 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeILRe: Intermediate Layer Retrieval for Context Compression in Causal Language Models
Aug 25, 2025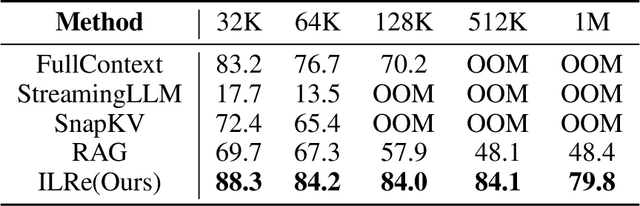
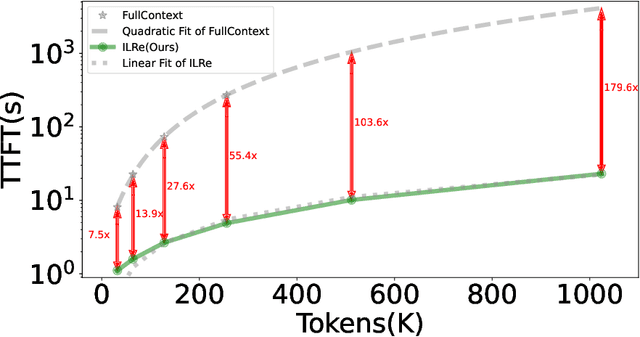
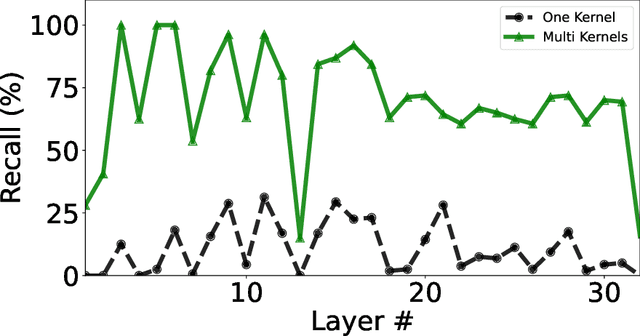
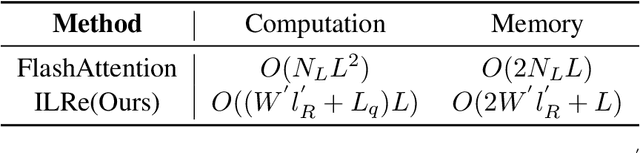
Large Language Models (LLMs) have demonstrated success across many benchmarks. However, they still exhibit limitations in long-context scenarios, primarily due to their short effective context length, quadratic computational complexity, and high memory overhead when processing lengthy inputs. To mitigate these issues, we introduce a novel context compression pipeline, called Intermediate Layer Retrieval (ILRe), which determines one intermediate decoder layer offline, encodes context by streaming chunked prefill only up to that layer, and recalls tokens by the attention scores between the input query and full key cache in that specified layer. In particular, we propose a multi-pooling kernels allocating strategy in the token recalling process to maintain the completeness of semantics. Our approach not only reduces the prefilling complexity from $O(L^2)$ to $O(L)$, but also achieves performance comparable to or better than the full context in the long context scenarios. Without additional post training or operator development, ILRe can process a single $1M$ tokens request in less than half a minute (speedup $\approx 180\times$) and scores RULER-$1M$ benchmark of $\approx 79.8$ with model Llama-3.1-UltraLong-8B-1M-Instruct on a Huawei Ascend 910B NPU.
Lag-Relative Sparse Attention In Long Context Training
Jun 13, 2025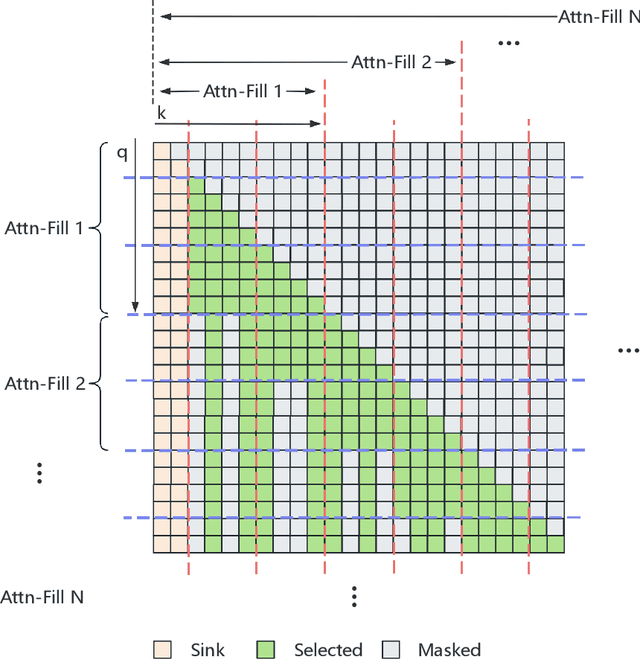



Large Language Models (LLMs) have made significant strides in natural language processing and generation, yet their ability to handle long-context input remains constrained by the quadratic complexity of attention computation and linear-increasing key-value memory footprint. To reduce computational costs and memory, key-value cache compression techniques are commonly applied at inference time, but this often leads to severe performance degradation, as models are not trained to handle compressed context. Although there are more sophisticated compression methods, they are typically unsuitable for post-training because of their incompatibility with gradient-based optimization or high computation overhead. To fill this gap with no additional parameter and little computation overhead, we propose Lag-Relative Sparse Attention(LRSA) anchored by the LagKV compression method for long context post-training. Our method performs chunk-by-chunk prefilling, which selects the top K most relevant key-value pairs in a fixed-size lagging window, allowing the model to focus on salient historical context while maintaining efficiency. Experimental results show that our approach significantly enhances the robustness of the LLM with key-value compression and achieves better fine-tuned results in the question-answer tuning task.
