 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilization of Non-verbal Behaviour and Social Gaze in Classroom Human-Robot Interaction Communications
Dec 11, 2023This abstract explores classroom Human-Robot Interaction (HRI) scenarios with an emphasis on the adaptation of human-inspired social gaze models in robot cognitive architecture to facilitate a more seamless social interaction. First, we detail the HRI scenarios explored by us in our studies followed by a description of the social gaze model utilized for our research. We highlight the advantages of utilizing such an attentional model in classroom HRI scenarios. We also detail the intended goals of our upcoming study involving this social gaze model.
Spiking Approximations of the MaxPooling Operation in Deep SNNs
May 14, 2022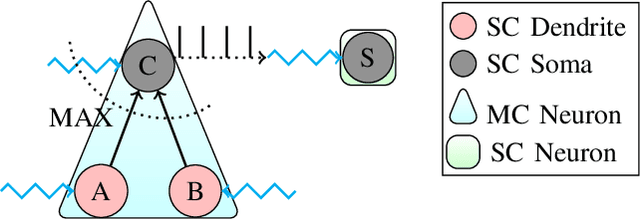
Spiking Neural Networks (SNNs) are an emerging domain of biologically inspired neural networks that have shown promise for low-power AI. A number of methods exist for building deep SNNs, with Artificial Neural Network (ANN)-to-SNN conversion being highly successful. MaxPooling layers in Convolutional Neural Networks (CNNs) are an integral component to downsample the intermediate feature maps and introduce translational invariance, but the absence of their hardware-friendly spiking equivalents limits such CNNs' conversion to deep SNNs. In this paper, we present two hardware-friendly methods to implement Max-Pooling in deep SNNs, thus facilitating easy conversion of CNNs with MaxPooling layers to SNNs. In a first, we also execute SNNs with spiking-MaxPooling layers on Intel's Loihi neuromorphic hardware (with MNIST, FMNIST, & CIFAR10 dataset); thus, showing the feasibility of our approach.
Active Perception and Representation for Robotic Manipulation
Mar 15, 2020
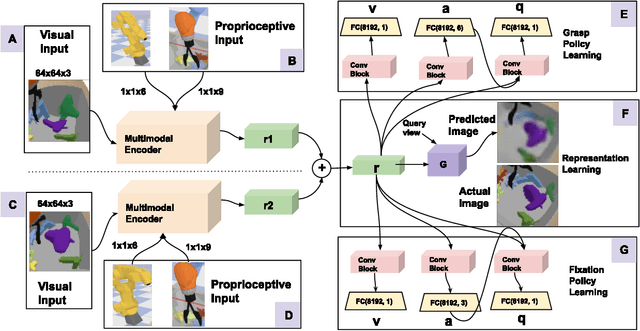

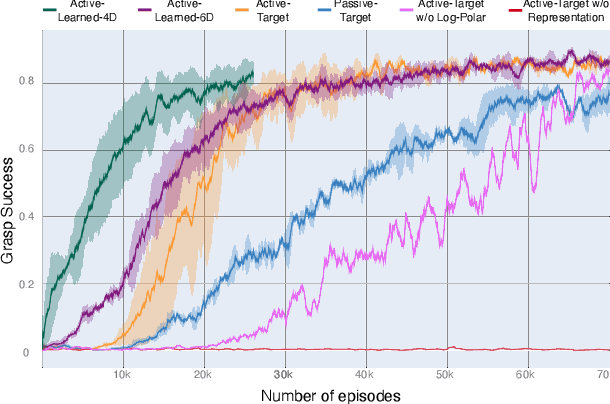
The vast majority of visual animals actively control their eyes, heads, and/or bodies to direct their gaze toward different parts of their environment. In contrast, recent applications of reinforcement learning in robotic manipulation employ cameras as passive sensors. These are carefully placed to view a scene from a fixed pose. Active perception allows animals to gather the most relevant information about the world and focus their computational resources where needed. It also enables them to view objects from different distances and viewpoints, providing a rich visual experience from which to learn abstract representations of the environment. Inspired by the primate visual-motor system, we present a framework that leverages the benefits of active perception to accomplish manipulation tasks. Our agent uses viewpoint changes to localize objects, to learn state representations in a self-supervised manner, and to perform goal-directed actions. We apply our model to a simulated grasping task with a 6-DoF action space. Compared to its passive, fixed-camera counterpart, the active model achieves 8% better performance in targeted grasping. Compared to vanilla deep Q-learning algorithms, our model is at least four times more sample-efficient, highlighting the benefits of both active perception and representation learning.
A dataset of 40K naturalistic 6-degree-of-freedom robotic grasp demonstrations
Dec 31, 2018
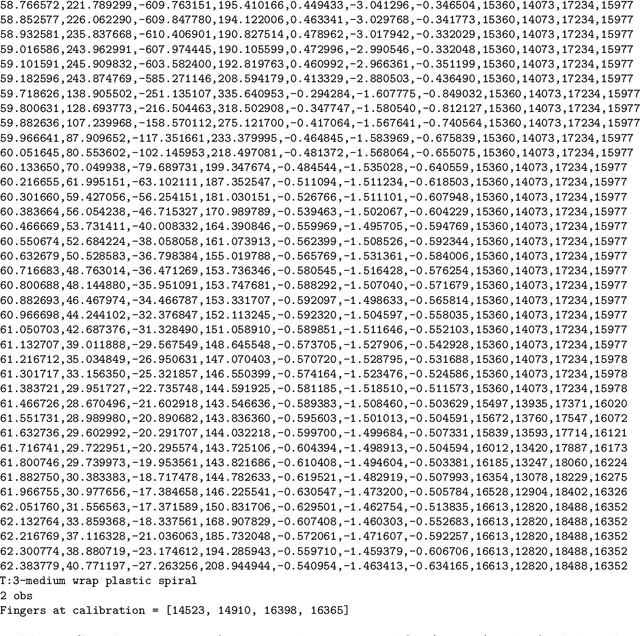


