Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery Focused Multi-document Summarisation of Biomedical Texts
Paper and Code
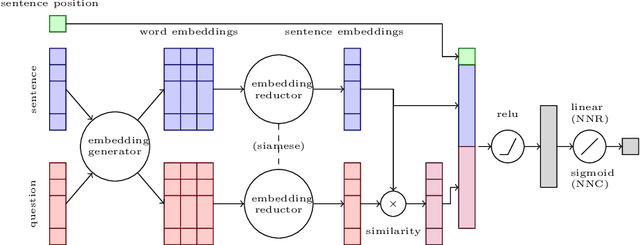
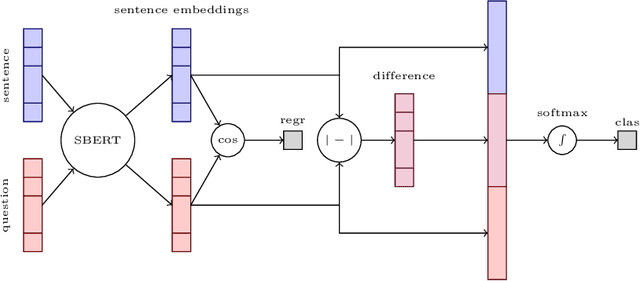
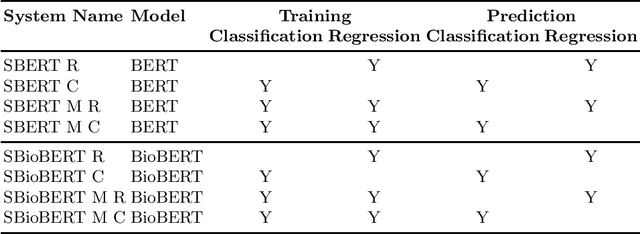
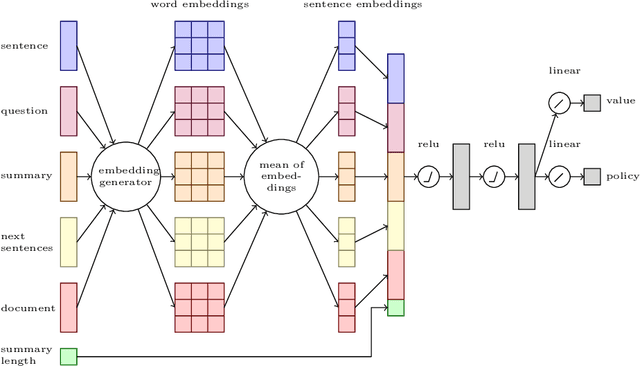
This paper presents the participation of Macquarie University and the Australian National University for Task B Phase B of the 2020 BioASQ Challenge (BioASQ8b). Our overall framework implements Query focused multi-document extractive summarisation by applying either a classification or a regression layer to the candidate sentence embeddings and to the comparison between the question and sentence embeddings. We experiment with variants using BERT and BioBERT, Siamese architectures, and reinforcement learning. We observe the best results when BERT is used to obtain the word embeddings, followed by an LSTM layer to obtain sentence embeddings. Variants using Siamese architectures or BioBERT did not improve the results.
* 14 pages, 7 tables, 3 figures. Accepted at BioASQ workshop, CLEF 2020
View paper on