 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery Focused Multi-document Summarisation of Biomedical Texts
Aug 27, 2020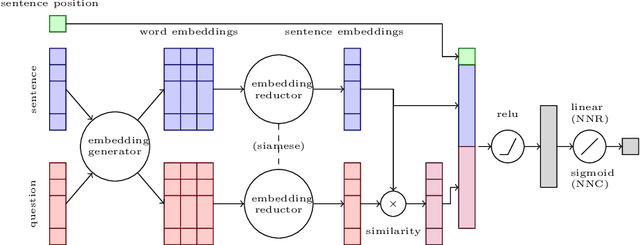
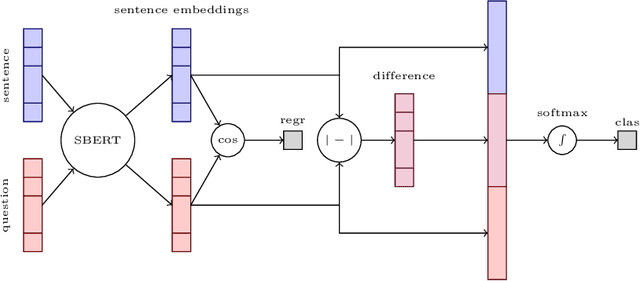
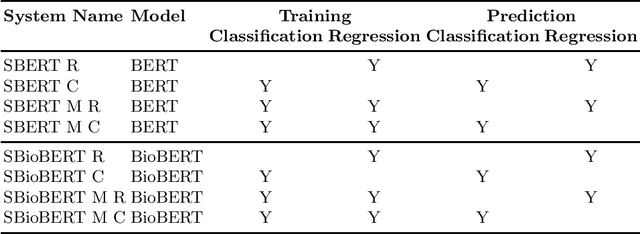
This paper presents the participation of Macquarie University and the Australian National University for Task B Phase B of the 2020 BioASQ Challenge (BioASQ8b). Our overall framework implements Query focused multi-document extractive summarisation by applying either a classification or a regression layer to the candidate sentence embeddings and to the comparison between the question and sentence embeddings. We experiment with variants using BERT and BioBERT, Siamese architectures, and reinforcement learning. We observe the best results when BERT is used to obtain the word embeddings, followed by an LSTM layer to obtain sentence embeddings. Variants using Siamese architectures or BioBERT did not improve the results.
Classification Betters Regression in Query-based Multi-document Summarisation Techniques for Question Answering: Macquarie University at BioASQ7b
Sep 02, 2019



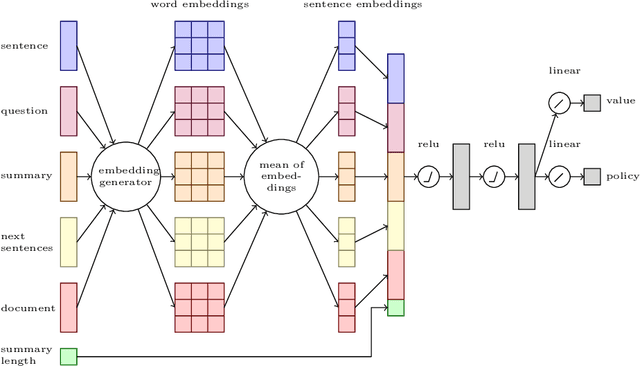
Task B Phase B of the 2019 BioASQ challenge focuses on biomedical question answering. Macquarie University's participation applies query-based multi-document extractive summarisation techniques to generate a multi-sentence answer given the question and the set of relevant snippets. In past participation we explored the use of regression approaches using deep learning architectures and a simple policy gradient architecture. For the 2019 challenge we experiment with the use of classification approaches with and without reinforcement learning. In addition, we conduct a correlation analysis between various ROUGE metrics and the BioASQ human evaluation scores.