 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Patch Attacks and Defences in Vision-Based Tasks: A Survey
Paper and Code
Jun 16, 2022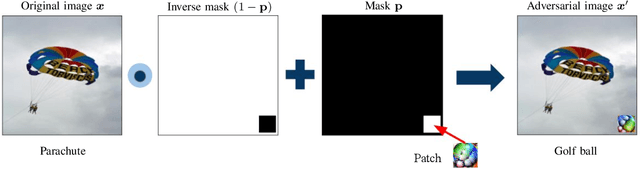


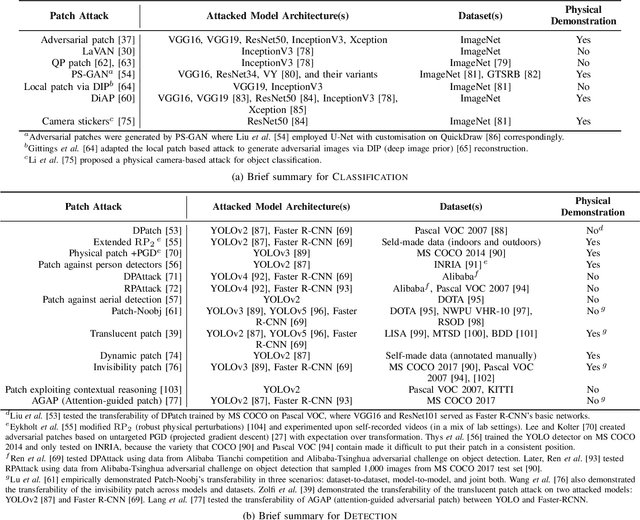
Adversarial attacks in deep learning models, especially for safety-critical systems, are gaining more and more attention in recent years, due to the lack of trust in the security and robustness of AI models. Yet the more primitive adversarial attacks might be physically infeasible or require some resources that are hard to access like the training data, which motivated the emergence of patch attacks. In this survey, we provide a comprehensive overview to cover existing techniques of adversarial patch attacks, aiming to help interested researchers quickly catch up with the progress in this field. We also discuss existing techniques for developing detection and defences against adversarial patches, aiming to help the community better understand this field and its applications in the real world.