 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Coreset Selection on Spurious Correlations and Group Robustness
Jul 15, 2025
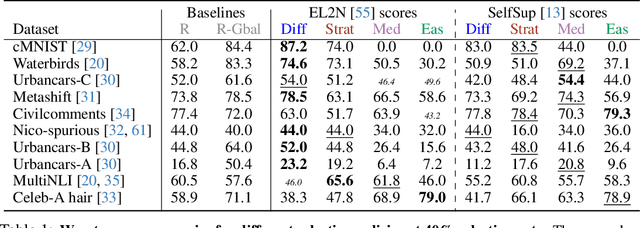

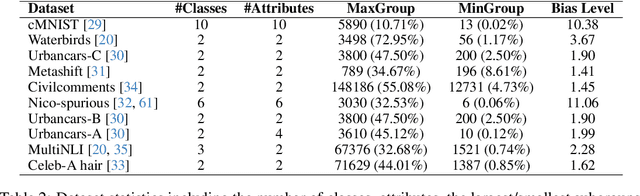
Coreset selection methods have shown promise in reducing the training data size while maintaining model performance for data-efficient machine learning. However, as many datasets suffer from biases that cause models to learn spurious correlations instead of causal features, it is important to understand whether and how dataset reduction methods may perpetuate, amplify, or mitigate these biases. In this work, we conduct the first comprehensive analysis of the implications of data selection on the spurious bias levels of the selected coresets and the robustness of downstream models trained on them. We use an extensive experimental setting spanning ten different spurious correlations benchmarks, five score metrics to characterize sample importance/ difficulty, and five data selection policies across a broad range of coreset sizes. Thereby, we unravel a series of nontrivial nuances in interactions between sample difficulty and bias alignment, as well as dataset bias and resultant model robustness. For example, we find that selecting coresets using embedding-based sample characterization scores runs a comparatively lower risk of inadvertently exacerbating bias than selecting using characterizations based on learning dynamics. Most importantly, our analysis reveals that although some coreset selection methods could achieve lower bias levels by prioritizing difficult samples, they do not reliably guarantee downstream robustness.
Cross-Modal Self-Training: Aligning Images and Pointclouds to Learn Classification without Labels
Apr 15, 2024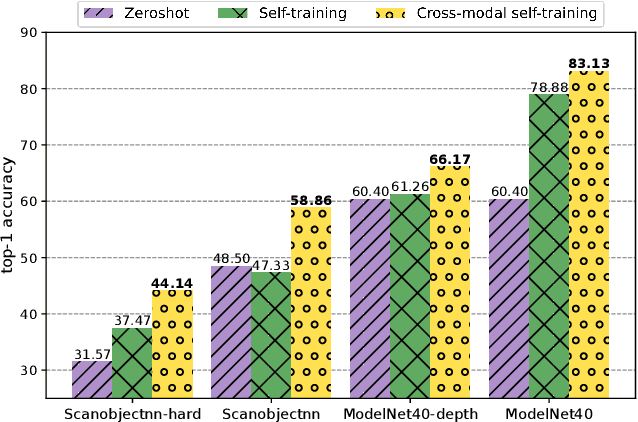

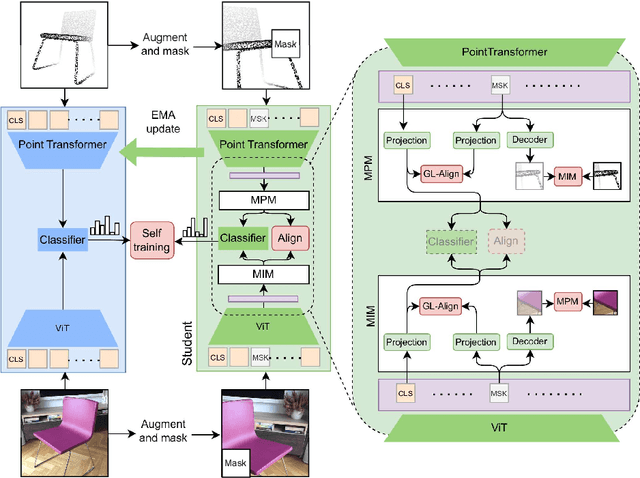
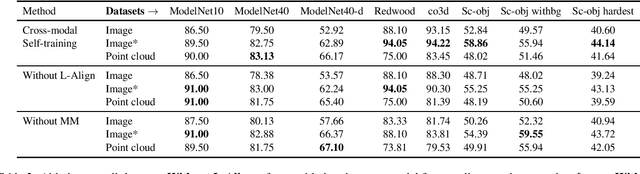
Large-scale vision 2D vision language models, such as CLIP can be aligned with a 3D encoder to learn generalizable (open-vocabulary) 3D vision models. However, current methods require supervised pre-training for such alignment, and the performance of such 3D zero-shot models remains sub-optimal for real-world adaptation. In this work, we propose an optimization framework: Cross-MoST: Cross-Modal Self-Training, to improve the label-free classification performance of a zero-shot 3D vision model by simply