 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Demosaicing and Denoising with Double Deep Image Priors
Sep 18, 2023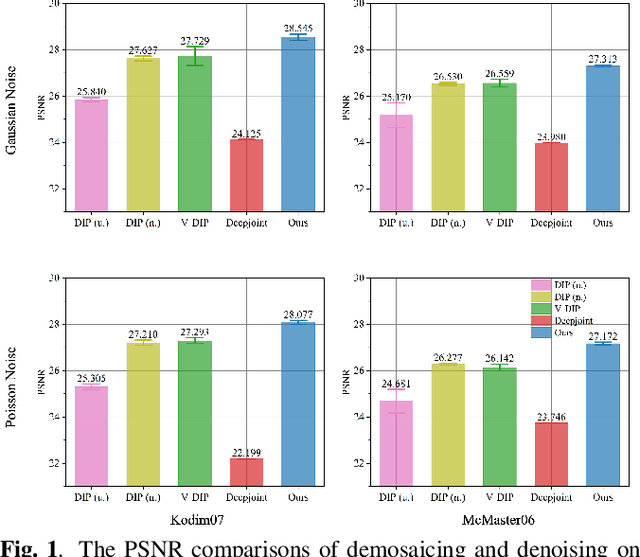
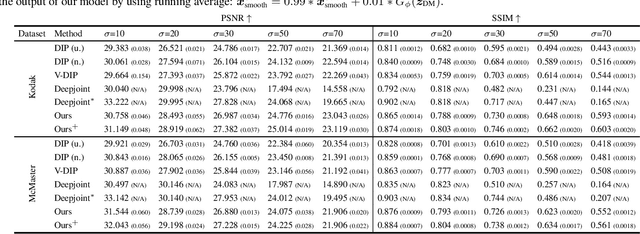
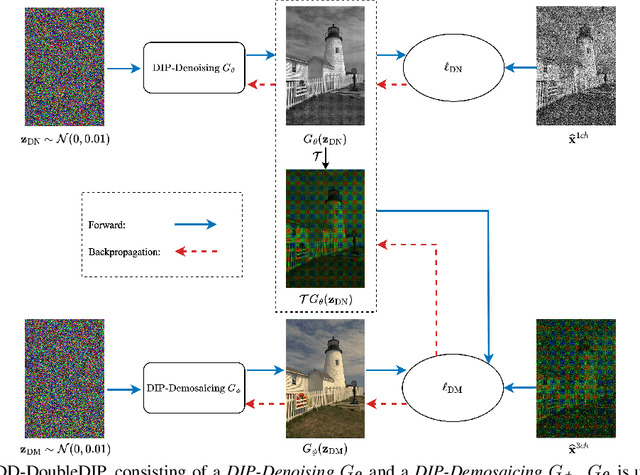
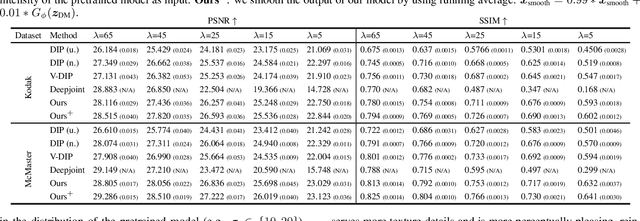
Demosaicing and denoising of RAW images are crucial steps in the processing pipeline of modern digital cameras. As only a third of the color information required to produce a digital image is captured by the camera sensor, the process of demosaicing is inherently ill-posed. The presence of noise further exacerbates this problem. Performing these two steps sequentially may distort the content of the captured RAW images and accumulate errors from one step to another. Recent deep neural-network-based approaches have shown the effectiveness of joint demosaicing and denoising to mitigate such challenges. However, these methods typically require a large number of training samples and do not generalize well to different types and intensities of noise. In this paper, we propose a novel joint demosaicing and denoising method, dubbed JDD-DoubleDIP, which operates directly on a single RAW image without requiring any training data. We validate the effectiveness of our method on two popular datasets -- Kodak and McMaster -- with various noises and noise intensities. The experimental results show that our method consistently outperforms other compared methods in terms of PSNR, SSIM, and qualitative visual perception.
