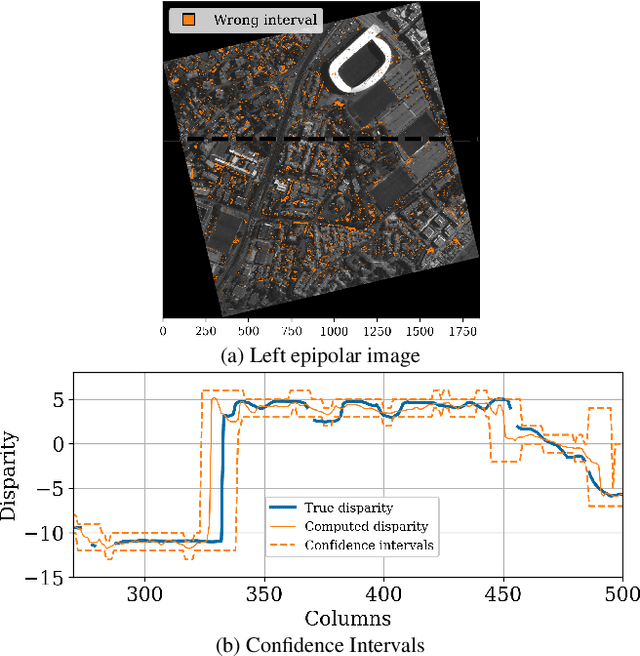
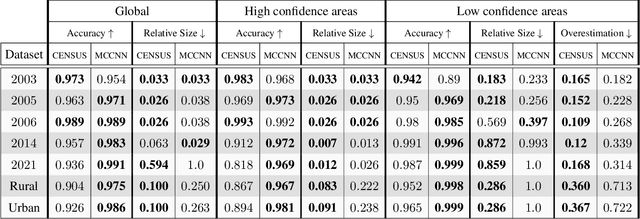
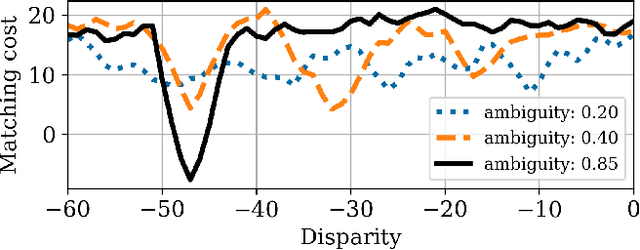
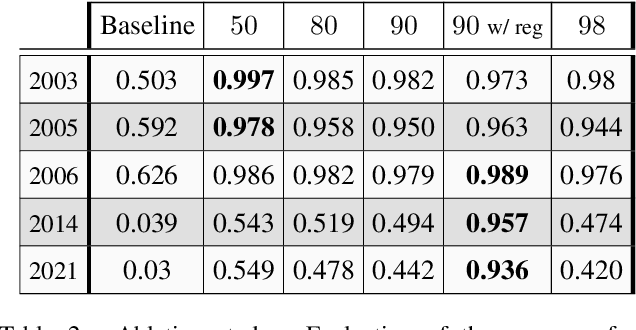
We propose a method for estimating disparity confidence intervals in stereo matching problems. Confidence intervals provide complementary information to usual confidence measures. To the best of our knowledge, this is the first method creating disparity confidence intervals based on the cost volume. This method relies on possibility distributions to interpret the epistemic uncertainty of the cost volume. Our method has the benefit of having a white-box nature, differing in this respect from current state-of-the-art deep neural networks approaches. The accuracy and size of confidence intervals are validated using the Middlebury stereo datasets as well as a dataset of satellite images. This contribution is freely available on GitHub.
