 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssist Is Just as Important as the Goal: Image Resurfacing to Aid Model's Robust Prediction
Nov 02, 2023Adversarial patches threaten visual AI models in the real world. The number of patches in a patch attack is variable and determines the attack's potency in a specific environment. Most existing defenses assume a single patch in the scene, and the multiple patch scenarios are shown to overcome them. This paper presents a model-agnostic defense against patch attacks based on total variation for image resurfacing (TVR). The TVR is an image-cleansing method that processes images to remove probable adversarial regions. TVR can be utilized solely or augmented with a defended model, providing multi-level security for robust prediction. TVR nullifies the influence of patches in a single image scan with no prior assumption on the number of patches in the scene. We validate TVR on the ImageNet-Patch benchmark dataset and with real-world physical objects, demonstrating its ability to mitigate patch attack.
NSA: Naturalistic Support Artifact to Boost Network Confidence
Jul 27, 2023



Visual AI systems are vulnerable to natural and synthetic physical corruption in the real-world. Such corruption often arises unexpectedly and alters the model's performance. In recent years, the primary focus has been on adversarial attacks. However, natural corruptions (e.g., snow, fog, dust) are an omnipresent threat to visual AI systems and should be considered equally important. Many existing works propose interesting solutions to train robust models against natural corruption. These works either leverage image augmentations, which come with the additional cost of model training, or place suspicious patches in the scene to design unadversarial examples. In this work, we propose the idea of naturalistic support artifacts (NSA) for robust prediction. The NSAs are shown to be beneficial in scenarios where model parameters are inaccessible and adding artifacts in the scene is feasible. The NSAs are natural looking objects generated through artifact training using DC-GAN to have high visual fidelity in the scene. We test against natural corruptions on the Imagenette dataset and observe the improvement in prediction confidence score by four times. We also demonstrate NSA's capability to increase adversarial accuracy by 8\% on average. Lastly, we qualitatively analyze NSAs using saliency maps to understand how they help improve prediction confidence.
Adversarial Patch Attacks and Defences in Vision-Based Tasks: A Survey
Jun 16, 2022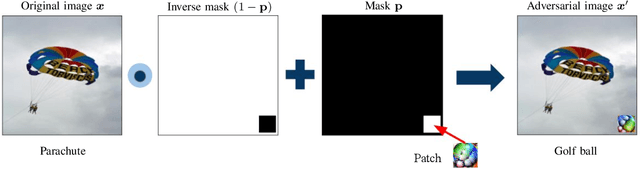


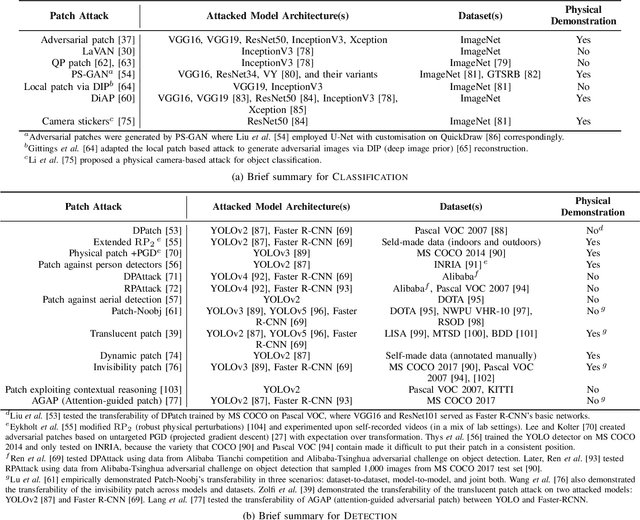
Adversarial attacks in deep learning models, especially for safety-critical systems, are gaining more and more attention in recent years, due to the lack of trust in the security and robustness of AI models. Yet the more primitive adversarial attacks might be physically infeasible or require some resources that are hard to access like the training data, which motivated the emergence of patch attacks. In this survey, we provide a comprehensive overview to cover existing techniques of adversarial patch attacks, aiming to help interested researchers quickly catch up with the progress in this field. We also discuss existing techniques for developing detection and defences against adversarial patches, aiming to help the community better understand this field and its applications in the real world.