Adaptive Local Neighborhood-based Neural Networks for MR Image Reconstruction from Undersampled Data
Jun 01, 2022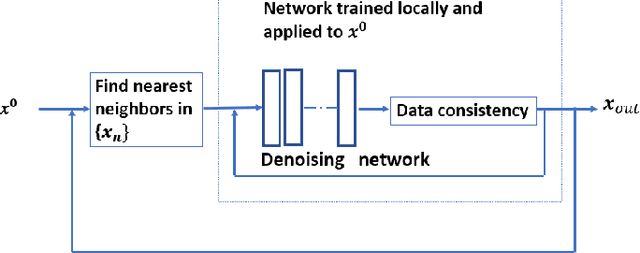

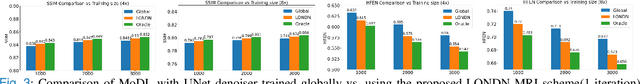
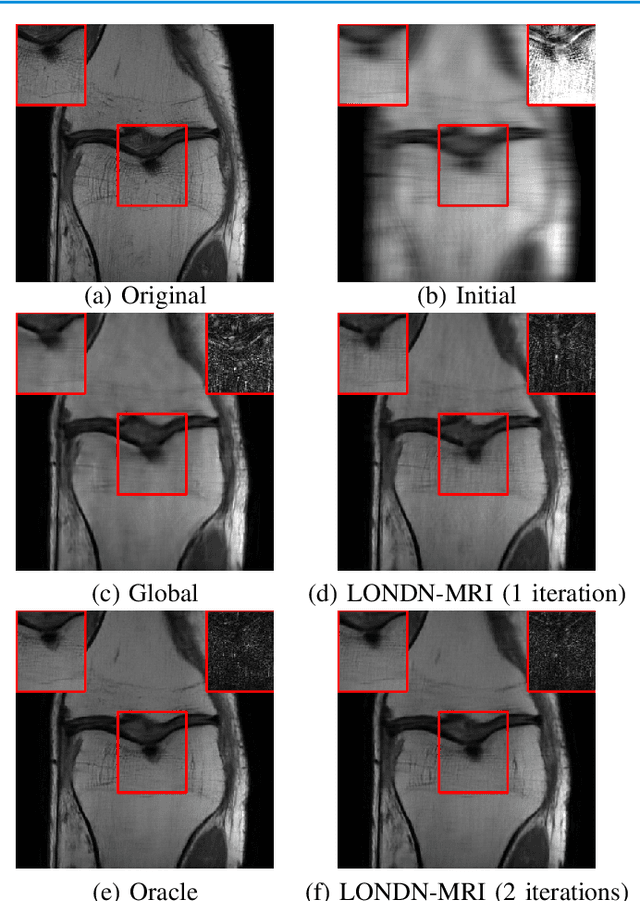
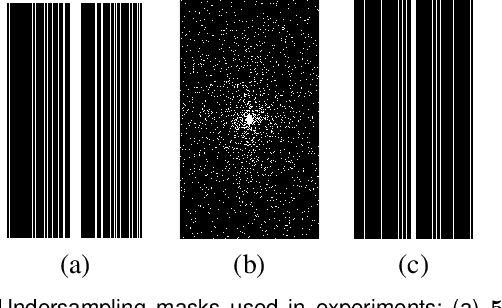
Recent medical image reconstruction techniques focus on generating high-quality medical images suitable for clinical use at the lowest possible cost and with the fewest possible adverse effects on patients. Recent works have shown significant promise for reconstructing MR images from sparsely sampled k-space data using deep learning. In this work, we propose a technique that rapidly estimates deep neural networks directly at reconstruction time by fitting them on small adaptively estimated neighborhoods of a training set. In brief, our algorithm alternates between searching for neighbors in a data set that are similar to the test reconstruction, and training a local network on these neighbors followed by updating the test reconstruction. Because our reconstruction model is learned on a dataset that is structurally similar to the image being reconstructed rather than being fit on a large, diverse training set, it is more adaptive to new scans. It can also handle changes in training sets and flexible scan settings, while being relatively fast. Our approach, dubbed LONDN-MRI, was validated on the FastMRI multi-coil knee data set using deep unrolled reconstruction networks. Reconstructions were performed at four fold and eight fold undersampling of k-space with 1D variable-density random phase-encode undersampling masks. Our results demonstrate that our proposed locally-trained method produces higher-quality reconstructions compared to models trained globally on larger datasets.
