 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-label classification of open-ended questions with BERT
Apr 06, 2023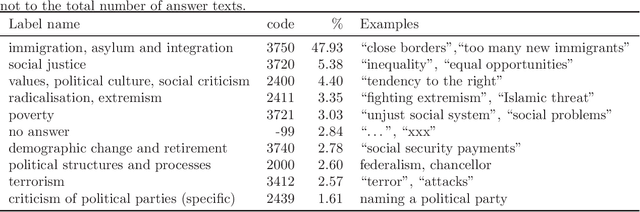
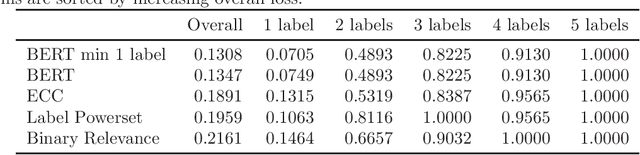
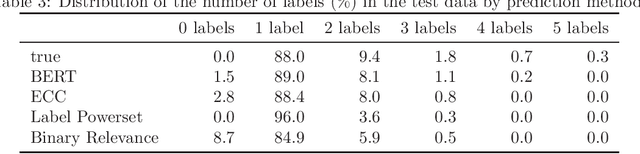

Open-ended questions in surveys are valuable because they do not constrain the respondent's answer, thereby avoiding biases. However, answers to open-ended questions are text data which are harder to analyze. Traditionally, answers were manually classified as specified in the coding manual. Most of the effort to automate coding has gone into the easier problem of single label prediction, where answers are classified into a single code. However, open-ends that require multi-label classification, i.e., that are assigned multiple codes, occur frequently. This paper focuses on multi-label classification of text answers to open-ended survey questions in social science surveys. We evaluate the performance of the transformer-based architecture BERT for the German language in comparison to traditional multi-label algorithms (Binary Relevance, Label Powerset, ECC) in a German social science survey, the GLES Panel (N=17,584, 55 labels). We find that classification with BERT (forcing at least one label) has the smallest 0/1 loss (13.1%) among methods considered (18.9%-21.6%). As expected, it is much easier to correctly predict answer texts that correspond to a single label (7.1% loss) than those that correspond to multiple labels ($\sim$50% loss). Because BERT predicts zero labels for only 1.5% of the answers, forcing at least one label, while recommended, ultimately does not lower the 0/1 loss by much. Our work has important implications for social scientists: 1) We have shown multi-label classification with BERT works in the German language for open-ends. 2) For mildly multi-label classification tasks, the loss now appears small enough to allow for fully automatic classification (as compared to semi-automatic approaches). 3) Multi-label classification with BERT requires only a single model. The leading competitor, ECC, iterates through individual single label predictions.
One Line To Rule Them All: Generating LO-Shot Soft-Label Prototypes
Feb 15, 2021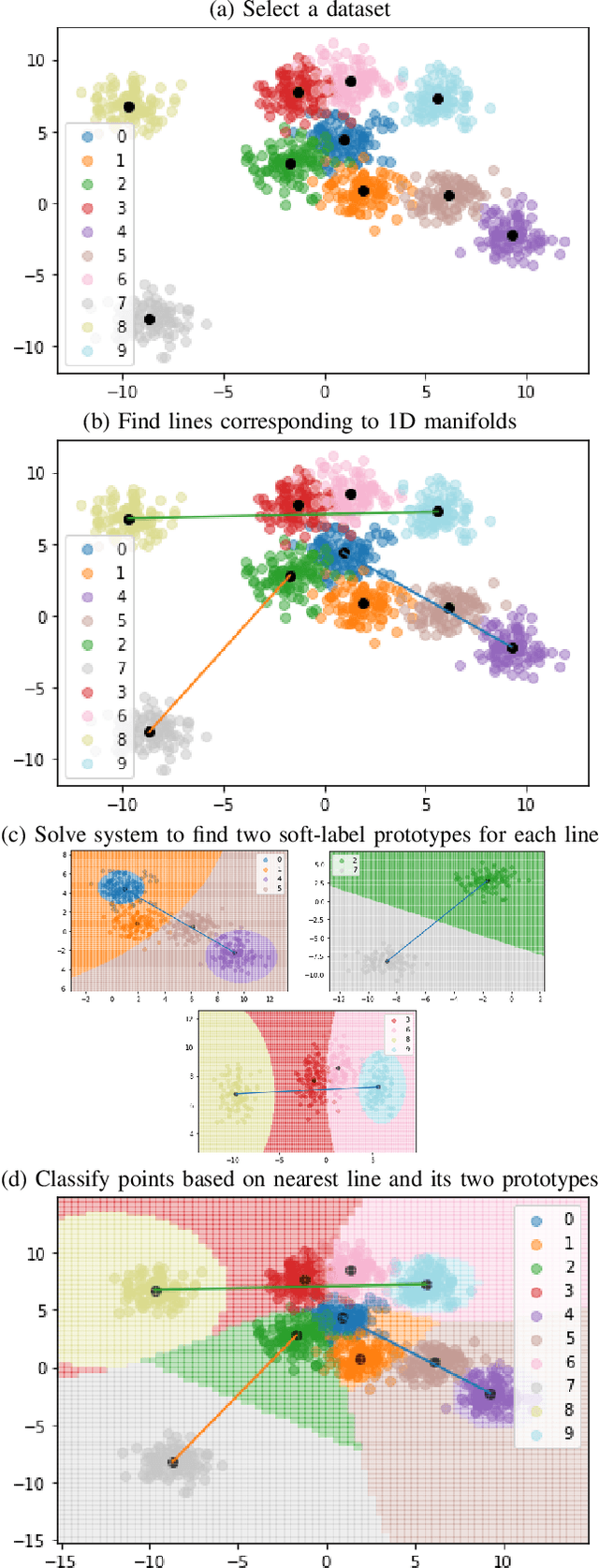
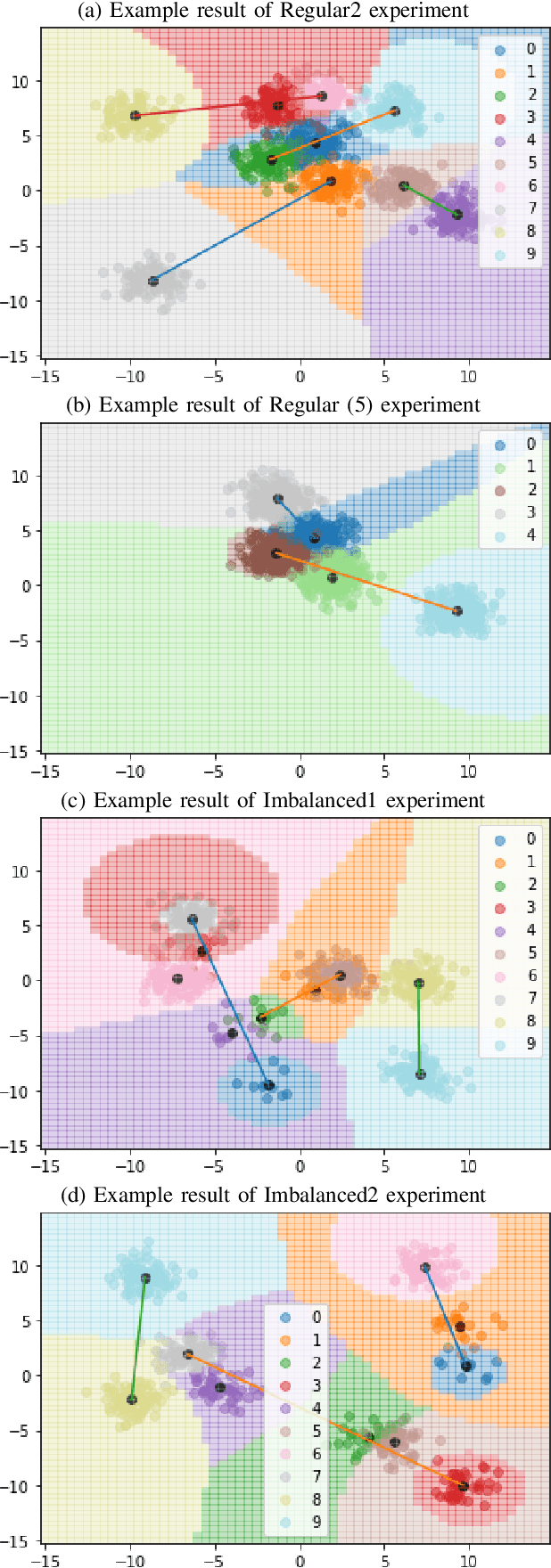
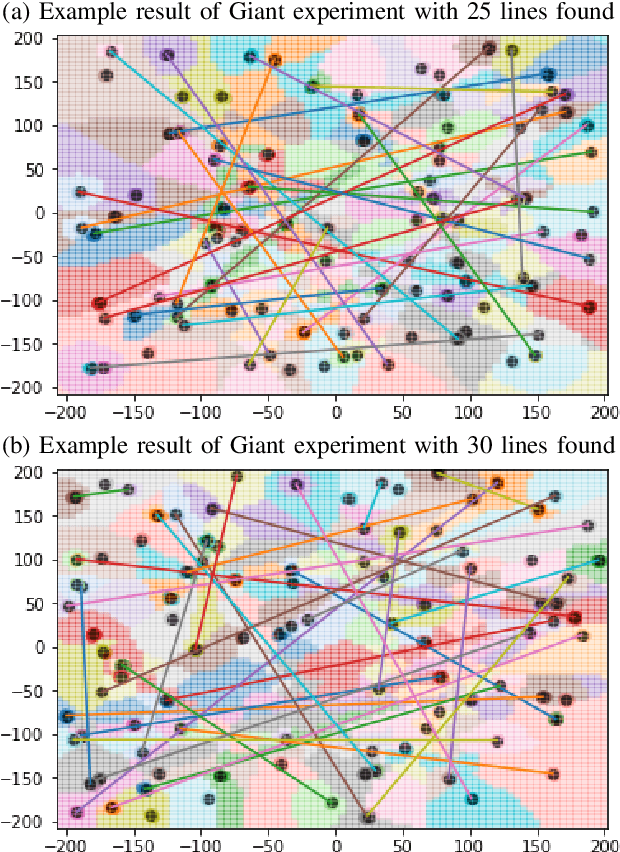
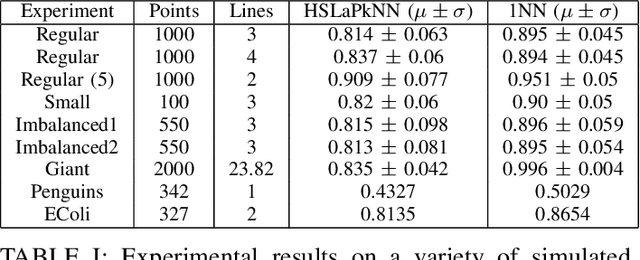
Increasingly large datasets are rapidly driving up the computational costs of machine learning. Prototype generation methods aim to create a small set of synthetic observations that accurately represent a training dataset but greatly reduce the computational cost of learning from it. Assigning soft labels to prototypes can allow increasingly small sets of prototypes to accurately represent the original training dataset. Although foundational work on `less than one'-shot learning has proven the theoretical plausibility of learning with fewer than one observation per class, developing practical algorithms for generating such prototypes remains an unexplored territory. We propose a novel, modular method for generating soft-label prototypical lines that still maintains representational accuracy even when there are fewer prototypes than the number of classes in the data. In addition, we propose the Hierarchical Soft-Label Prototype k-Nearest Neighbor classification algorithm based on these prototypical lines. We show that our method maintains high classification accuracy while greatly reducing the number of prototypes required to represent a dataset, even when working with severely imbalanced and difficult data. Our code is available at https://github.com/ilia10000/SLkNN.
