 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoleRMBench & RoleRM: Towards Reward Modeling for Profile-Based Role Play in Dialogue Systems
Dec 11, 2025Reward modeling has become a cornerstone of aligning large language models (LLMs) with human preferences. Yet, when extended to subjective and open-ended domains such as role play, existing reward models exhibit severe degradation, struggling to capture nuanced and persona-grounded human judgments. To address this gap, we introduce RoleRMBench, the first systematic benchmark for reward modeling in role-playing dialogue, covering seven fine-grained capabilities from narrative management to role consistency and engagement. Evaluation on RoleRMBench reveals large and consistent gaps between general-purpose reward models and human judgment, particularly in narrative and stylistic dimensions. We further propose RoleRM, a reward model trained with Continuous Implicit Preferences (CIP), which reformulates subjective evaluation as continuous consistent pairwise supervision under multiple structuring strategies. Comprehensive experiments show that RoleRM surpasses strong open- and closed-source reward models by over 24% on average, demonstrating substantial gains in narrative coherence and stylistic fidelity. Our findings highlight the importance of continuous preference representation and annotation consistency, establishing a foundation for subjective alignment in human-centered dialogue systems.
S$^3$Attention: Improving Long Sequence Attention with Smoothed Skeleton Sketching
Aug 16, 2024Attention based models have achieved many remarkable breakthroughs in numerous applications. However, the quadratic complexity of Attention makes the vanilla Attention based models hard to apply to long sequence tasks. Various improved Attention structures are proposed to reduce the computation cost by inducing low rankness and approximating the whole sequence by sub-sequences. The most challenging part of those approaches is maintaining the proper balance between information preservation and computation reduction: the longer sub-sequences used, the better information is preserved, but at the price of introducing more noise and computational costs. In this paper, we propose a smoothed skeleton sketching based Attention structure, coined S$^3$Attention, which significantly improves upon the previous attempts to negotiate this trade-off. S$^3$Attention has two mechanisms to effectively minimize the impact of noise while keeping the linear complexity to the sequence length: a smoothing block to mix information over long sequences and a matrix sketching method that simultaneously selects columns and rows from the input matrix. We verify the effectiveness of S$^3$Attention both theoretically and empirically. Extensive studies over Long Range Arena (LRA) datasets and six time-series forecasting show that S$^3$Attention significantly outperforms both vanilla Attention and other state-of-the-art variants of Attention structures.
Online Influence Maximization under Decreasing Cascade Model
May 19, 2023


We study online influence maximization (OIM) under a new model of decreasing cascade (DC). This model is a generalization of the independent cascade (IC) model by considering the common phenomenon of market saturation. In DC, the chance of an influence attempt being successful reduces with previous failures. The effect is neglected by previous OIM works under IC and linear threshold models. We propose the DC-UCB algorithm to solve this problem, which achieves a regret bound of the same order as the state-of-the-art works on the IC model. Extensive experiments on both synthetic and real datasets show the effectiveness of our algorithm.