Sparse-view Cone Beam CT Reconstruction using Data-consistent Supervised and Adversarial Learning from Scarce Training Data
Jan 23, 2022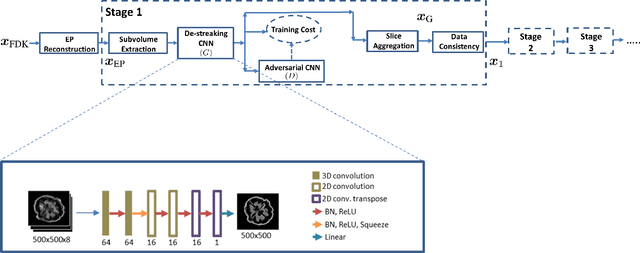
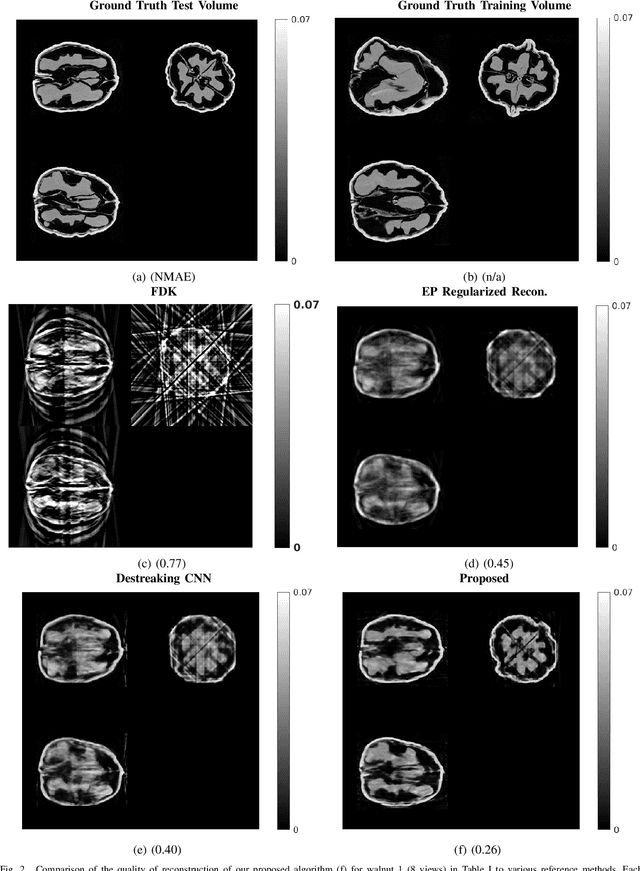

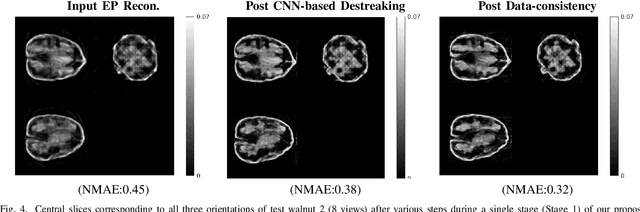
Reconstruction of CT images from a limited set of projections through an object is important in several applications ranging from medical imaging to industrial settings. As the number of available projections decreases, traditional reconstruction techniques such as the FDK algorithm and model-based iterative reconstruction methods perform poorly. Recently, data-driven methods such as deep learning-based reconstruction have garnered a lot of attention in applications because they yield better performance when enough training data is available. However, even these methods have their limitations when there is a scarcity of available training data. This work focuses on image reconstruction in such settings, i.e., when both the number of available CT projections and the training data is extremely limited. We adopt a sequential reconstruction approach over several stages using an adversarially trained shallow network for 'destreaking' followed by a data-consistency update in each stage. To deal with the challenge of limited data, we use image subvolumes to train our method, and patch aggregation during testing. To deal with the computational challenge of learning on 3D datasets for 3D reconstruction, we use a hybrid 3D-to-2D mapping network for the 'destreaking' part. Comparisons to other methods over several test examples indicate that the proposed method has much potential, when both the number of projections and available training data are highly limited.
