 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Line To Rule Them All: Generating LO-Shot Soft-Label Prototypes
Feb 15, 2021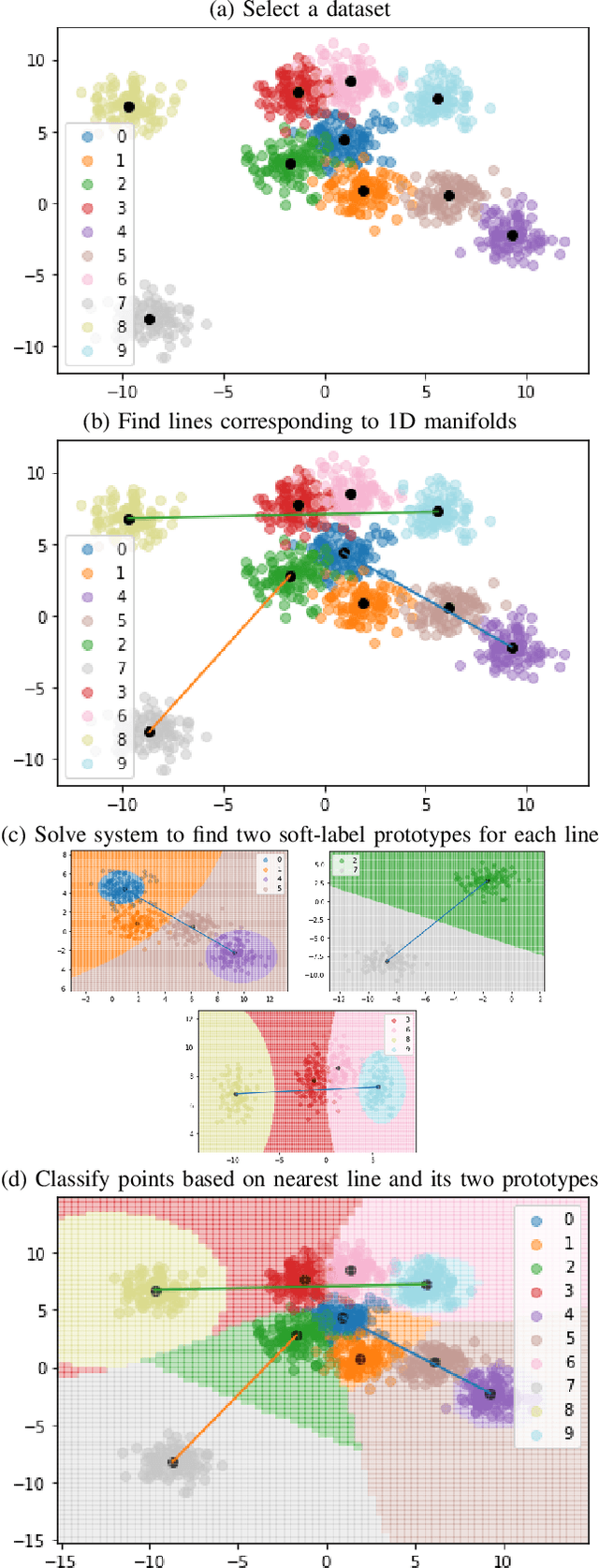
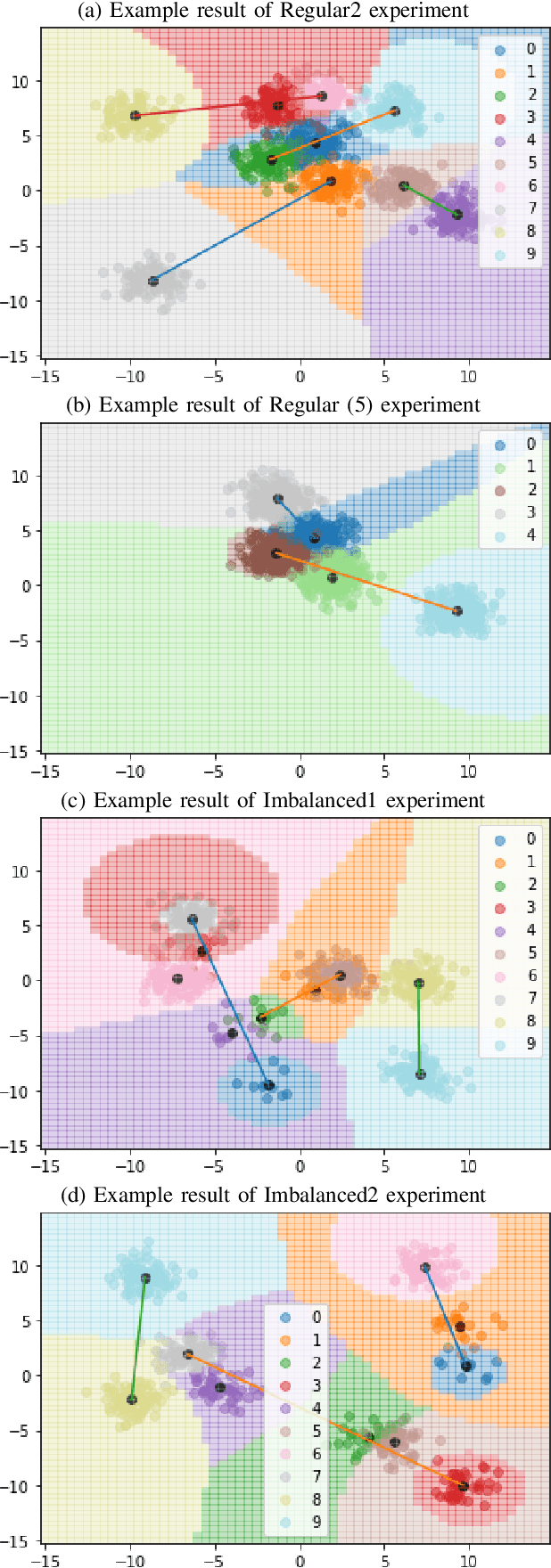
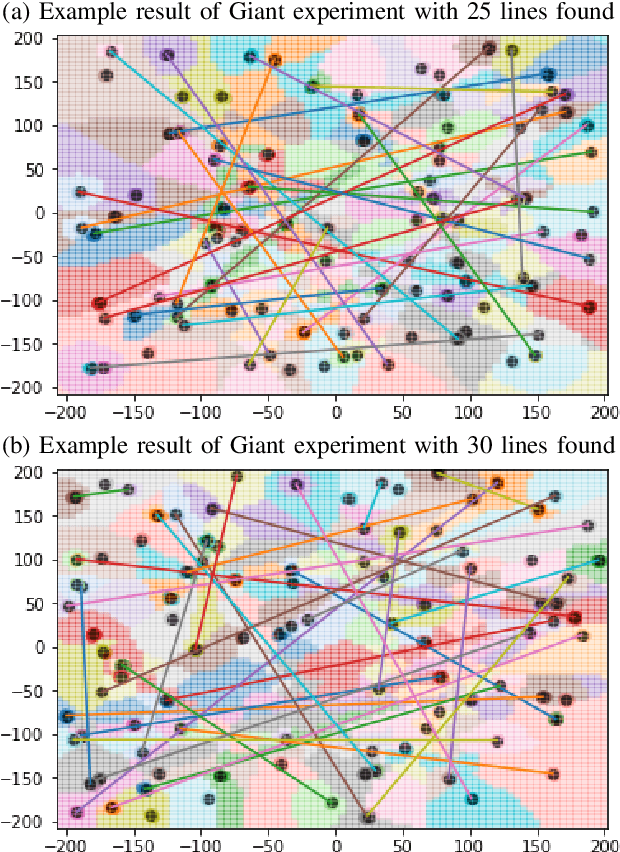
Increasingly large datasets are rapidly driving up the computational costs of machine learning. Prototype generation methods aim to create a small set of synthetic observations that accurately represent a training dataset but greatly reduce the computational cost of learning from it. Assigning soft labels to prototypes can allow increasingly small sets of prototypes to accurately represent the original training dataset. Although foundational work on `less than one'-shot learning has proven the theoretical plausibility of learning with fewer than one observation per class, developing practical algorithms for generating such prototypes remains an unexplored territory. We propose a novel, modular method for generating soft-label prototypical lines that still maintains representational accuracy even when there are fewer prototypes than the number of classes in the data. In addition, we propose the Hierarchical Soft-Label Prototype k-Nearest Neighbor classification algorithm based on these prototypical lines. We show that our method maintains high classification accuracy while greatly reducing the number of prototypes required to represent a dataset, even when working with severely imbalanced and difficult data. Our code is available at https://github.com/ilia10000/SLkNN.