 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Learning Approach to Grasping the Invisible
Paper and Code
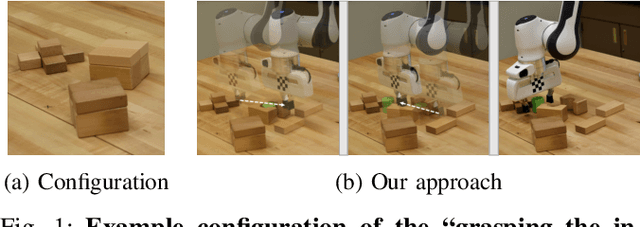

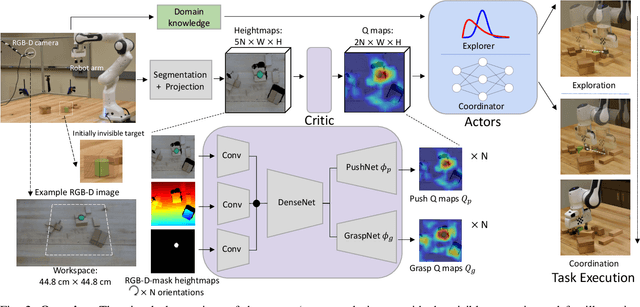
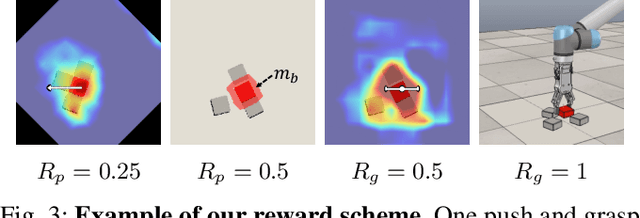
We introduce a new problem named "grasping the invisible", where a robot is tasked to grasp an initially invisible target object via a sequence of non-prehensile (e.g., pushing) and prehensile (e.g., grasping) actions. In this problem, non-prehensile actions are needed to search for the target and rearrange cluttered objects around it. We propose to solve the problem by formulating a deep reinforcement learning approach in an actor-critic format. A critic that maps both the visual observations and the target information to expected rewards of actions is learned via deep Q-learning for instance pushing and grasping. Two actors are proposed to take in the critic predictions and the domain knowledge for two subtasks: a Bayesian-based actor accounting for past experience performs explorational pushing to search for the target; once the target is found, a classifier-based actor coordinates the target-oriented pushing and grasping to grasp the target in clutter. The model is entirely self-supervised through the robot-environment interactions. Our system achieves 93% and 87% task success rate on the two subtasks in simulation and 85% task success rate in real robot experiments, which outperforms several baselines by large margins. Supplementary material is available at: https://sites.google.com/umn.edu/grasping-invisible.