Optimal 1-NN Prototypes for Pathological Geometries
Oct 31, 2020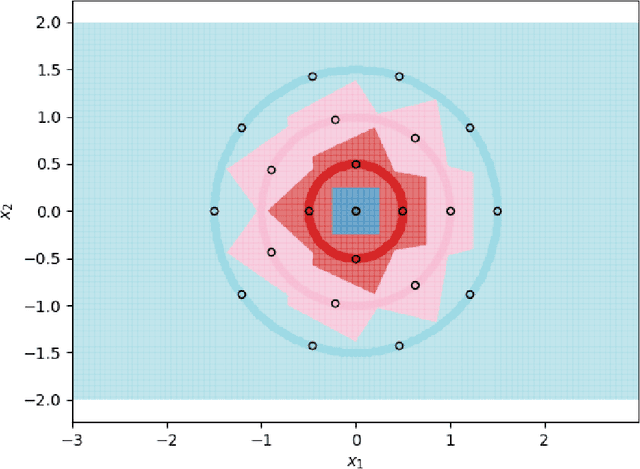
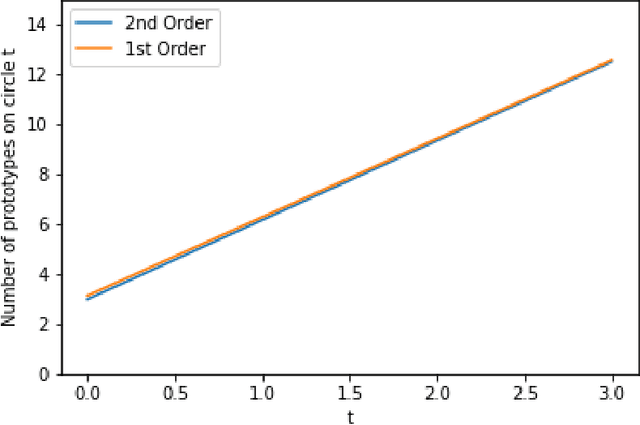
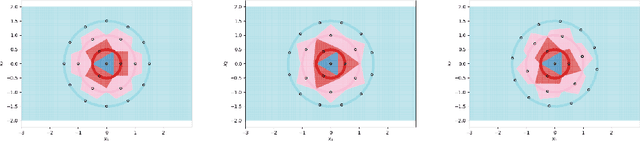
Using prototype methods to reduce the size of training datasets can drastically reduce the computational cost of classification with instance-based learning algorithms like the k-Nearest Neighbour classifier. The number and distribution of prototypes required for the classifier to match its original performance is intimately related to the geometry of the training data. As a result, it is often difficult to find the optimal prototypes for a given dataset, and heuristic algorithms are used instead. However, we consider a particularly challenging setting where commonly used heuristic algorithms fail to find suitable prototypes and show that the optimal prototypes can instead be found analytically. We also propose an algorithm for finding nearly-optimal prototypes in this setting, and use it to empirically validate the theoretical results.
SecDD: Efficient and Secure Method for Remotely Training Neural Networks
Sep 19, 2020
We leverage what are typically considered the worst qualities of deep learning algorithms - high computational cost, requirement for large data, no explainability, high dependence on hyper-parameter choice, overfitting, and vulnerability to adversarial perturbations - in order to create a method for the secure and efficient training of remotely deployed neural networks over unsecured channels.
'Less Than One'-Shot Learning: Learning N Classes From M<N Samples
Sep 17, 2020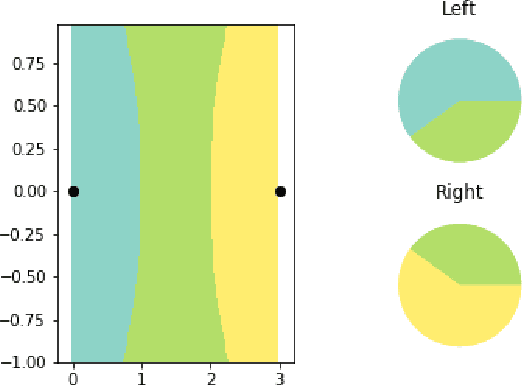
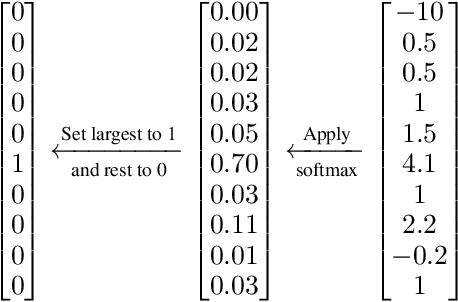
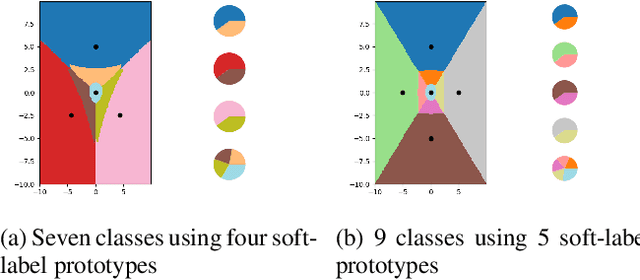
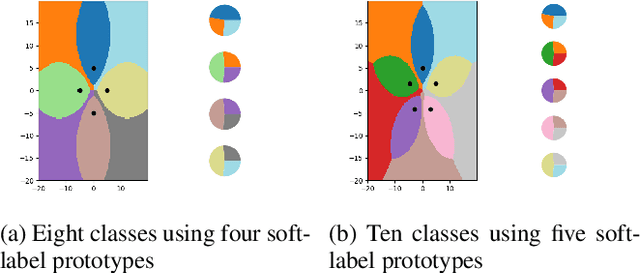
Deep neural networks require large training sets but suffer from high computational cost and long training times. Training on much smaller training sets while maintaining nearly the same accuracy would be very beneficial. In the few-shot learning setting, a model must learn a new class given only a small number of samples from that class. One-shot learning is an extreme form of few-shot learning