 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline-to-online Reinforcement Learning for Image-based Grasping with Scarce Demonstrations
Oct 19, 2024

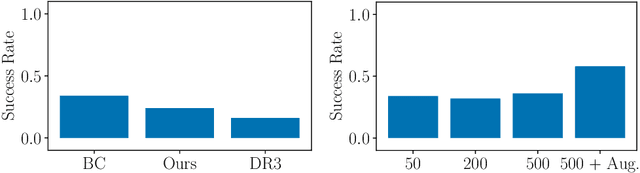
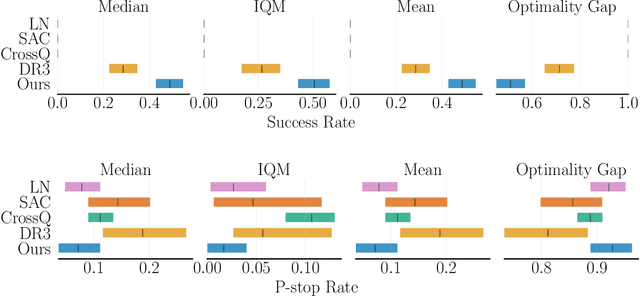
Offline-to-online reinforcement learning (O2O RL) aims to obtain a continually improving policy as it interacts with the environment, while ensuring the initial behaviour is satisficing. This satisficing behaviour is necessary for robotic manipulation where random exploration can be costly due to catastrophic failures and time. O2O RL is especially compelling when we can only obtain a scarce amount of (potentially suboptimal) demonstrations$\unicode{x2014}$a scenario where behavioural cloning (BC) is known to suffer from distribution shift. Previous works have outlined the challenges in applying O2O RL algorithms under the image-based environments. In this work, we propose a novel O2O RL algorithm that can learn in a real-life image-based robotic vacuum grasping task with a small number of demonstrations where BC fails majority of the time. The proposed algorithm replaces the target network in off-policy actor-critic algorithms with a regularization technique inspired by neural tangent kernel. We demonstrate that the proposed algorithm can reach above 90% success rate in under two hours of interaction time, with only 50 human demonstrations, while BC and two commonly-used RL algorithms fail to achieve similar performance.
Revisiting Sparse Rewards for Goal-Reaching Reinforcement Learning
Jul 08, 2024



Many real-world robot learning problems, such as pick-and-place or arriving at a destination, can be seen as a problem of reaching a goal state as soon as possible. These problems, when formulated as episodic reinforcement learning tasks, can easily be specified to align well with our intended goal: -1 reward every time step with termination upon reaching the goal state, called minimum-time tasks. Despite this simplicity, such formulations are often overlooked in favor of dense rewards due to their perceived difficulty and lack of informativeness. Our studies contrast the two reward paradigms, revealing that the minimum-time task specification not only facilitates learning higher-quality policies but can also surpass dense-reward-based policies on their own performance metrics. Crucially, we also identify the goal-hit rate of the initial policy as a robust early indicator for learning success in such sparse feedback settings. Finally, using four distinct real-robotic platforms, we show that it is possible to learn pixel-based policies from scratch within two to three hours using constant negative rewards.
Revisiting Constant Negative Rewards for Goal-Reaching Tasks in Robot Learning
Jun 29, 2024Many real-world robot learning problems, such as pick-and-place or arriving at a destination, can be seen as a problem of reaching a goal state as soon as possible. These problems, when formulated as episodic reinforcement learning tasks, can easily be specified to align well with our intended goal: -1 reward every time step with termination upon reaching the goal state, called minimum-time tasks. Despite this simplicity, such formulations are often overlooked in favor of dense rewards due to their perceived difficulty and lack of informativeness. Our studies contrast the two reward paradigms, revealing that the minimum-time task specification not only facilitates learning higher-quality policies but can also surpass dense-reward-based policies on their own performance metrics. Crucially, we also identify the goal-hit rate of the initial policy as a robust early indicator for learning success in such sparse feedback settings. Finally, using four distinct real-robotic platforms, we show that it is possible to learn pixel-based policies from scratch within two to three hours using constant negative rewards.