Blind Primed Supervised Learning for MR Image Reconstruction
Apr 11, 2021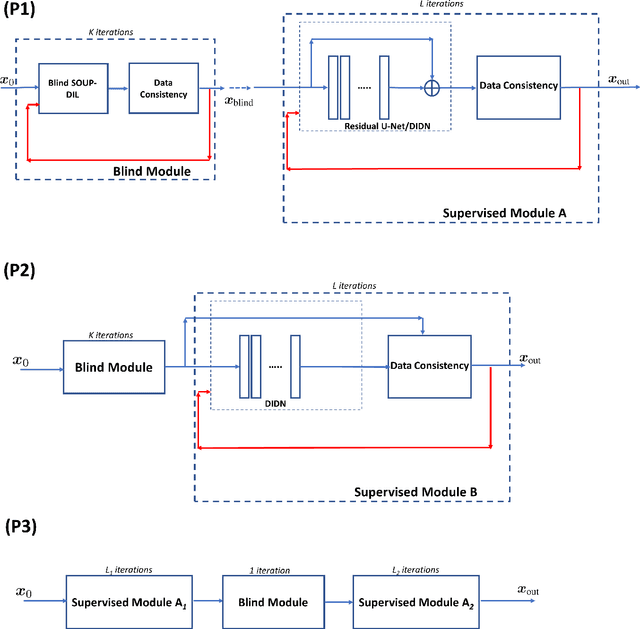
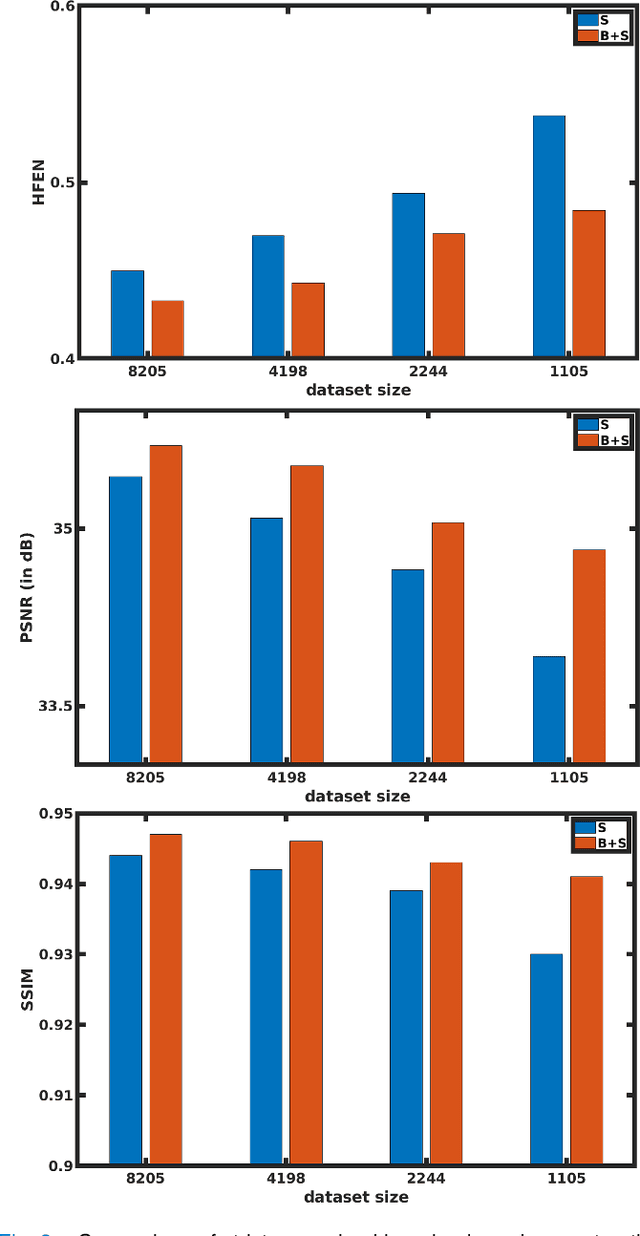
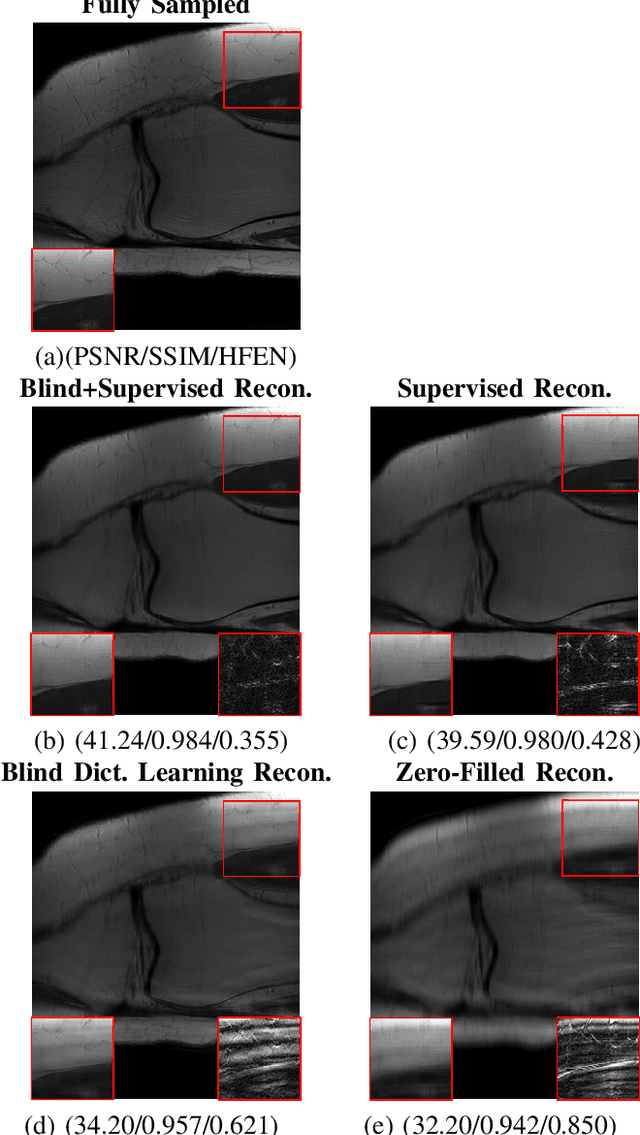
This paper examines a combined supervised-unsupervised framework involving dictionary-based blind learning and deep supervised learning for MR image reconstruction from under-sampled k-space data. A major focus of the work is to investigate the possible synergy of learned features in traditional shallow reconstruction using adaptive sparsity-based priors and deep prior-based reconstruction. Specifically, we propose a framework that uses an unrolled network to refine a blind dictionary learning-based reconstruction. We compare the proposed method with strictly supervised deep learning-based reconstruction approaches on several datasets of varying sizes and anatomies. We also compare the proposed method to alternative approaches for combining dictionary-based methods with supervised learning in MR image reconstruction. The improvements yielded by the proposed framework suggest that the blind dictionary-based approach preserves fine image details that the supervised approach can iteratively refine, suggesting that the features learned using the two methods are complementary
