 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DLatNav: Navigating Generative Latent Spaces for Semantic-Aware 3D Object Manipulation
Nov 17, 2022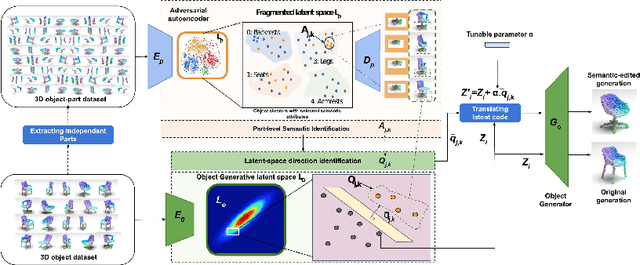
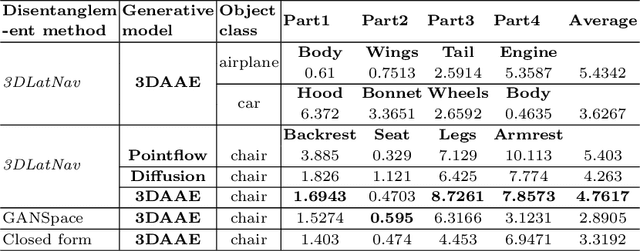
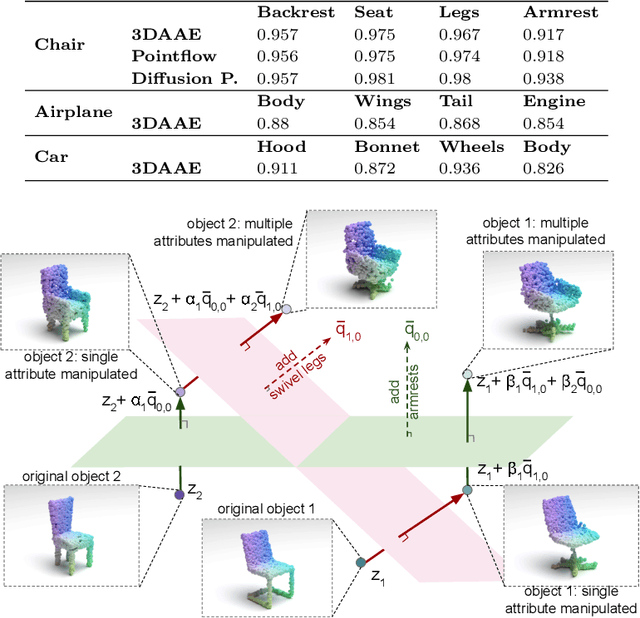
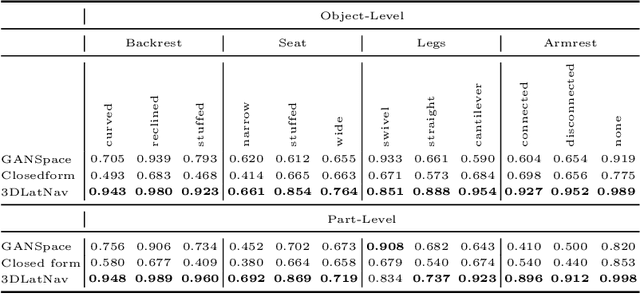
3D generative models have been recently successful in generating realistic 3D objects in the form of point clouds. However, most models do not offer controllability to manipulate the shape semantics of component object parts without extensive semantic attribute labels or other reference point clouds. Moreover, beyond the ability to perform simple latent vector arithmetic or interpolations, there is a lack of understanding of how part-level semantics of 3D shapes are encoded in their corresponding generative latent spaces. In this paper, we propose 3DLatNav; a novel approach to navigating pretrained generative latent spaces to enable controlled part-level semantic manipulation of 3D objects. First, we propose a part-level weakly-supervised shape semantics identification mechanism using latent representations of 3D shapes. Then, we transfer that knowledge to a pretrained 3D object generative latent space to unravel disentangled embeddings to represent different shape semantics of component parts of an object in the form of linear subspaces, despite the unavailability of part-level labels during the training. Finally, we utilize those identified subspaces to show that controllable 3D object part manipulation can be achieved by applying the proposed framework to any pretrained 3D generative model. With two novel quantitative metrics to evaluate the consistency and localization accuracy of part-level manipulations, we show that 3DLatNav outperforms existing unsupervised latent disentanglement methods in identifying latent directions that encode part-level shape semantics of 3D objects. With multiple ablation studies and testing on state-of-the-art generative models, we show that 3DLatNav can implement controlled part-level semantic manipulations on an input point cloud while preserving other features and the realistic nature of the object.