A Statistical Guarantee for Representation Transfer in Multitask Imitation Learning
Nov 02, 2023


Transferring representation for multitask imitation learning has the potential to provide improved sample efficiency on learning new tasks, when compared to learning from scratch. In this work, we provide a statistical guarantee indicating that we can indeed achieve improved sample efficiency on the target task when a representation is trained using sufficiently diverse source tasks. Our theoretical results can be readily extended to account for commonly used neural network architectures with realistic assumptions. We conduct empirical analyses that align with our theoretical findings on four simulated environments$\unicode{x2014}$in particular leveraging more data from source tasks can improve sample efficiency on learning in the new task.
Active Perception and Representation for Robotic Manipulation
Mar 15, 2020
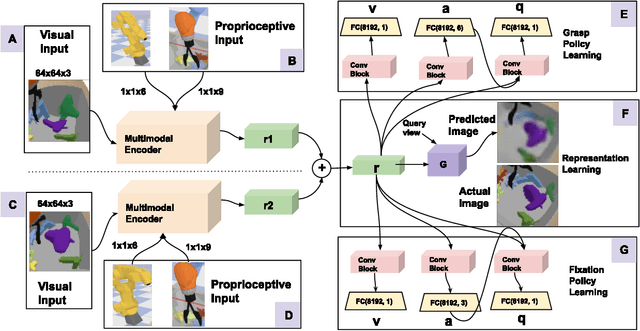

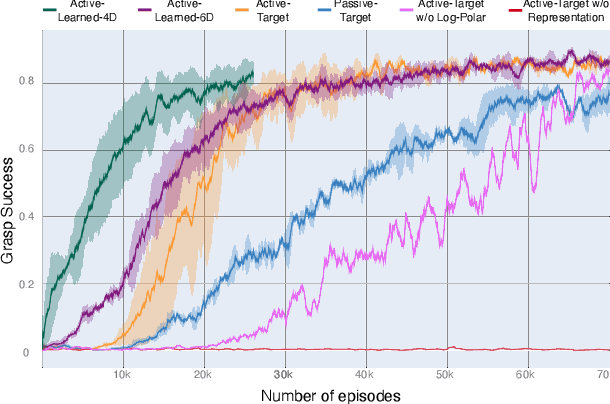
The vast majority of visual animals actively control their eyes, heads, and/or bodies to direct their gaze toward different parts of their environment. In contrast, recent applications of reinforcement learning in robotic manipulation employ cameras as passive sensors. These are carefully placed to view a scene from a fixed pose. Active perception allows animals to gather the most relevant information about the world and focus their computational resources where needed. It also enables them to view objects from different distances and viewpoints, providing a rich visual experience from which to learn abstract representations of the environment. Inspired by the primate visual-motor system, we present a framework that leverages the benefits of active perception to accomplish manipulation tasks. Our agent uses viewpoint changes to localize objects, to learn state representations in a self-supervised manner, and to perform goal-directed actions. We apply our model to a simulated grasping task with a 6-DoF