FiLM: Frequency improved Legendre Memory Model for Long-term Time Series Forecasting
May 24, 2022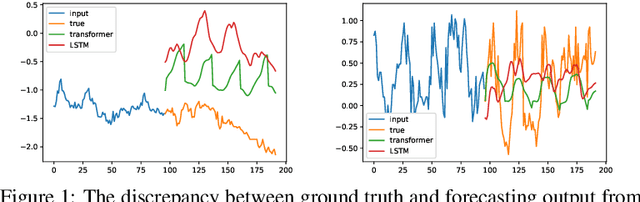
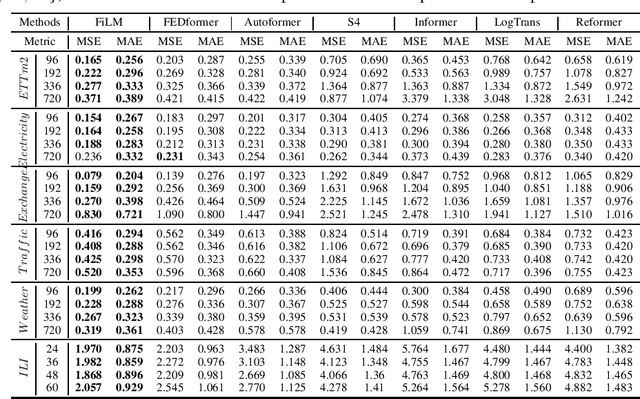
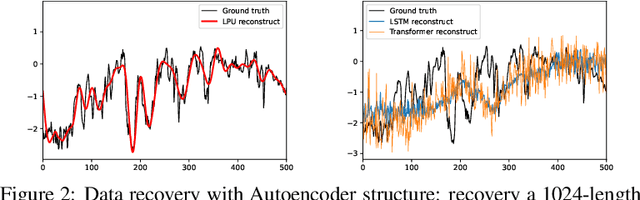
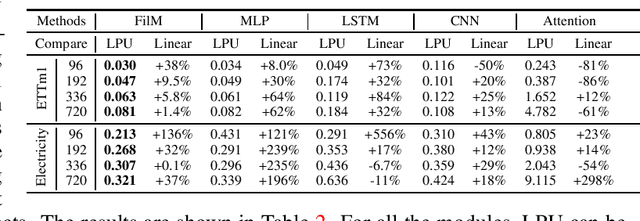
Recent studies have shown that deep learning models such as RNNs and Transformers have brought significant performance gains for long-term forecasting of time series because they effectively utilize historical information. We found, however, that there is still great room for improvement in how to preserve historical information in neural networks while avoiding overfitting to noise presented in the history. Addressing this allows better utilization of the capabilities of deep learning models. To this end, we design a \textbf{F}requency \textbf{i}mproved \textbf{L}egendre \textbf{M}emory model, or {\bf FiLM}: it applies Legendre Polynomials projections to approximate historical information, uses Fourier projection to remove noise, and adds a low-rank approximation to speed up computation. Our empirical studies show that the proposed FiLM significantly improves the accuracy of state-of-the-art models in multivariate and univariate long-term forecasting by (\textbf{20.3\%}, \textbf{22.6\%}), respectively. We also demonstrate that the representation module developed in this work can be used as a general plug-in to improve the long-term prediction performance of other deep learning modules. Code will be released soon.
Developing Univariate Neurodegeneration Biomarkers with Low-Rank and Sparse Subspace Decomposition
Oct 26, 2020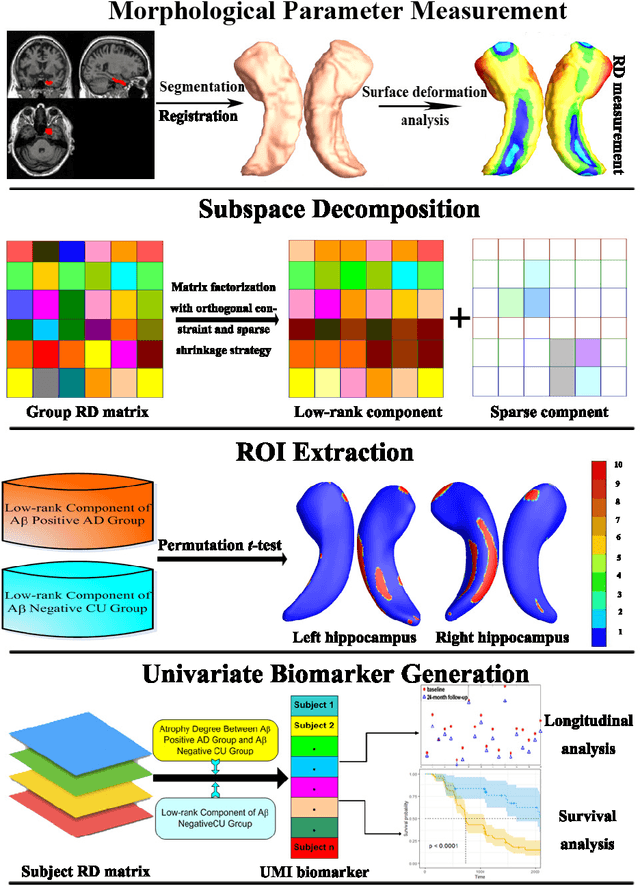

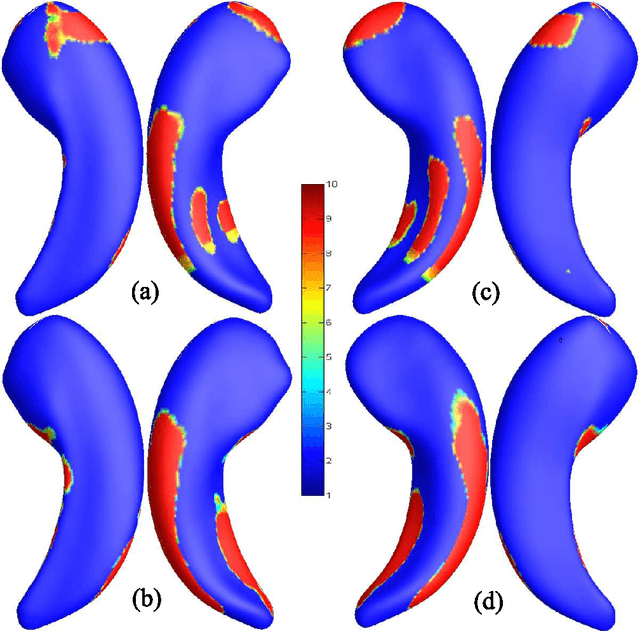

