 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Perception and Representation for Robotic Manipulation
Paper and Code
Mar 15, 2020
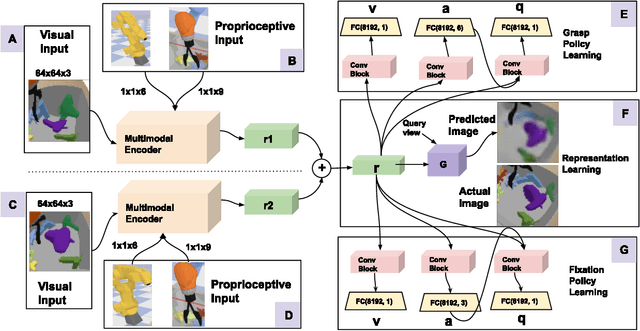

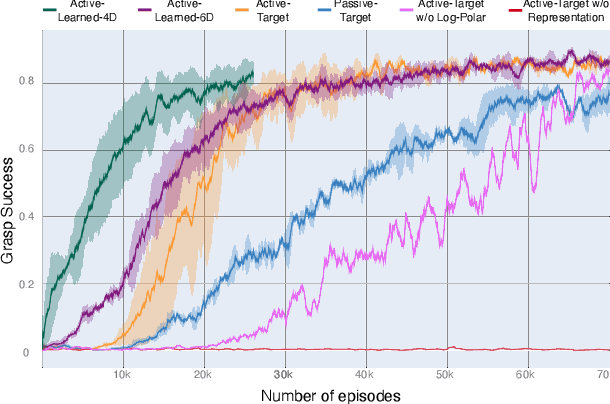
The vast majority of visual animals actively control their eyes, heads, and/or bodies to direct their gaze toward different parts of their environment. In contrast, recent applications of reinforcement learning in robotic manipulation employ cameras as passive sensors. These are carefully placed to view a scene from a fixed pose. Active perception allows animals to gather the most relevant information about the world and focus their computational resources where needed. It also enables them to view objects from different distances and viewpoints, providing a rich visual experience from which to learn abstract representations of the environment. Inspired by the primate visual-motor system, we present a framework that leverages the benefits of active perception to accomplish manipulation tasks. Our agent uses viewpoint changes to localize objects, to learn state representations in a self-supervised manner, and to perform goal-directed actions. We apply our model to a simulated grasping task with a 6-DoF action space. Compared to its passive, fixed-camera counterpart, the active model achieves 8% better performance in targeted grasping. Compared to vanilla deep Q-learning algorithms, our model is at least four times more sample-efficient, highlighting the benefits of both active perception and representation learning.