action space. Compared to its passive, fixed-camera counterpart, the active model achieves 8% better performance in targeted grasping. Compared to vanilla deep Q-learning algorithms, our model is at least four times more sample-efficient, highlighting the benefits of both active perception and representation learning.
Autoregressive Policies for Continuous Control Deep Reinforcement Learning
Mar 27, 2019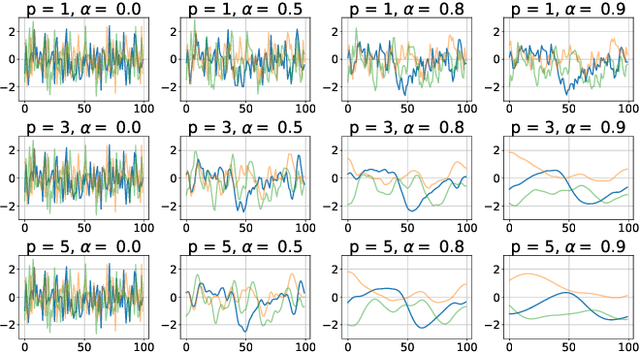
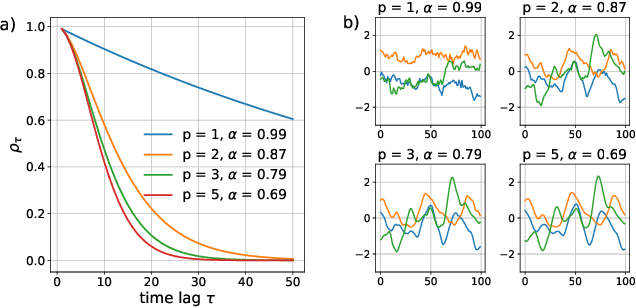
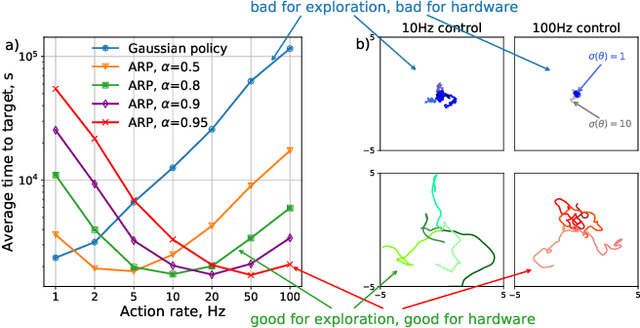
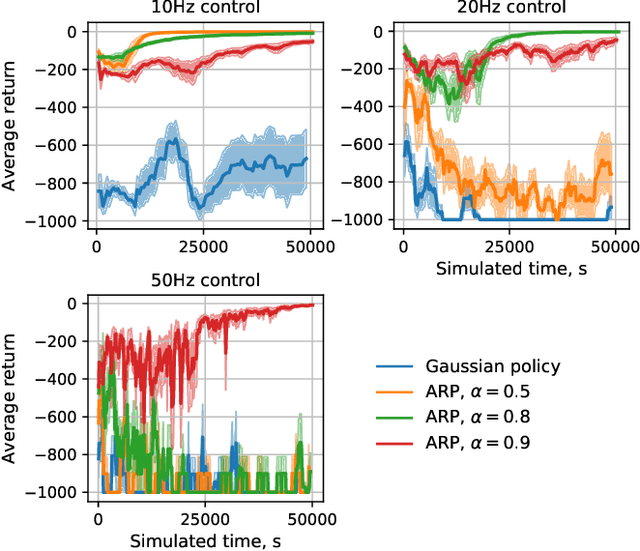
Reinforcement learning algorithms rely on exploration to discover new behaviors, which is typically achieved by following a stochastic policy. In continuous control tasks, policies with a Gaussian distribution have been widely adopted. Gaussian exploration however does not result in smooth trajectories that generally correspond to safe and rewarding behaviors in practical tasks. In addition, Gaussian policies do not result in an effective exploration of an environment and become increasingly inefficient as the action rate increases. This contributes to a low sample efficiency often observed in learning continuous control tasks. We introduce a family of stationary autoregressive (AR) stochastic processes to facilitate exploration in continuous control domains. We show that proposed processes possess two desirable features: subsequent process observations are temporally coherent with continuously adjustable degree of coherence, and the process stationary distribution is standard normal. We derive an autoregressive policy (ARP) that implements such processes maintaining the standard agent-environment interface. We show how ARPs can be easily used with the existing off-the-shelf learning algorithms. Empirically we demonstrate that using ARPs results in improved exploration and sample efficiency in both simulated and real world domains, and, furthermore, provides smooth exploration trajectories that enable safe operation of robotic hardware.