Cognitive decline due to Alzheimer's disease (AD) is closely associated with brain structure alterations captured by structural magnetic resonance imaging (sMRI). It supports the validity to develop sMRI-based univariate neurodegeneration biomarkers (UNB). However, existing UNB work either fails to model large group variances or does not capture AD dementia (ADD) induced changes. We propose a novel low-rank and sparse subspace decomposition method capable of stably quantifying the morphological changes induced by ADD. Specifically, we propose a numerically efficient rank minimization mechanism to extract group common structure and impose regularization constraints to encode the original 3D morphometry connectivity. Further, we generate regions-of-interest (ROI) with group difference study between common subspaces of $A\beta+$ AD and $A\beta-$ cognitively unimpaired (CU) groups. A univariate morphometry index (UMI) is constructed from these ROIs by summarizing individual morphological characteristics weighted by normalized difference between $A\beta+$ AD and $A\beta-$ CU groups. We use hippocampal surface radial distance feature to compute the UMIs and validate our work in the Alzheimer's Disease Neuroimaging Initiative (ADNI) cohort. With hippocampal UMIs, the estimated minimum sample sizes needed to detect a 25$\%$ reduction in the mean annual change with 80$\%$ power and two-tailed $P=0.05$ are 116, 279 and 387 for the longitudinal $A\beta+$ AD, $A\beta+$ mild cognitive impairment (MCI) and $A\beta+$ CU groups, respectively. Additionally, for MCI patients, UMIs well correlate with hazard ratio of conversion to AD ($4.3$, $95\%$ CI=$2.3-8.2$) within 18 months. Our experimental results outperform traditional hippocampal volume measures and suggest the application of UMI as a potential UNB.