leveraging unlabeled 3D data and their accompanying 2D views. We propose a student-teacher framework to simultaneously process 2D views and 3D point clouds and generate joint pseudo labels to train a classifier and guide cross-model feature alignment. Thereby we demonstrate that 2D vision language models such as CLIP can be used to complement 3D representation learning to improve classification performance without the need for expensive class annotations. Using synthetic and real-world 3D datasets, we further demonstrate that Cross-MoST enables efficient cross-modal knowledge exchange resulting in both image and point cloud modalities learning from each other's rich representations.
DETER: Detecting Edited Regions for Deterring Generative Manipulations
Dec 16, 2023Generative AI capabilities have grown substantially in recent years, raising renewed concerns about potential malicious use of generated data, or "deep fakes". However, deep fake datasets have not kept up with generative AI advancements sufficiently to enable the development of deep fake detection technology which can meaningfully alert human users in real-world settings. Existing datasets typically use GAN-based models and introduce spurious correlations by always editing similar face regions. To counteract the shortcomings, we introduce DETER, a large-scale dataset for DETEcting edited image Regions and deterring modern advanced generative manipulations. DETER includes 300,000 images manipulated by four state-of-the-art generators with three editing operations: face swapping (a standard coarse image manipulation), inpainting (a novel manipulation for deep fake datasets), and attribute editing (a subtle fine-grained manipulation). While face swapping and attribute editing are performed on similar face regions such as eyes and nose, the inpainting operation can be performed on random image regions, removing the spurious correlations of previous datasets. Careful image post-processing is performed to ensure deep fakes in DETER look realistic, and human studies confirm that human deep fake detection rate on DETER is 20.4% lower than on other fake datasets. Equipped with the dataset, we conduct extensive experiments and break-down analysis using our rich annotations and improved benchmark protocols, revealing future directions and the next set of challenges in developing reliable regional fake detection models.
