 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSangam: Chiplet-Based DRAM-PIM Accelerator with CXL Integration for LLM Inferencing
Nov 15, 2025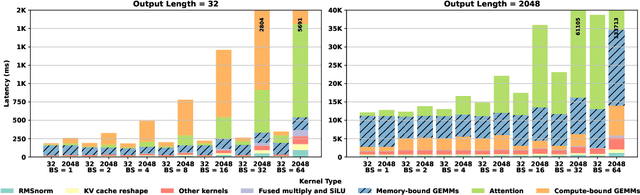
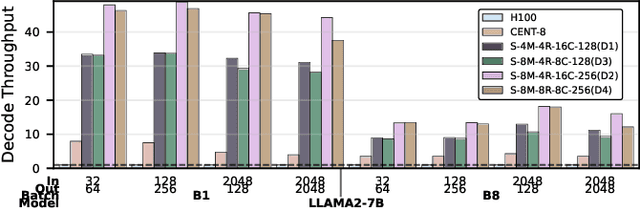
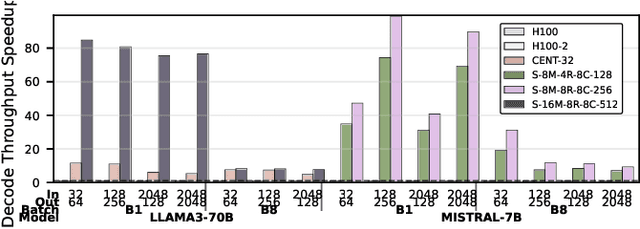
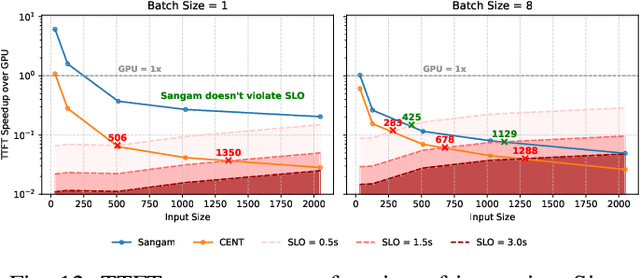
Large Language Models (LLMs) are becoming increasingly data-intensive due to growing model sizes, and they are becoming memory-bound as the context length and, consequently, the key-value (KV) cache size increase. Inference, particularly the decoding phase, is dominated by memory-bound GEMV or flat GEMM operations with low operational intensity (OI), making it well-suited for processing-in-memory (PIM) approaches. However, existing in/near-memory solutions face critical limitations such as reduced memory capacity due to the high area cost of integrating processing elements (PEs) within DRAM chips, and limited PE capability due to the constraints of DRAM fabrication technology. This work presents a chiplet-based memory module that addresses these limitations by decoupling logic and memory into chiplets fabricated in heterogeneous technology nodes and connected via an interposer. The logic chiplets sustain high bandwidth access to the DRAM chiplets, which house the memory banks, and enable the integration of advanced processing components such as systolic arrays and SRAM-based buffers to accelerate memory-bound GEMM kernels, capabilities that were not feasible in prior PIM architectures. We propose Sangam, a CXL-attached PIM-chiplet based memory module that can either act as a drop-in replacement for GPUs or co-executes along side the GPUs. Sangam achieves speedup of 3.93, 4.22, 2.82x speedup in end-to-end query latency, 10.3, 9.5, 6.36x greater decoding throughput, and order of magnitude energy savings compared to an H100 GPU for varying input size, output length, and batch size on LLaMA 2-7B, Mistral-7B, and LLaMA 3-70B, respectively.
Benchmarking Large Language Models for Automated Verilog RTL Code Generation
Dec 13, 2022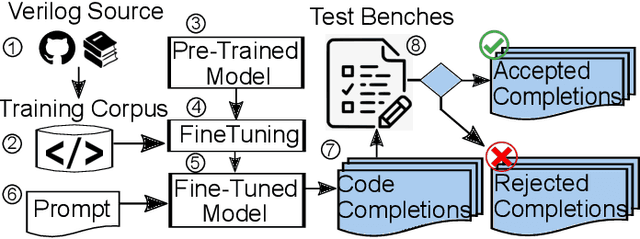



Automating hardware design could obviate a significant amount of human error from the engineering process and lead to fewer errors. Verilog is a popular hardware description language to model and design digital systems, thus generating Verilog code is a critical first step. Emerging large language models (LLMs) are able to write high-quality code in other programming languages. In this paper, we characterize the ability of LLMs to generate useful Verilog. For this, we fine-tune pre-trained LLMs on Verilog datasets collected from GitHub and Verilog textbooks. We construct an evaluation framework comprising test-benches for functional analysis and a flow to test the syntax of Verilog code generated in response to problems of varying difficulty. Our findings show that across our problem scenarios, the fine-tuning results in LLMs more capable of producing syntactically correct code (25.9% overall). Further, when analyzing functional correctness, a fine-tuned open-source CodeGen LLM can outperform the state-of-the-art commercial Codex LLM (6.5% overall). Training/evaluation scripts and LLM checkpoints are available: https://github.com/shailja-thakur/VGen.