 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-label Chaining with Imprecise Probabilities
Paper and Code
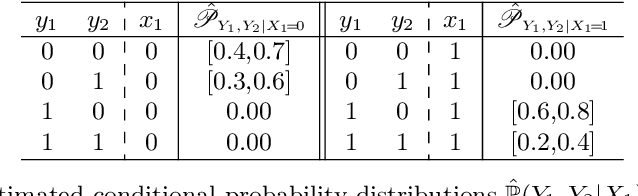
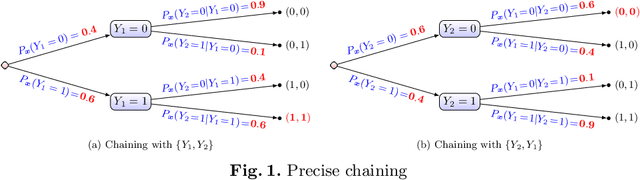
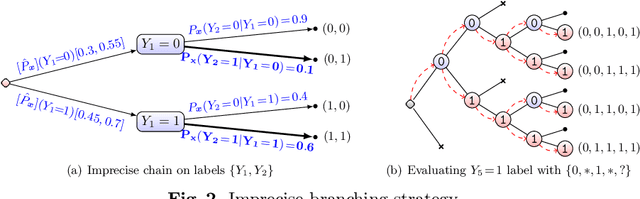
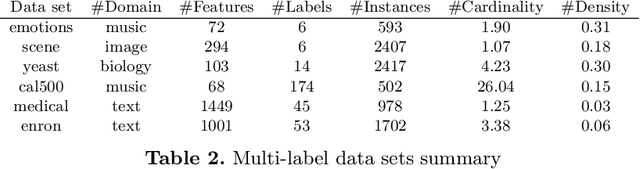
We present two different strategies to extend the classical multi-label chaining approach to handle imprecise probability estimates. These estimates use convex sets of distributions (or credal sets) in order to describe our uncertainty rather than a precise one. The main reasons one could have for using such estimations are (1) to make cautious predictions (or no decision at all) when a high uncertainty is detected in the chaining and (2) to make better precise predictions by avoiding biases caused in early decisions in the chaining. We adapt both strategies to the case of the naive credal classifier, showing that this adaptations are computationally efficient. Our experimental results on missing labels, which investigate how reliable these predictions are in both approaches, indicate that our approaches produce relevant cautiousness on those hard-to-predict instances where the precise models fail.