 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery Focused Multi-document Summarisation of Biomedical Texts
Aug 27, 2020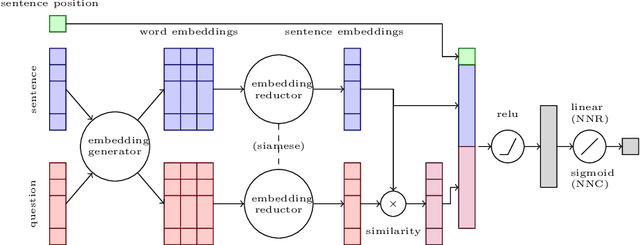
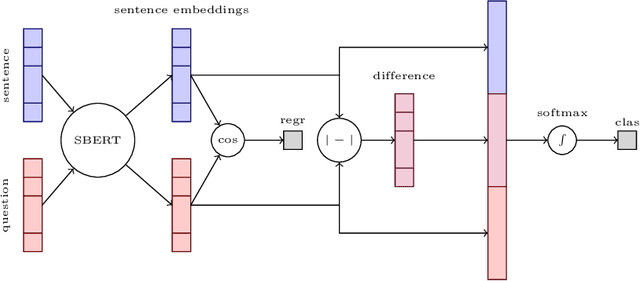
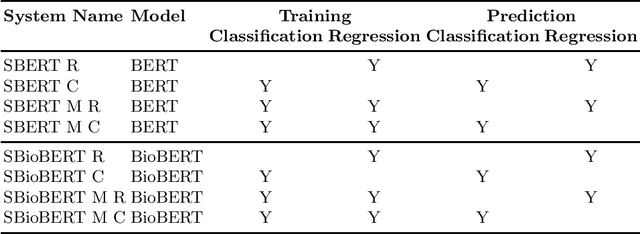
This paper presents the participation of Macquarie University and the Australian National University for Task B Phase B of the 2020 BioASQ Challenge (BioASQ8b). Our overall framework implements Query focused multi-document extractive summarisation by applying either a classification or a regression layer to the candidate sentence embeddings and to the comparison between the question and sentence embeddings. We experiment with variants using BERT and BioBERT, Siamese architectures, and reinforcement learning. We observe the best results when BERT is used to obtain the word embeddings, followed by an LSTM layer to obtain sentence embeddings. Variants using Siamese architectures or BioBERT did not improve the results.
Classification Betters Regression in Query-based Multi-document Summarisation Techniques for Question Answering: Macquarie University at BioASQ7b
Sep 02, 2019



Task B Phase B of the 2019 BioASQ challenge focuses on biomedical question answering. Macquarie University's participation applies query-based multi-document extractive summarisation techniques to generate a multi-sentence answer given the question and the set of relevant snippets. In past participation we explored the use of regression approaches using deep learning architectures and a simple policy gradient architecture. For the 2019 challenge we experiment with the use of classification approaches with and without reinforcement learning. In addition, we conduct a correlation analysis between various ROUGE metrics and the BioASQ human evaluation scores.
Towards the Use of Deep Reinforcement Learning with Global Policy For Query-based Extractive Summarisation
Nov 14, 2017

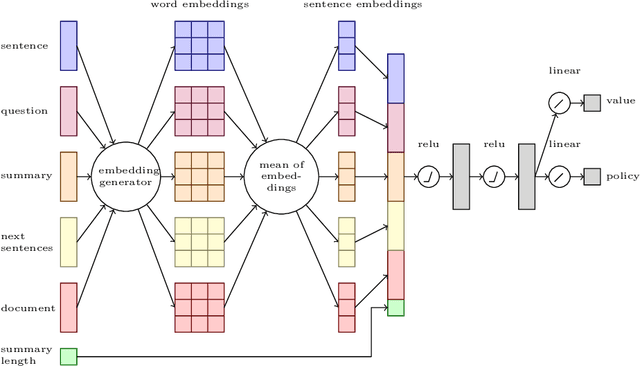
Supervised approaches for text summarisation suffer from the problem of mismatch between the target labels/scores of individual sentences and the evaluation score of the final summary. Reinforcement learning can solve this problem by providing a learning mechanism that uses the score of the final summary as a guide to determine the decisions made at the time of selection of each sentence. In this paper we present a proof-of-concept approach that applies a policy-gradient algorithm to learn a stochastic policy using an undiscounted reward. The method has been applied to a policy consisting of a simple neural network and simple features. The resulting deep reinforcement learning system is able to learn a global policy and obtain encouraging results.
Automated text summarisation and evidence-based medicine: A survey of two domains
Jun 25, 2017
The practice of evidence-based medicine (EBM) urges medical practitioners to utilise the latest research evidence when making clinical decisions. Because of the massive and growing volume of published research on various medical topics, practitioners often find themselves overloaded with information. As such, natural language processing research has recently commenced exploring techniques for performing medical domain-specific automated text summarisation (ATS) techniques-- targeted towards the task of condensing large medical texts. However, the development of effective summarisation techniques for this task requires cross-domain knowledge. We present a survey of EBM, the domain-specific needs for EBM, automated summarisation techniques, and how they have been applied hitherto. We envision that this survey will serve as a first resource for the development of future operational text summarisation techniques for EBM.