Modern approaches to grasp planning often involve deep learning. However, there are only a few large datasets of labelled grasping examples on physical robots, and available datasets involve relatively simple planar grasps with two-fingered grippers. Here we present: 1) a new human grasp demonstration method that facilitates rapid collection of naturalistic grasp examples, with full six-degree-of-freedom gripper positioning; and 2) a dataset of roughly forty thousand successful grasps on 109 different rigid objects with the RightHand Robotics three-fingered ReFlex gripper.
Convolutional Neural Networks Regularized by Correlated Noise
Apr 03, 2018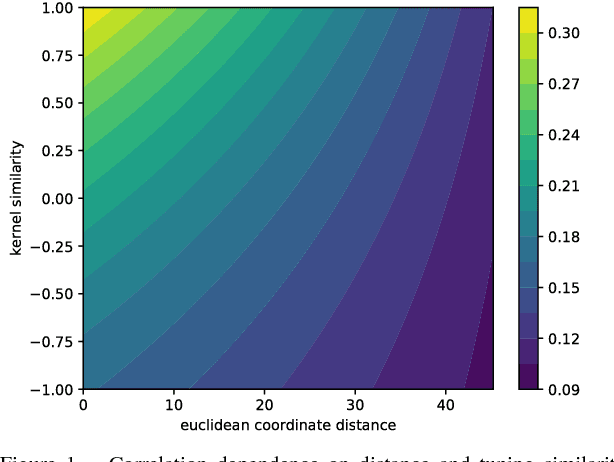
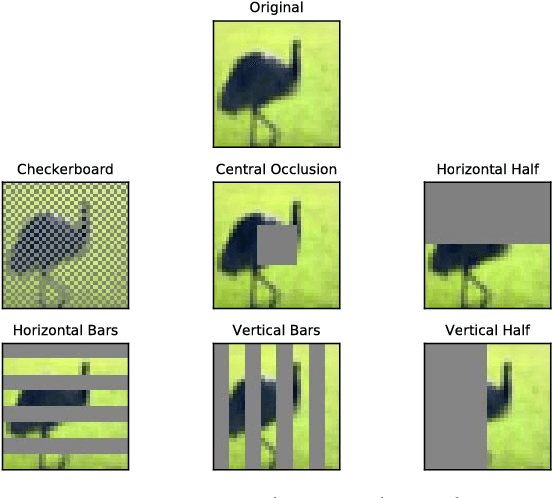

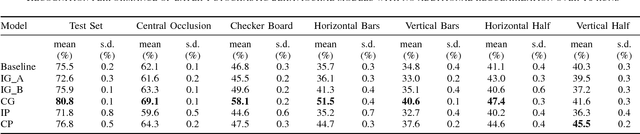
Neurons in the visual cortex are correlated in their variability. The presence of correlation impacts cortical processing because noise cannot be averaged out over many neurons. In an effort to understand the functional purpose of correlated variability, we implement and evaluate correlated noise models in deep convolutional neural networks. Inspired by the cortex, correlation is defined as a function of the distance between neurons and their selectivity. We show how to sample from high-dimensional correlated distributions while keeping the procedure differentiable, so that back-propagation can proceed as usual. The impact of correlated variability is evaluated on the classification of occluded and non-occluded images with and without the presence of other regularization techniques, such as dropout. More work is needed to understand the effects of correlations in various conditions, however in 10/12 of the cases we studied, the best performance on occluded images was obtained from a model with correlated noise.