where the model must learn a new class from a single example. We propose the `less than one'-shot learning task where models must learn $N$ new classes given only $M<N$ examples and we show that this is achievable with the help of soft labels. We use a soft-label generalization of the k-Nearest Neighbors classifier to explore the intricate decision landscapes that can be created in the `less than one'-shot learning setting. We analyze these decision landscapes to derive theoretical lower bounds for separating $N$ classes using $M<N$ soft-label samples and investigate the robustness of the resulting systems.
Soft-Label Dataset Distillation and Text Dataset Distillation
Nov 12, 2019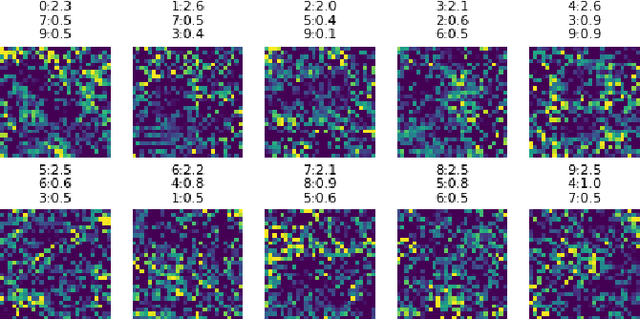

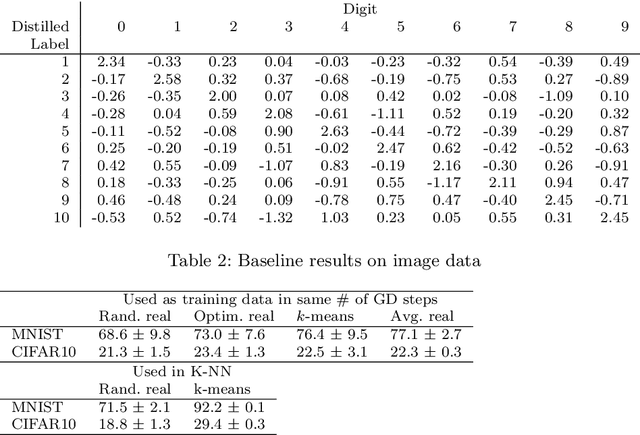
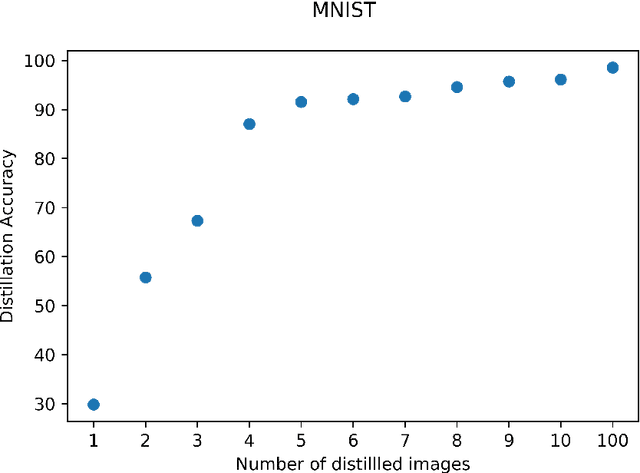
Dataset distillation is a method for reducing dataset sizes by learning a small number of synthetic samples containing all the information of a large dataset. This has several benefits like speeding up model training, reducing energy consumption, and reducing required storage space. Currently, each synthetic sample is assigned a single `hard' label, and also, dataset distillation can currently only be used with image data. We propose to simultaneously distill both images and their labels, thus assigning each synthetic sample a `soft' label (a distribution of labels). Our algorithm increases accuracy by 2-4% over the original algorithm for several image classification tasks. Using `soft' labels also enables distilled datasets to consist of fewer samples than there are classes as each sample can encode information for multiple classes. For example, training a LeNet model with 10 distilled images (one per class) results in over 96% accuracy on MNIST, and almost 92% accuracy when trained on just 5 distilled images. We also extend the dataset distillation algorithm to distill sequential datasets including texts. We demonstrate that text distillation outperforms other methods across multiple datasets. For example, models attain almost their original accuracy on the IMDB sentiment analysis task using just 20 distilled sentences.