Rewarding Curse: Analyze and Mitigate Reward Modeling Issues for LLM Reasoning
Mar 07, 2025Chain-of-thought (CoT) prompting demonstrates varying performance under different reasoning tasks. Previous work attempts to evaluate it but falls short in providing an in-depth analysis of patterns that influence the CoT. In this paper, we study the CoT performance from the perspective of effectiveness and faithfulness. For the former, we identify key factors that influence CoT effectiveness on performance improvement, including problem difficulty, information gain, and information flow. For the latter, we interpret the unfaithful CoT issue by conducting a joint analysis of the information interaction among the question, CoT, and answer. The result demonstrates that, when the LLM predicts answers, it can recall correct information missing in the CoT from the question, leading to the problem. Finally, we propose a novel algorithm to mitigate this issue, in which we recall extra information from the question to enhance the CoT generation and evaluate CoTs based on their information gain. Extensive experiments demonstrate that our approach enhances both the faithfulness and effectiveness of CoT.
SimuCourt: Building Judicial Decision-Making Agents with Real-world Judgement Documents
Mar 05, 2024



With the development of deep learning, natural language processing technology has effectively improved the efficiency of various aspects of the traditional judicial industry. However, most current efforts focus solely on individual judicial stage, overlooking cross-stage collaboration. As the autonomous agents powered by large language models are becoming increasingly smart and able to make complex decisions in real-world settings, offering new insights for judicial intelligence. In this paper, (1) we introduce SimuCourt, a judicial benchmark that encompasses 420 judgment documents from real-world, spanning the three most common types of judicial cases, and a novel task Judicial Decision-Making to evaluate the judicial analysis and decision-making power of agents. To support this task, we construct a large-scale judicial knowledge base, JudicialKB, with multiple legal knowledge. (2) we propose a novel multi-agent framework, AgentsCourt. Our framework follows the real-world classic court trial process, consisting of court debate simulation, legal information retrieval and judgement refinement to simulate the decision-making of judge. (3) we perform extensive experiments, the results demonstrate that, our framework outperforms the existing advanced methods in various aspects, especially in generating legal grounds, where our model achieves significant improvements of 8.6% and 9.1% F1 score in the first and second instance settings, respectively.
Cutting Off the Head Ends the Conflict: A Mechanism for Interpreting and Mitigating Knowledge Conflicts in Language Models
Feb 28, 2024Recently, retrieval augmentation and tool augmentation have demonstrated a remarkable capability to expand the internal memory boundaries of language models (LMs) by providing external context. However, internal memory and external context inevitably clash, leading to knowledge conflicts within LMs. In this paper, we aim to interpret the mechanism of knowledge conflicts through the lens of information flow, and then mitigate conflicts by precise interventions at the pivotal point. We find there are some attention heads with opposite effects in the later layers, where memory heads can recall knowledge from internal memory, and context heads can retrieve knowledge from external context. Moreover, we reveal that the pivotal point at which knowledge conflicts emerge in LMs is the integration of inconsistent information flows by memory heads and context heads. Inspired by the insights, we propose a novel method called Pruning Head via PatH PatcHing (PH3), which can efficiently mitigate knowledge conflicts by pruning conflicting attention heads without updating model parameters. PH3 can flexibly control eight LMs to use internal memory ($\uparrow$ 44.0%) or external context ($\uparrow$ 38.5%). Moreover, PH3 can also improve the performance of LMs on open-domain QA tasks. We also conduct extensive experiments to demonstrate the cross-model, cross-relation, and cross-format generalization of our method.