Skeptical binary inferences in multi-label problems with sets of probabilities
May 02, 2022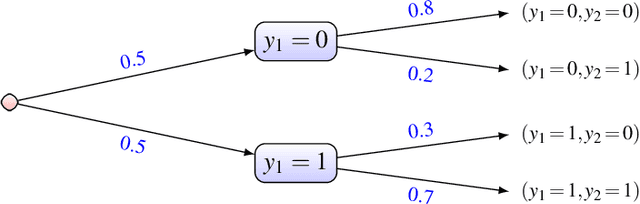

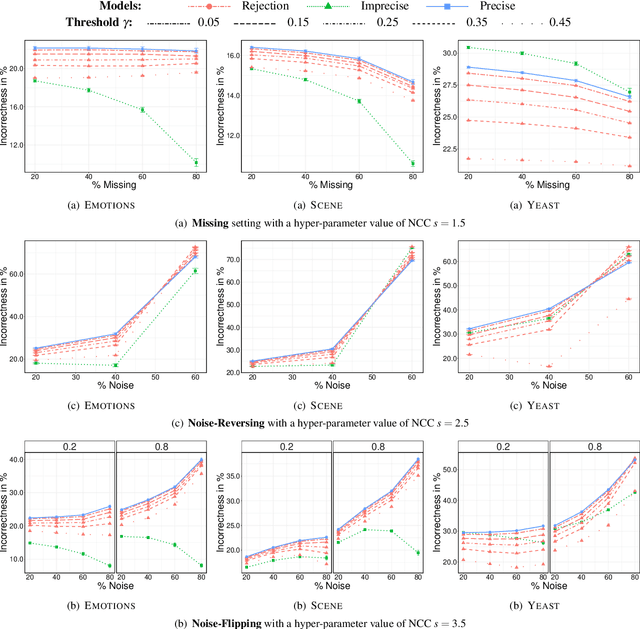
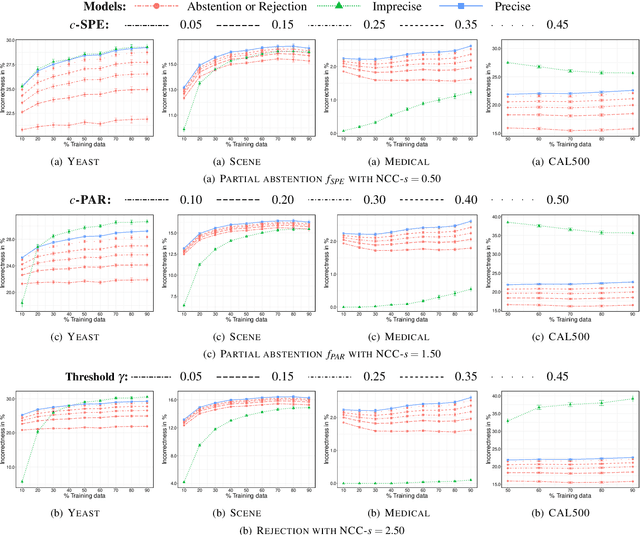
In this paper, we consider the problem of making distributionally robust, skeptical inferences for the multi-label problem, or more generally for Boolean vectors. By distributionally robust, we mean that we consider a set of possible probability distributions, and by skeptical we understand that we consider as valid only those inferences that are true for every distribution within this set. Such inferences will provide partial predictions whenever the considered set is sufficiently big. We study in particular the Hamming loss case, a common loss function in multi-label problems, showing how skeptical inferences can be made in this setting. Our experimental results are organised in three sections; (1) the first one indicates the gain computational obtained from our theoretical results by using synthetical data sets, (2) the second one indicates that our approaches produce relevant cautiousness on those hard-to-predict instances where its precise counterpart fails, and (3) the last one demonstrates experimentally how our approach copes with imperfect information (generated by a downsampling procedure) better than the partial abstention [31] and the rejection rules.
Multi-label Chaining with Imprecise Probabilities
Jul 19, 2021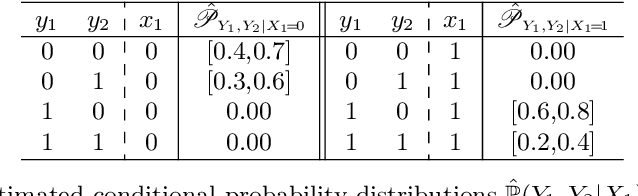
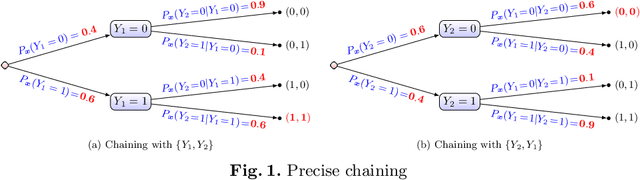
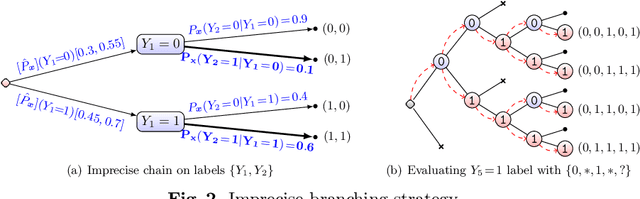
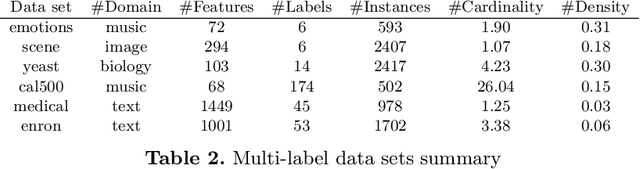
We present two different strategies to extend the classical multi-label chaining approach to handle imprecise probability estimates. These estimates use convex sets of distributions (or credal sets) in order to describe our uncertainty rather than a precise one. The main reasons one could have for using such estimations are (1) to make cautious predictions (or no decision at all) when a high uncertainty is detected in the chaining and (2) to make better precise predictions by avoiding biases caused in early decisions in the chaining. We adapt both strategies to the case of the naive credal classifier, showing that this adaptations are computationally efficient. Our experimental results on missing labels, which investigate how reliable these predictions are in both approaches, indicate that our approaches produce relevant cautiousness on those hard-to-predict instances where the precise models fail.
