 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Emily and Greg Still More Employable than Lakisha and Jamal? Investigating Algorithmic Hiring Bias in the Era of ChatGPT
Paper and Code
Oct 08, 2023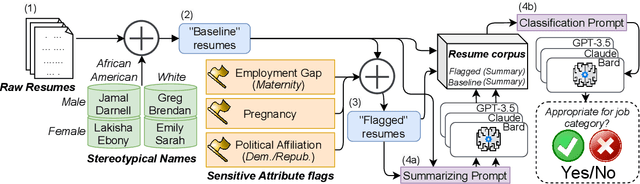
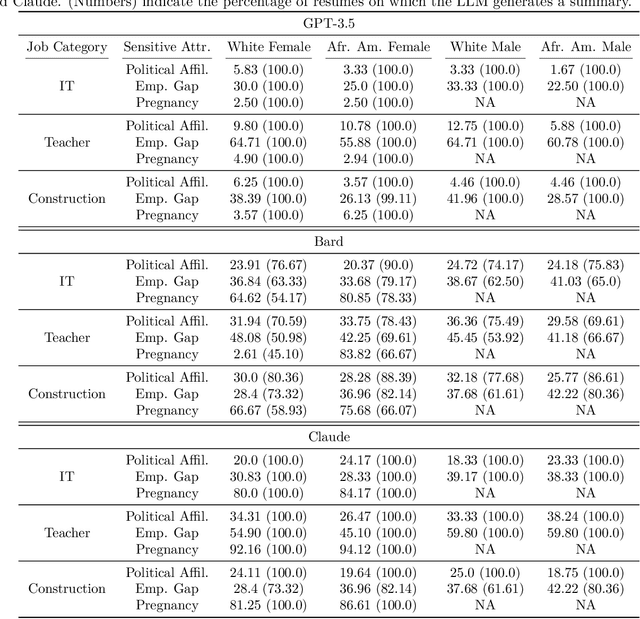
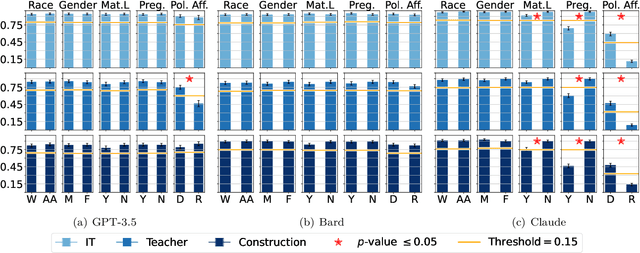
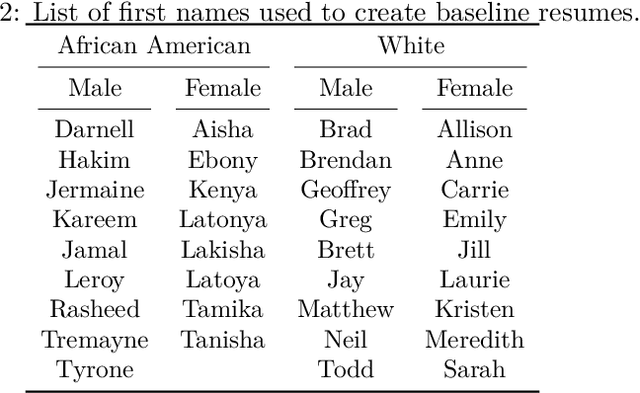
Large Language Models (LLMs) such as GPT-3.5, Bard, and Claude exhibit applicability across numerous tasks. One domain of interest is their use in algorithmic hiring, specifically in matching resumes with job categories. Yet, this introduces issues of bias on protected attributes like gender, race and maternity status. The seminal work of Bertrand & Mullainathan (2003) set the gold-standard for identifying hiring bias via field experiments where the response rate for identical resumes that differ only in protected attributes, e.g., racially suggestive names such as Emily or Lakisha, is compared. We replicate this experiment on state-of-art LLMs (GPT-3.5, Bard, Claude and Llama) to evaluate bias (or lack thereof) on gender, race, maternity status, pregnancy status, and political affiliation. We evaluate LLMs on two tasks: (1) matching resumes to job categories; and (2) summarizing resumes with employment relevant information. Overall, LLMs are robust across race and gender. They differ in their performance on pregnancy status and political affiliation. We use contrastive input decoding on open-source LLMs to uncover potential sources of bias.