Efficient Discrete Supervised Hashing for Large-scale Cross-modal Retrieval
May 03, 2019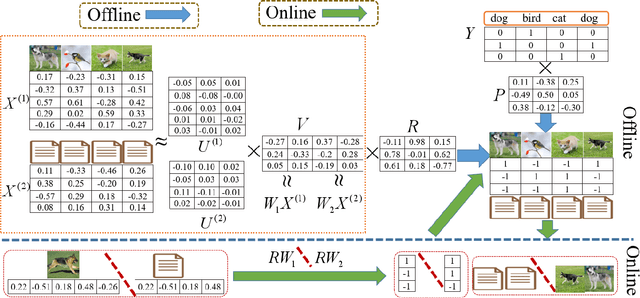
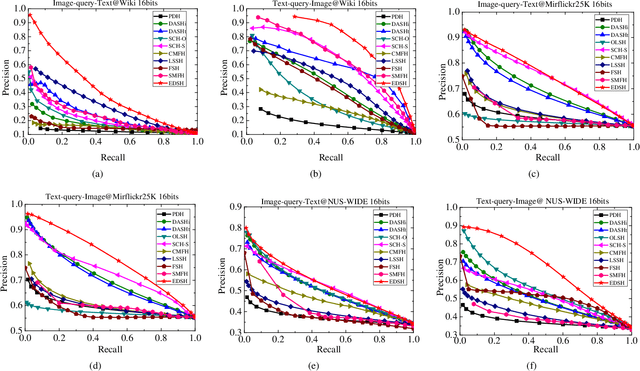

Supervised cross-modal hashing has gained increasing research interest on large-scale retrieval task owning to its satisfactory performance and efficiency. However, it still has some challenging issues to be further studied: 1) most of them fail to well preserve the semantic correlations in hash codes because of the large heterogenous gap; 2) most of them relax the discrete constraint on hash codes, leading to large quantization error and consequent low performance; 3) most of them suffer from relatively high memory cost and computational complexity during training procedure, which makes them unscalable. In this paper, to address above issues, we propose a supervised cross-modal hashing method based on matrix factorization dubbed Efficient Discrete Supervised Hashing (EDSH). Specifically, collective matrix factorization on heterogenous features and semantic embedding with class labels are seamlessly integrated to learn hash codes. Therefore, the feature based similarities and semantic correlations can be both preserved in hash codes, which makes the learned hash codes more discriminative. Then an efficient discrete optimal algorithm is proposed to handle the scalable issue. Instead of learning hash codes bit-by-bit, hash codes matrix can be obtained directly which is more efficient. Extensive experimental results on three public real-world datasets demonstrate that EDSH produces a superior performance in both accuracy and scalability over some existing cross-modal hashing methods.
Online Learning and Decision-Making under Generalized Linear Model with High-Dimensional Data
Dec 07, 2018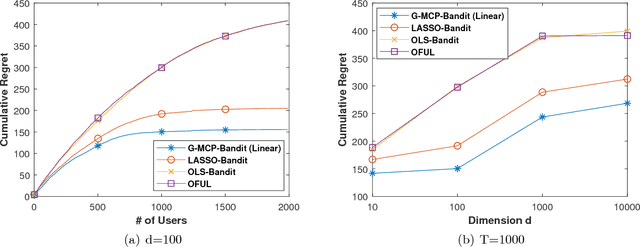

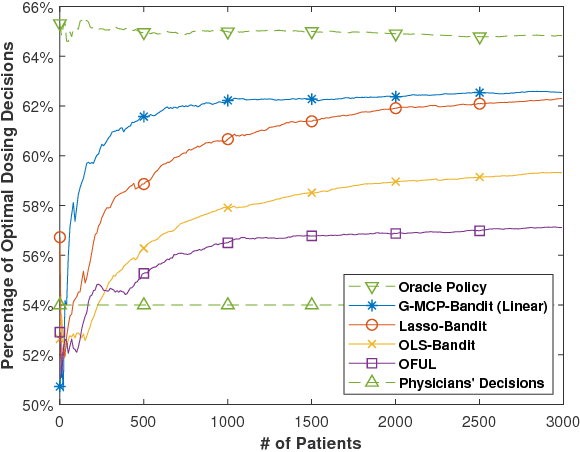

We propose a minimax concave penalized multi-armed bandit algorithm under generalized linear model (G-MCP-Bandit) for a decision-maker facing high-dimensional data in an online learning and decision-making process. We demonstrate that the G-MCP-Bandit algorithm asymptotically achieves the optimal cumulative regret in the sample size dimension T , O(log T), and further attains a tight bound in the covariate dimension d, O(log d). In addition, we develop a linear approximation method, the 2-step weighted Lasso procedure, to identify the MCP estimator for the G-MCP-Bandit algorithm under non-iid samples. Under this procedure, the MCP estimator matches the oracle estimator with high probability and converges to the true parameters with the optimal convergence rate. Finally, through experiments based on synthetic data and two real datasets (warfarin dosing dataset and Tencent search advertising dataset), we show that the G-MCP-Bandit algorithm outperforms other benchmark algorithms, especially when there is a high level of data sparsity or the decision set is large.