 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Induced Deep Q-Network for a Slide-to-Wall Object Grasping
Paper and Code
Oct 09, 2019
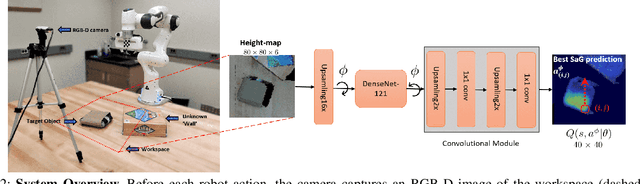

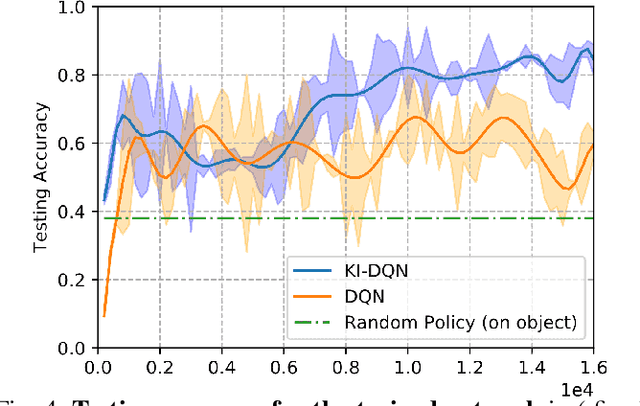
In robotic grasping tasks, robots usually avoid any collisions with the environment and exclusively interact with the target objects. However, the environment can facilitate grasping rather than being obstacles. Indeed, interacting with the environment sometimes provides an alternative strategy when it is not possible to grasp from the top. One example of such tasks is the Slide-to-Wall grasping, where the target object needs to be pushed towards a wall before a feasible grasp can be applied. In this paper, we propose an approach that actively exploits the environment to grasp objects. We formulate the Slide-to-Wall grasping problem as a Markov Decision Process and propose a reinforcement learning approach. Though a standard Deep Q-Network (DQN) method is capable of solving MDP problems, it does not effectively generalize to unseen environment settings that are different from training. To tackle the generalization challenge, we propose a Knowledge Induced DQN (KI-DQN) that not only trains more effectively, but also outperforms the standard DQN significantly in testing cases with unseen walls, and can be directly tested on real robots without fine-tuning while DQN cannot.