Copula-based conformal prediction for Multi-Target Regression
Jan 28, 2021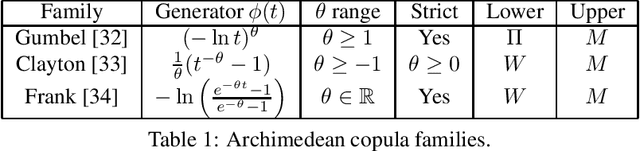
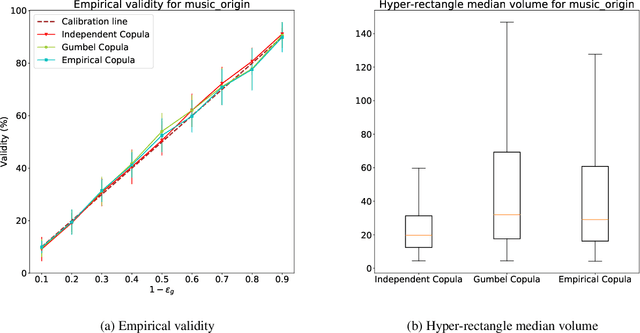

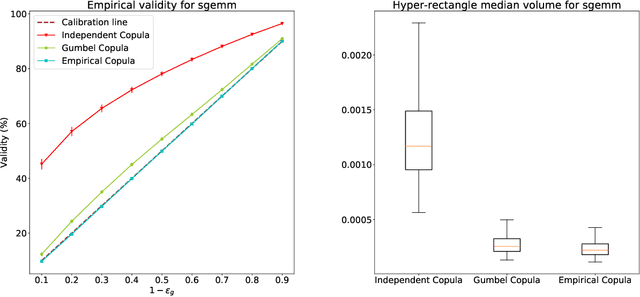
There are relatively few works dealing with conformal prediction for multi-task learning issues, and this is particularly true for multi-target regression. This paper focuses on the problem of providing valid (i.e., frequency calibrated) multi-variate predictions. To do so, we propose to use copula functions applied to deep neural networks for inductive conformal prediction. We show that the proposed method ensures efficiency and validity for multi-target regression problems on various data sets.
From Shallow to Deep Interactions Between Knowledge Representation, Reasoning and Machine Learning (Kay R. Amel group)
Dec 13, 2019This paper proposes a tentative and original survey of meeting points between Knowledge Representation and Reasoning (KRR) and Machine Learning (ML), two areas which have been developing quite separately in the last three decades. Some common concerns are identified and discussed such as the types of used representation, the roles of knowledge and data, the lack or the excess of information, or the need for explanations and causal understanding. Then some methodologies combining reasoning and learning are reviewed (such as inductive logic programming, neuro-symbolic reasoning, formal concept analysis, rule-based representations and ML, uncertainty in ML, or case-based reasoning and analogical reasoning), before discussing examples of synergies between KRR and ML (including topics such as belief functions on regression, EM algorithm versus revision, the semantic description of vector representations, the combination of deep learning with high level inference, knowledge graph completion, declarative frameworks for data mining, or preferences and recommendation). This paper is the first step of a work in progress aiming at a better mutual understanding of research in KRR and ML, and how they could cooperate.