 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikingSSMs: Learning Long Sequences with Sparse and Parallel Spiking State Space Models
Aug 27, 2024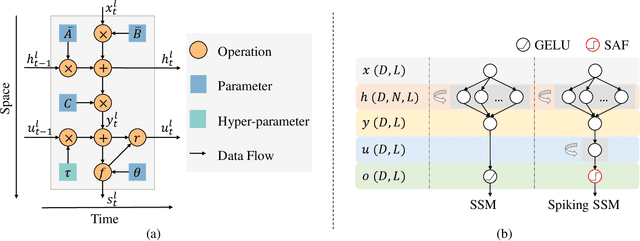
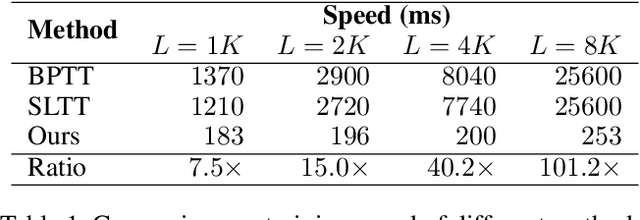
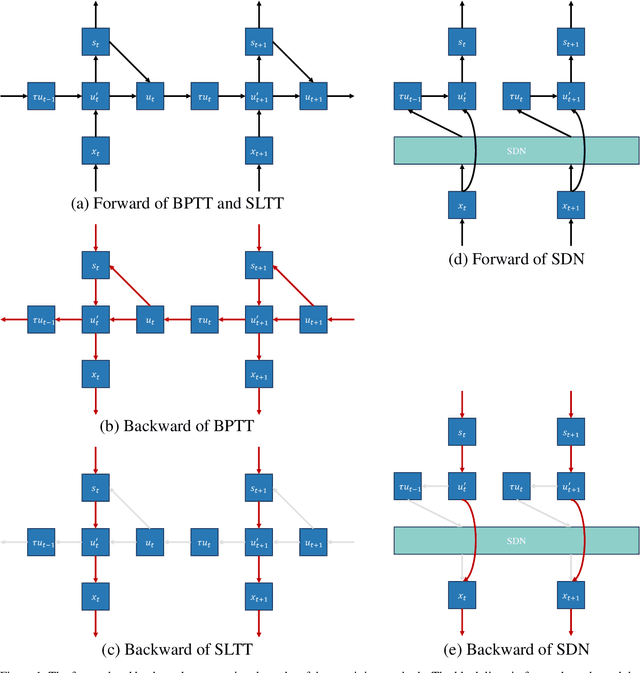
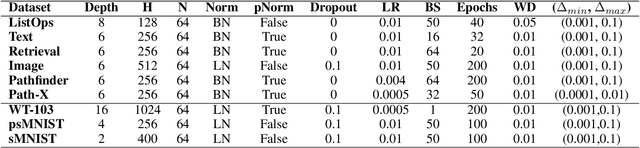
Known as low energy consumption networks, spiking neural networks (SNNs) have gained a lot of attention within the past decades. While SNNs are increasing competitive with artificial neural networks (ANNs) for vision tasks, they are rarely used for long sequence tasks, despite their intrinsic temporal dynamics. In this work, we develop spiking state space models (SpikingSSMs) for long sequence learning by leveraging on the sequence learning abilities of state space models (SSMs). Inspired by dendritic neuron structure, we hierarchically integrate neuronal dynamics with the original SSM block, meanwhile realizing sparse synaptic computation. Furthermore, to solve the conflict of event-driven neuronal dynamics with parallel computing, we propose a light-weight surrogate dynamic network which accurately predicts the after-reset membrane potential and compatible to learnable thresholds, enabling orders of acceleration in training speed compared with conventional iterative methods. On the long range arena benchmark task, SpikingSSM achieves competitive performance to state-of-the-art SSMs meanwhile realizing on average 90\% of network sparsity. On language modeling, our network significantly surpasses existing spiking large language models (spikingLLMs) on the WikiText-103 dataset with only a third of the model size, demonstrating its potential as backbone architecture for low computation cost LLMs.
Evolutionary Spiking Neural Networks: A Survey
Jun 18, 2024Spiking neural networks (SNNs) are gaining increasing attention as potential computationally efficient alternatives to traditional artificial neural networks(ANNs). However, the unique information propagation mechanisms and the complexity of SNN neuron models pose challenges for adopting traditional methods developed for ANNs to SNNs. These challenges include both weight learning and architecture design. While surrogate gradient learning has shown some success in addressing the former challenge, the latter remains relatively unexplored. Recently, a novel paradigm utilizing evolutionary computation methods has emerged to tackle these challenges. This approach has resulted in the development of a variety of energy-efficient and high-performance SNNs across a wide range of machine learning benchmarks. In this paper, we present a survey of these works and initiate discussions on potential challenges ahead.
Efficient Deep Spiking Multi-Layer Perceptrons with Multiplication-Free Inference
Jun 21, 2023



Advancements in adapting deep convolution architectures for Spiking Neural Networks (SNNs) have significantly enhanced image classification performance and reduced computational burdens. However, the inability of Multiplication-Free Inference (MFI) to harmonize with attention and transformer mechanisms, which are critical to superior performance on high-resolution vision tasks, imposes limitations on these gains. To address this, our research explores a new pathway, drawing inspiration from the progress made in Multi-Layer Perceptrons (MLPs). We propose an innovative spiking MLP architecture that uses batch normalization to retain MFI compatibility and introduces a spiking patch encoding layer to reinforce local feature extraction capabilities. As a result, we establish an efficient multi-stage spiking MLP network that effectively blends global receptive fields with local feature extraction for comprehensive spike-based computation. Without relying on pre-training or sophisticated SNN training techniques, our network secures a top-1 accuracy of 66.39% on the ImageNet-1K dataset, surpassing the directly trained spiking ResNet-34 by 2.67%. Furthermore, we curtail computational costs, model capacity, and simulation steps. An expanded version of our network challenges the performance of the spiking VGG-16 network with a 71.64% top-1 accuracy, all while operating with a model capacity 2.1 times smaller. Our findings accentuate the potential of our deep SNN architecture in seamlessly integrating global and local learning abilities. Interestingly, the trained receptive field in our network mirrors the activity patterns of cortical cells.
Auto-Spikformer: Spikformer Architecture Search
Jun 01, 2023The integration of self-attention mechanisms into Spiking Neural Networks (SNNs) has garnered considerable interest in the realm of advanced deep learning, primarily due to their biological properties. Recent advancements in SNN architecture, such as Spikformer, have demonstrated promising outcomes by leveraging Spiking Self-Attention (SSA) and Spiking Patch Splitting (SPS) modules. However, we observe that Spikformer may exhibit excessive energy consumption, potentially attributable to redundant channels and blocks. To mitigate this issue, we propose Auto-Spikformer, a one-shot Transformer Architecture Search (TAS) method, which automates the quest for an optimized Spikformer architecture. To facilitate the search process, we propose methods Evolutionary SNN neurons (ESNN), which optimizes the SNN parameters, and apply the previous method of weight entanglement supernet training, which optimizes the Vision Transformer (ViT) parameters. Moreover, we propose an accuracy and energy balanced fitness function $\mathcal{F}_{AEB}$ that jointly considers both energy consumption and accuracy, and aims to find a Pareto optimal combination that balances these two objectives. Our experimental results demonstrate the effectiveness of Auto-Spikformer, which outperforms the state-of-the-art method including CNN or ViT models that are manually or automatically designed while significantly reducing energy consumption.