 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Discrete Supervised Hashing for Large-scale Cross-modal Retrieval
May 03, 2019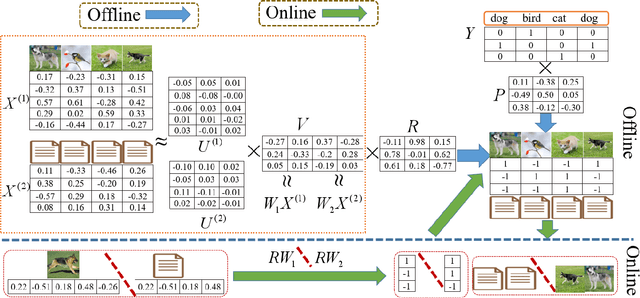
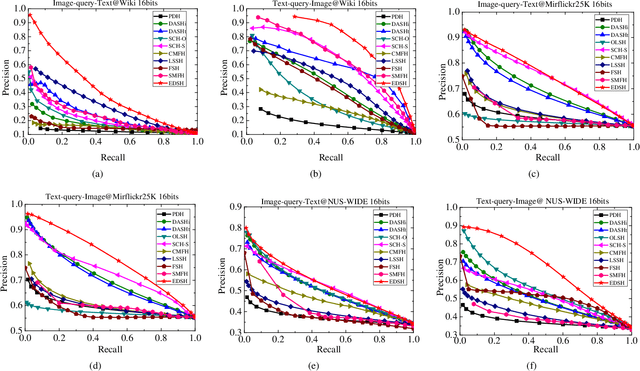

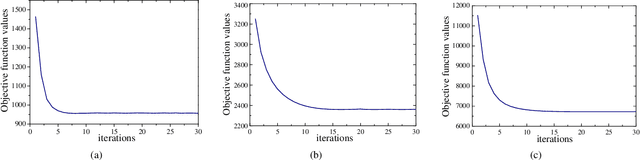
Supervised cross-modal hashing has gained increasing research interest on large-scale retrieval task owning to its satisfactory performance and efficiency. However, it still has some challenging issues to be further studied: 1) most of them fail to well preserve the semantic correlations in hash codes because of the large heterogenous gap; 2) most of them relax the discrete constraint on hash codes, leading to large quantization error and consequent low performance; 3) most of them suffer from relatively high memory cost and computational complexity during training procedure, which makes them unscalable. In this paper, to address above issues, we propose a supervised cross-modal hashing method based on matrix factorization dubbed Efficient Discrete Supervised Hashing (EDSH). Specifically, collective matrix factorization on heterogenous features and semantic embedding with class labels are seamlessly integrated to learn hash codes. Therefore, the feature based similarities and semantic correlations can be both preserved in hash codes, which makes the learned hash codes more discriminative. Then an efficient discrete optimal algorithm is proposed to handle the scalable issue. Instead of learning hash codes bit-by-bit, hash codes matrix can be obtained directly which is more efficient. Extensive experimental results on three public real-world datasets demonstrate that EDSH produces a superior performance in both accuracy and scalability over some existing cross-modal hashing methods.
Pseudo-positive regularization for deep person re-identification
Nov 17, 2017
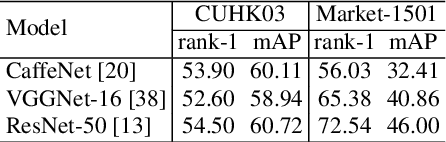

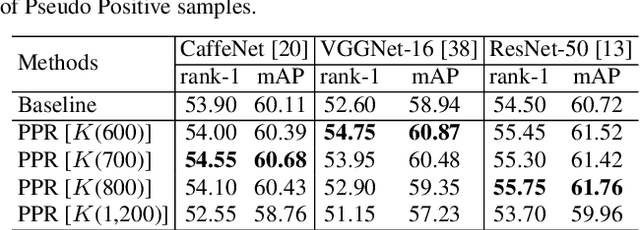
An intrinsic challenge of person re-identification (re-ID) is the annotation difficulty. This typically means 1) few training samples per identity, and 2) thus the lack of diversity among the training samples. Consequently, we face high risk of over-fitting when training the convolutional neural network (CNN), a state-of-the-art method in person re-ID. To reduce the risk of over-fitting, this paper proposes a Pseudo Positive Regularization (PPR) method to enrich the diversity of the training data. Specifically, unlabeled data from an independent pedestrian database is retrieved using the target training data as query. A small proportion of these retrieved samples are randomly selected as the Pseudo Positive samples and added to the target training set for the supervised CNN training. The addition of Pseudo Positive samples is therefore a data augmentation method to reduce the risk of over-fitting during CNN training. We implement our idea in the identification CNN models (i.e., CaffeNet, VGGNet-16 and ResNet-50). On CUHK03 and Market-1501 datasets, experimental results demonstrate that the proposed method consistently improves the baseline and yields competitive performance to the state-of-the-art person re-ID methods.
Part-based Deep Hashing for Large-scale Person Re-identification
May 05, 2017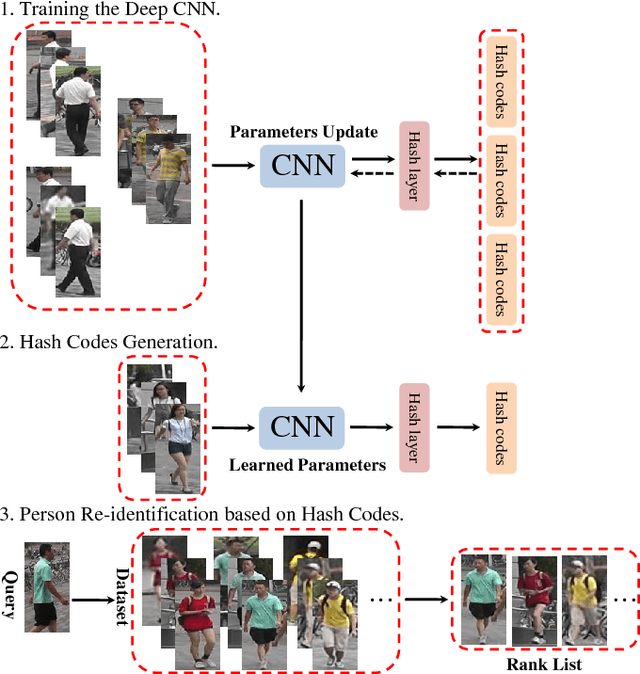


Large-scale is a trend in person re-identification (re-id). It is important that real-time search be performed in a large gallery. While previous methods mostly focus on discriminative learning, this paper makes the attempt in integrating deep learning and hashing into one framework to evaluate the efficiency and accuracy for large-scale person re-id. We integrate spatial information for discriminative visual representation by partitioning the pedestrian image into horizontal parts. Specifically, Part-based Deep Hashing (PDH) is proposed, in which batches of triplet samples are employed as the input of the deep hashing architecture. Each triplet sample contains two pedestrian images (or parts) with the same identity and one pedestrian image (or part) of the different identity. A triplet loss function is employed with a constraint that the Hamming distance of pedestrian images (or parts) with the same identity is smaller than ones with the different identity. In the experiment, we show that the proposed Part-based Deep Hashing method yields very competitive re-id accuracy on the large-scale Market-1501 and Market-1501+500K datasets.