Deep Learning for System Trace Restoration
Apr 10, 2019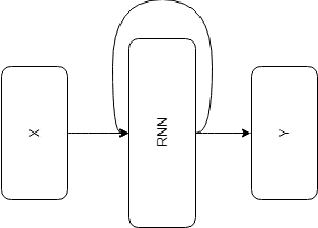
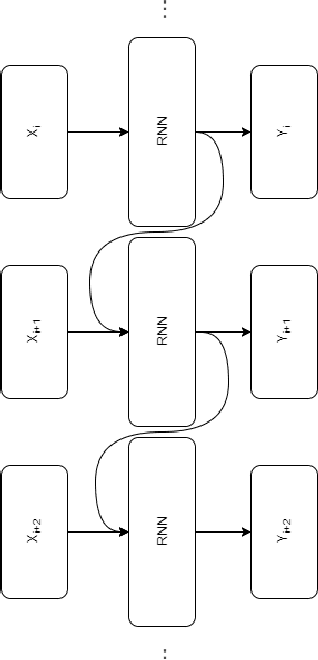
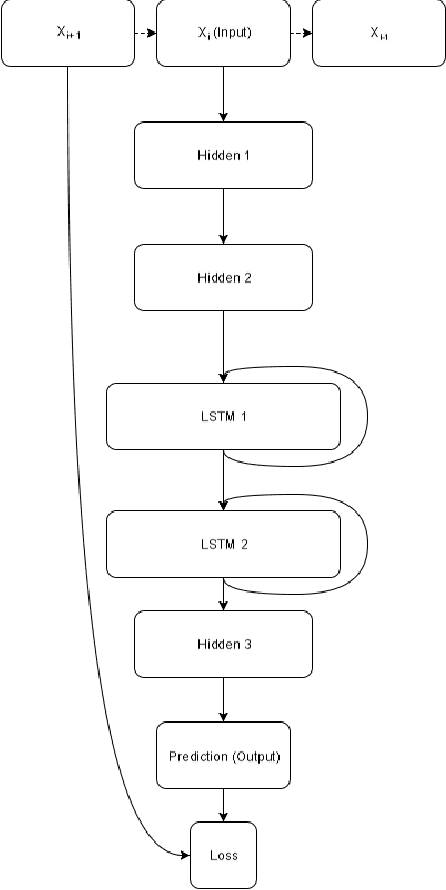
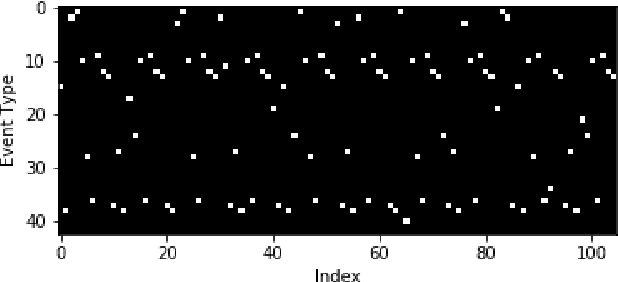
Most real-world datasets, and particularly those collected from physical systems, are full of noise, packet loss, and other imperfections. However, most specification mining, anomaly detection and other such algorithms assume, or even require, perfect data quality to function properly. Such algorithms may work in lab conditions when given clean, controlled data, but will fail in the field when given imperfect data. We propose a method for accurately reconstructing discrete temporal or sequential system traces affected by data loss, using Long Short-Term Memory Networks (LSTMs). The model works by learning to predict the next event in a sequence of events, and uses its own output as an input to continue predicting future events. As a result, this method can be used for data restoration even with streamed data. Such a method can reconstruct even long sequence of missing events, and can also help validate and improve data quality for noisy data. The output of the model will be a close reconstruction of the true data, and can be fed to algorithms that rely on clean data. We demonstrate our method by reconstructing automotive CAN traces consisting of long sequences of discrete events. We show that given even small parts of a CAN trace, our LSTM model can predict future events with an accuracy of almost 90%, and can successfully reconstruct large portions of the original trace, greatly outperforming a Markov Model benchmark. We separately feed the original, lossy, and reconstructed traces into a specification mining framework to perform downstream analysis of the effect of our method on state-of-the-art models that use these traces for understanding the behavior of complex systems.
