 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeptical binary inferences in multi-label problems with sets of probabilities
Paper and Code
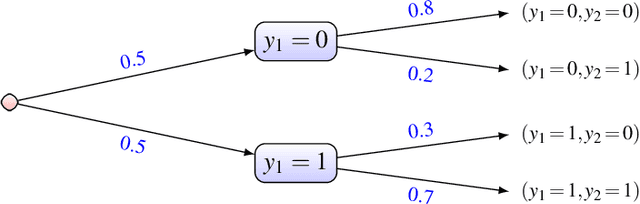

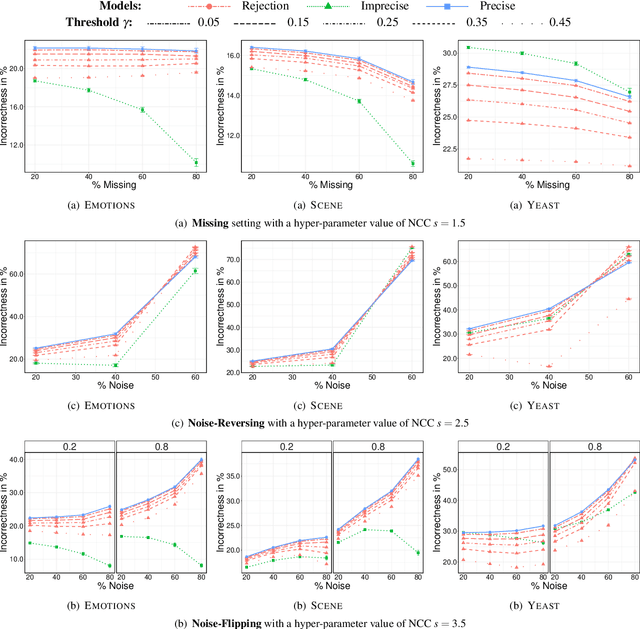
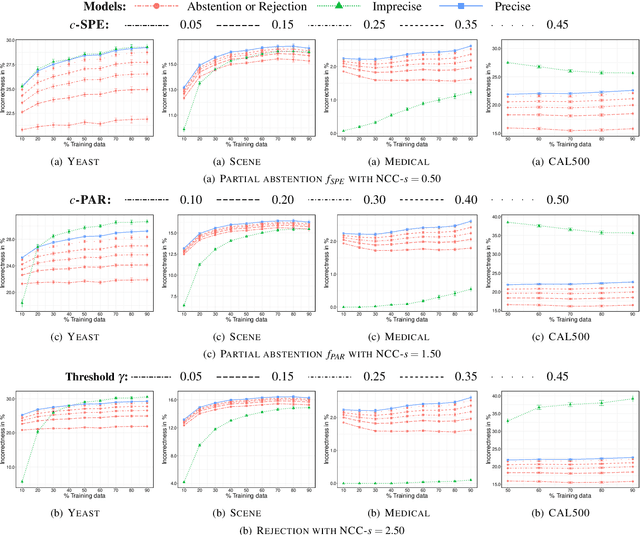
In this paper, we consider the problem of making distributionally robust, skeptical inferences for the multi-label problem, or more generally for Boolean vectors. By distributionally robust, we mean that we consider a set of possible probability distributions, and by skeptical we understand that we consider as valid only those inferences that are true for every distribution within this set. Such inferences will provide partial predictions whenever the considered set is sufficiently big. We study in particular the Hamming loss case, a common loss function in multi-label problems, showing how skeptical inferences can be made in this setting. Our experimental results are organised in three sections; (1) the first one indicates the gain computational obtained from our theoretical results by using synthetical data sets, (2) the second one indicates that our approaches produce relevant cautiousness on those hard-to-predict instances where its precise counterpart fails, and (3) the last one demonstrates experimentally how our approach copes with imperfect information (generated by a downsampling procedure) better than the partial abstention [31] and the rejection rules.