3DLatNav: Navigating Generative Latent Spaces for Semantic-Aware 3D Object Manipulation
Nov 17, 2022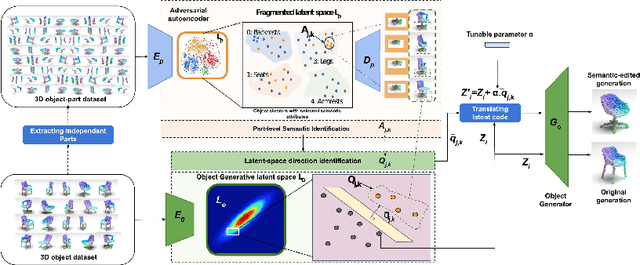
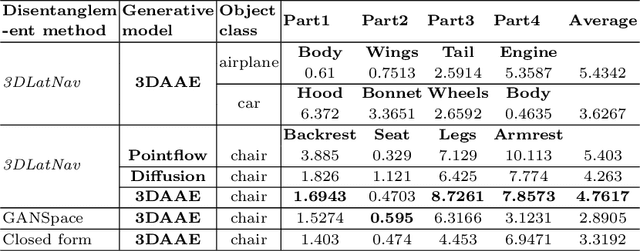
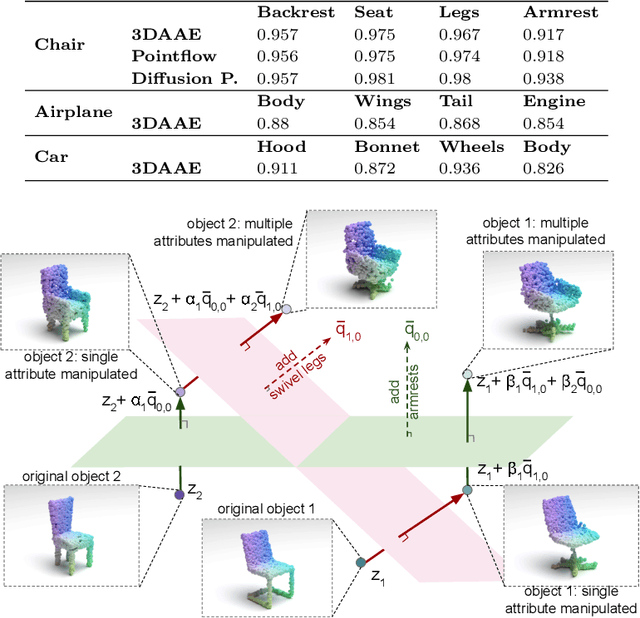
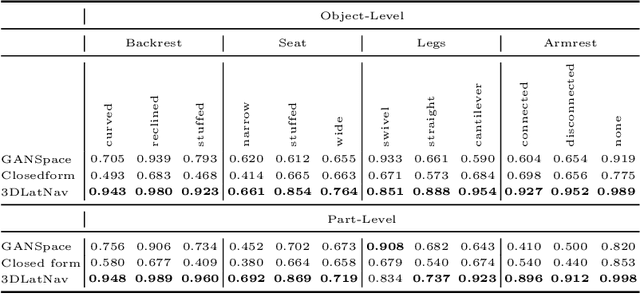
3D generative models have been recently successful in generating realistic 3D objects in the form of point clouds. However, most models do not offer controllability to manipulate the shape semantics of component object parts without extensive semantic attribute labels or other reference point clouds. Moreover, beyond the ability to perform simple latent vector arithmetic or interpolations, there is a lack of understanding of how part-level semantics of 3D shapes are encoded in their corresponding generative latent spaces. In this paper, we propose 3DLatNav; a novel approach to navigating pretrained generative latent spaces to enable controlled part-level semantic manipulation of 3D objects. First, we propose a part-level weakly-supervised shape semantics identification mechanism using latent representations of 3D shapes. Then, we transfer that knowledge to a pretrained 3D object generative latent space to unravel disentangled embeddings to represent different shape semantics of component parts of an object in the form of linear subspaces, despite the unavailability of part-level labels during the training. Finally, we utilize those identified subspaces to show that controllable 3D object part manipulation can be achieved by applying the proposed framework to any pretrained 3D generative model. With two novel quantitative metrics to evaluate the consistency and localization accuracy of part-level manipulations, we show that 3DLatNav outperforms existing unsupervised latent disentanglement methods in identifying latent directions that encode part-level shape semantics of 3D objects. With multiple ablation studies and testing on state-of-the-art generative models, we show that 3DLatNav can implement controlled part-level semantic manipulations on an input point cloud while preserving other features and the realistic nature of the object.