Nearest Labelset Using Double Distances for Multi-label Classification
Feb 15, 2017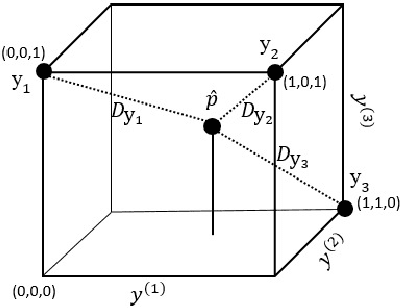
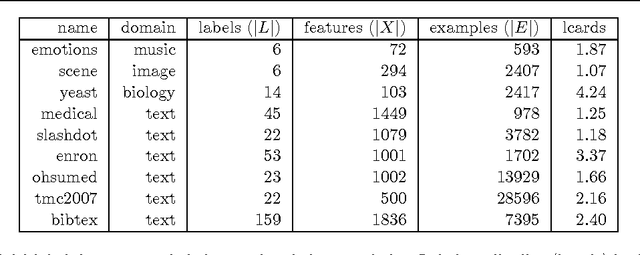
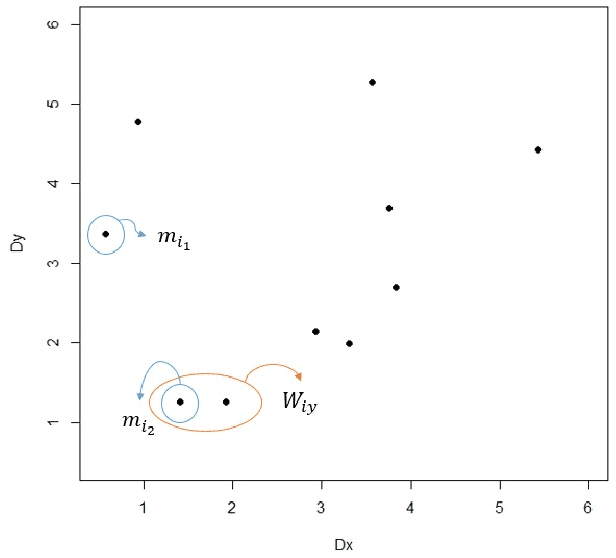
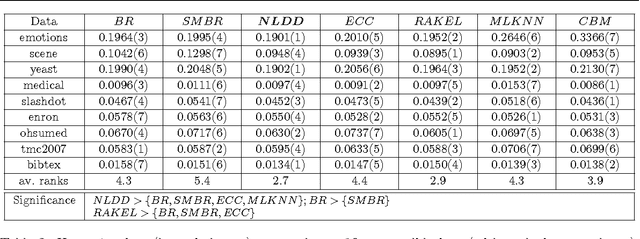
Multi-label classification is a type of supervised learning where an instance may belong to multiple labels simultaneously. Predicting each label independently has been criticized for not exploiting any correlation between labels. In this paper we propose a novel approach, Nearest Labelset using Double Distances (NLDD), that predicts the labelset observed in the training data that minimizes a weighted sum of the distances in both the feature space and the label space to the new instance. The weights specify the relative tradeoff between the two distances. The weights are estimated from a binomial regression of the number of misclassified labels as a function of the two distances. Model parameters are estimated by maximum likelihood. NLDD only considers labelsets observed in the training data, thus implicitly taking into account label dependencies. Experiments on benchmark multi-label data sets show that the proposed method on average outperforms other well-known approaches in terms of Hamming loss, 0/1 loss, and multi-label accuracy and ranks second after ECC on the F-measure.