Benchmarking Reinforcement Learning Algorithms on Real-World Robots
Sep 20, 2018
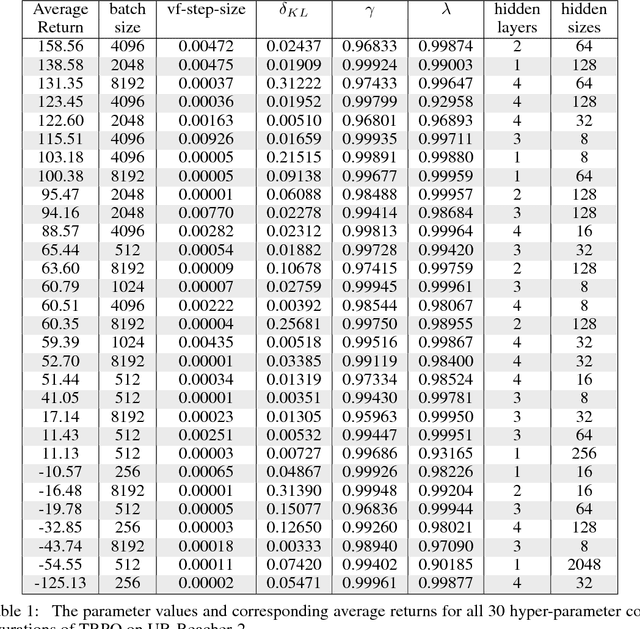
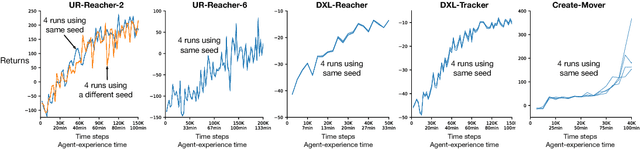
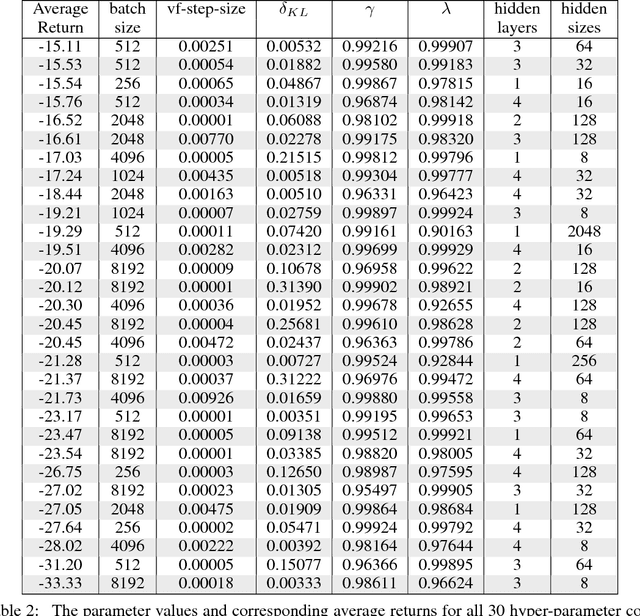
Through many recent successes in simulation, model-free reinforcement learning has emerged as a promising approach to solving continuous control robotic tasks. The research community is now able to reproduce, analyze and build quickly on these results due to open source implementations of learning algorithms and simulated benchmark tasks. To carry forward these successes to real-world applications, it is crucial to withhold utilizing the unique advantages of simulations that do not transfer to the real world and experiment directly with physical robots. However, reinforcement learning research with physical robots faces substantial resistance due to the lack of benchmark tasks and supporting source code. In this work, we introduce several reinforcement learning tasks with multiple commercially available robots that present varying levels of learning difficulty, setup, and repeatability. On these tasks, we test the learning performance of off-the-shelf implementations of four reinforcement learning algorithms and analyze sensitivity to their hyper-parameters to determine their readiness for applications in various real-world tasks. Our results show that with a careful setup of the task interface and computations, some of these implementations can be readily applicable to physical robots. We find that state-of-the-art learning algorithms are highly sensitive to their hyper-parameters and their relative ordering does not transfer across tasks, indicating the necessity of re-tuning them for each task for best performance. On the other hand, the best hyper-parameter configuration from one task may often result in effective learning on held-out tasks even with different robots, providing a reasonable default. We make the benchmark tasks publicly available to enhance reproducibility in real-world reinforcement learning.