CrossPoint: Self-Supervised Cross-Modal Contrastive Learning for 3D Point Cloud Understanding
Mar 24, 2022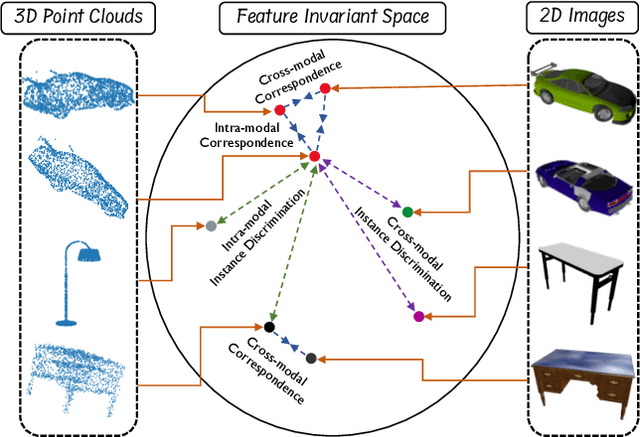
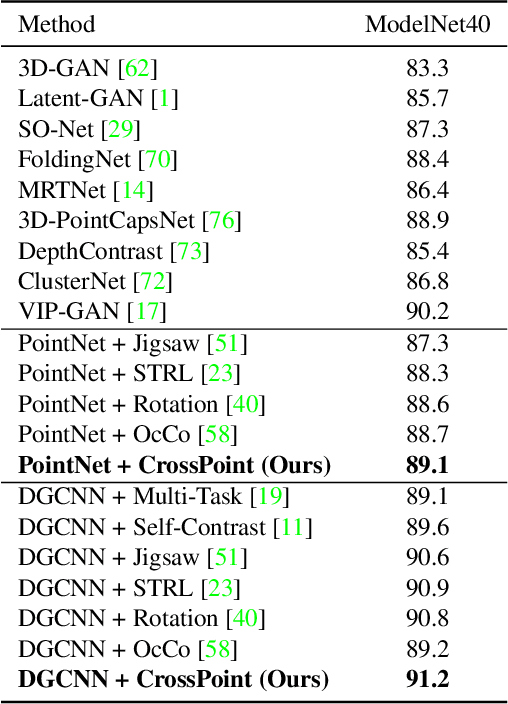
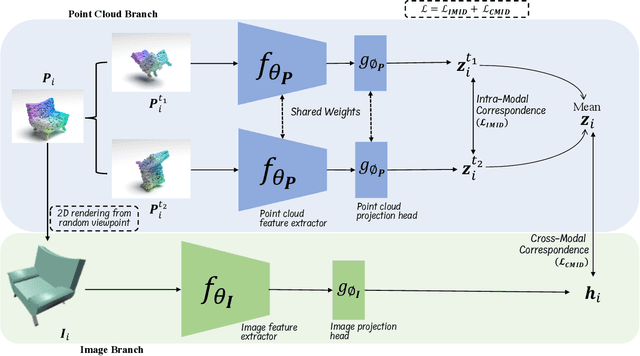
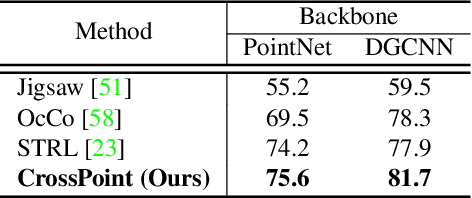
Manual annotation of large-scale point cloud dataset for varying tasks such as 3D object classification, segmentation and detection is often laborious owing to the irregular structure of point clouds. Self-supervised learning, which operates without any human labeling, is a promising approach to address this issue. We observe in the real world that humans are capable of mapping the visual concepts learnt from 2D images to understand the 3D world. Encouraged by this insight, we propose CrossPoint, a simple cross-modal contrastive learning approach to learn transferable 3D point cloud representations. It enables a 3D-2D correspondence of objects by maximizing agreement between point clouds and the corresponding rendered 2D image in the invariant space, while encouraging invariance to transformations in the point cloud modality. Our joint training objective combines the feature correspondences within and across modalities, thus ensembles a rich learning signal from both 3D point cloud and 2D image modalities in a self-supervised fashion. Experimental results show that our approach outperforms the previous unsupervised learning methods on a diverse range of downstream tasks including 3D object classification and segmentation. Further, the ablation studies validate the potency of our approach for a better point cloud understanding. Code and pretrained models are available at http://github.com/MohamedAfham/CrossPoint.