Optimizing MRF-ASL Scan Design for Precise Quantification of Brain Hemodynamics using Neural Network Regression
May 15, 2019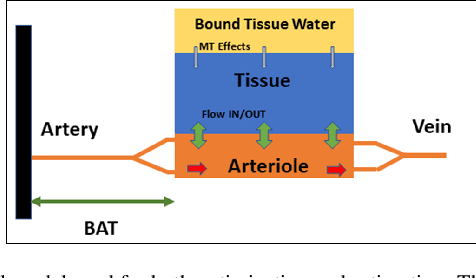
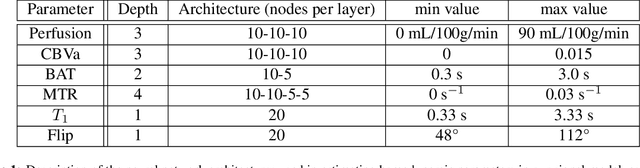
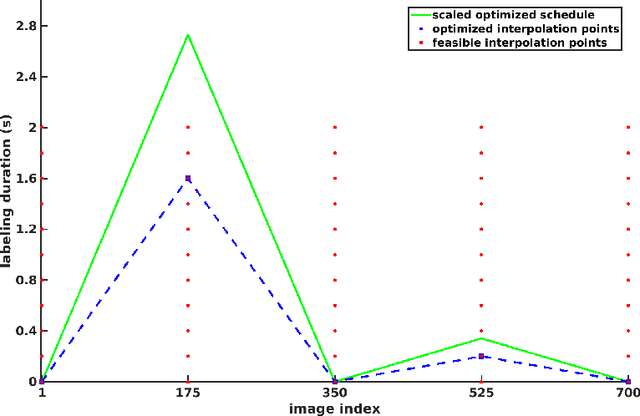
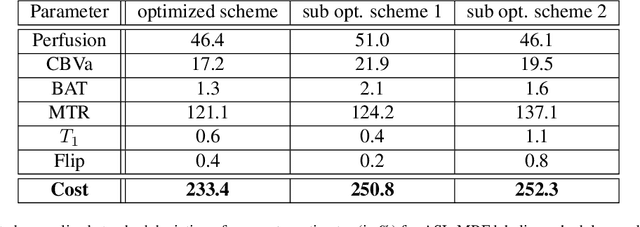
Purpose: Arterial Spin Labeling (ASL) is a quantitative, non-invasive alternative to perfusion imaging with contrast agents. Fixing values of certain model parameters in traditional ASL, which actually vary from region to region, may introduce bias in perfusion estimates. Adopting Magnetic Resonance Fingerprinting (MRF) for ASL is an alternative where these parameters are estimated alongside perfusion, but multiparametric estimation can degrade precision. We aim to improve the sensitivity of ASL-MRF signals to underlying parameters to counter this problem, and provide precise estimates. We also propose a regression based estimation framework for MRF-ASL. Methods: To improve the sensitivity of MRF-ASL signals to underlying parameters, we optimize ASL labeling durations using the Cramer-Rao Lower Bound (CRLB). This paper also proposes a neural network regression based estimation framework trained using noisy synthetic signals generated from our ASL signal model. Results: We test our methods in silico and in vivo, and compare with multiple post labeling delay (multi-PLD) ASL and unoptimized MRF-ASL. We present comparisons of estimated maps for six parameters accounted for in our signal model. Conclusions: The scan design process facilitates precise estimates of multiple hemodynamic parameters and tissue properties from a single scan, in regions of gray and white matter, as well as regions with anomalous perfusion activity in the brain. The regression based estimation approach provides perfusion estimates rapidly, and bypasses problems with quantization error. Keywords: Arterial Spin Labeling, Magnetic Resonance Fingerprinting, Optimization, Cramer-Rao Bound, Scan Design, Regression, Neural Networks, Deep Learning, Precision, Estimation, Brain Hemodynamics.