Setting up a Reinforcement Learning Task with a Real-World Robot
Mar 19, 2018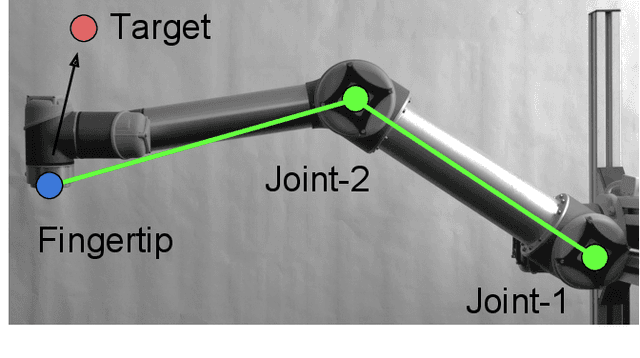
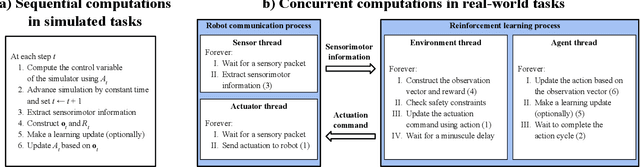

Reinforcement learning is a promising approach to developing hard-to-engineer adaptive solutions for complex and diverse robotic tasks. However, learning with real-world robots is often unreliable and difficult, which resulted in their low adoption in reinforcement learning research. This difficulty is worsened by the lack of guidelines for setting up learning tasks with robots. In this work, we develop a learning task with a UR5 robotic arm to bring to light some key elements of a task setup and study their contributions to the challenges with robots. We find that learning performance can be highly sensitive to the setup, and thus oversights and omissions in setup details can make effective learning, reproducibility, and fair comparison hard. Our study suggests some mitigating steps to help future experimenters avoid difficulties and pitfalls. We show that highly reliable and repeatable experiments can be performed in our setup, indicating the possibility of reinforcement learning research extensively based on real-world robots.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016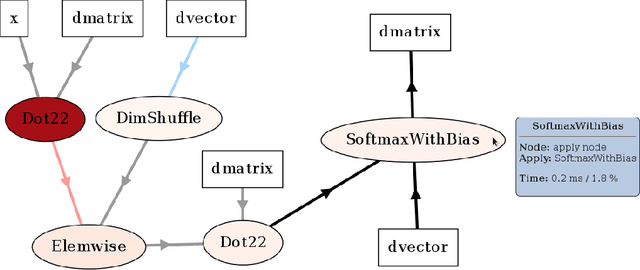
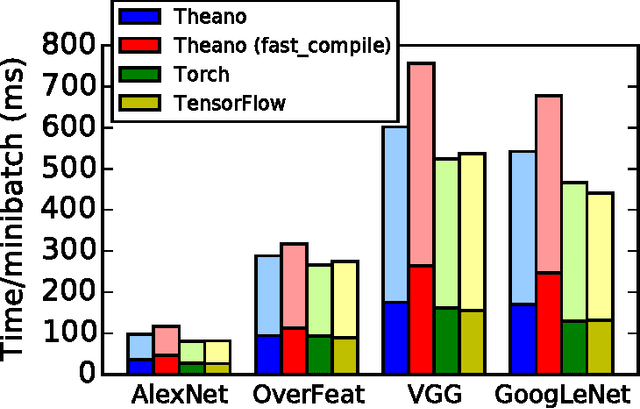
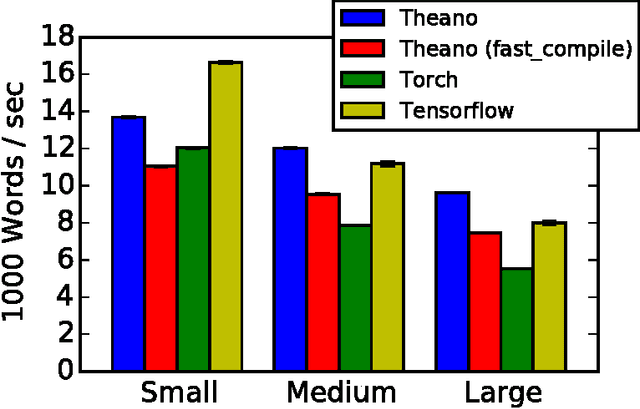
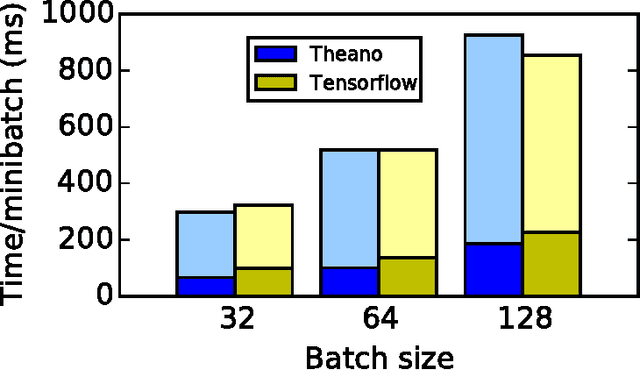
Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.
Pylearn2: a machine learning research library
Aug 20, 2013Pylearn2 is a machine learning research library. This does not just mean that it is a collection of machine learning algorithms that share a common API; it means that it has been designed for flexibility and extensibility in order to facilitate research projects that involve new or unusual use cases. In this paper we give a brief history of the library, an overview of its basic philosophy, a summary of the library's architecture, and a description of how the Pylearn2 community functions socially.