CrossPoint: Self-Supervised Cross-Modal Contrastive Learning for 3D Point Cloud Understanding
Mar 24, 2022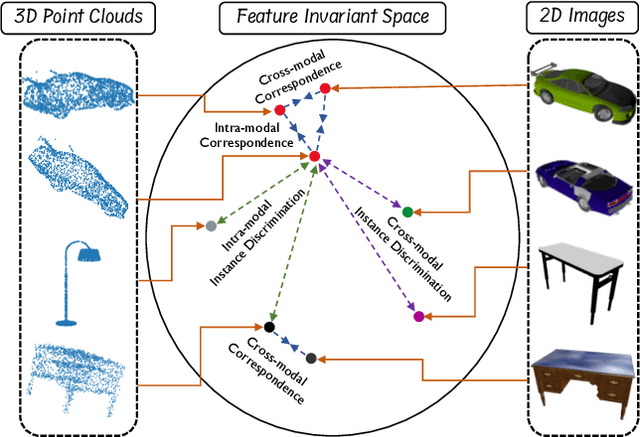
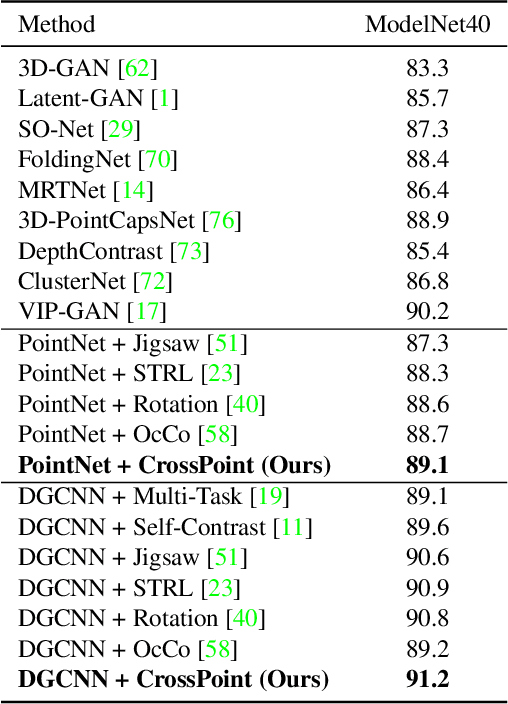
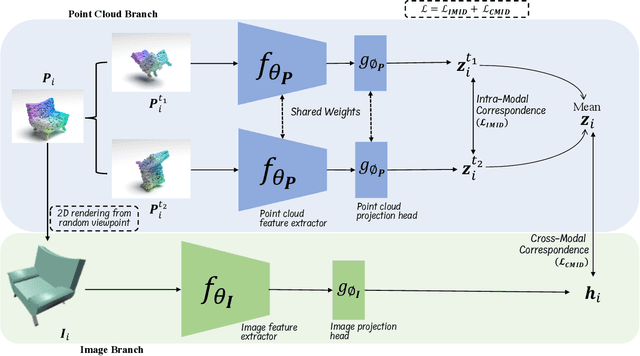
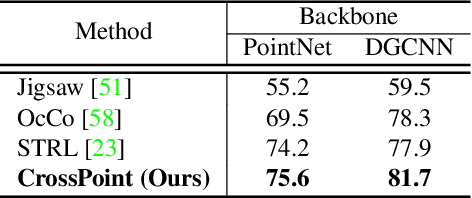
Manual annotation of large-scale point cloud dataset for varying tasks such as 3D object classification, segmentation and detection is often laborious owing to the irregular structure of point clouds. Self-supervised learning, which operates without any human labeling, is a promising approach to address this issue. We observe in the real world that humans are capable of mapping the visual concepts learnt from 2D images to understand the 3D world. Encouraged by this insight, we propose CrossPoint, a simple cross-modal contrastive learning approach to learn transferable 3D point cloud representations. It enables a 3D-2D correspondence of objects by maximizing agreement between point clouds and the corresponding rendered 2D image in the invariant space, while encouraging invariance to transformations in the point cloud modality. Our joint training objective combines the feature correspondences within and across modalities, thus ensembles a rich learning signal from both 3D point cloud and 2D image modalities in a self-supervised fashion. Experimental results show that our approach outperforms the previous unsupervised learning methods on a diverse range of downstream tasks including 3D object classification and segmentation. Further, the ablation studies validate the potency of our approach for a better point cloud understanding. Code and pretrained models are available at http://github.com/MohamedAfham/CrossPoint.