 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Retrieval-Augmented Generation for Medicine: A Large-Scale, Systematic Expert Evaluation and Practical Insights
Nov 10, 2025Large language models (LLMs) are transforming the landscape of medicine, yet two fundamental challenges persist: keeping up with rapidly evolving medical knowledge and providing verifiable, evidence-grounded reasoning. Retrieval-augmented generation (RAG) has been widely adopted to address these limitations by supplementing model outputs with retrieved evidence. However, whether RAG reliably achieves these goals remains unclear. Here, we present the most comprehensive expert evaluation of RAG in medicine to date. Eighteen medical experts contributed a total of 80,502 annotations, assessing 800 model outputs generated by GPT-4o and Llama-3.1-8B across 200 real-world patient and USMLE-style queries. We systematically decomposed the RAG pipeline into three components: (i) evidence retrieval (relevance of retrieved passages), (ii) evidence selection (accuracy of evidence usage), and (iii) response generation (factuality and completeness of outputs). Contrary to expectation, standard RAG often degraded performance: only 22% of top-16 passages were relevant, evidence selection remained weak (precision 41-43%, recall 27-49%), and factuality and completeness dropped by up to 6% and 5%, respectively, compared with non-RAG variants. Retrieval and evidence selection remain key failure points for the model, contributing to the overall performance drop. We further show that simple yet effective strategies, including evidence filtering and query reformulation, substantially mitigate these issues, improving performance on MedMCQA and MedXpertQA by up to 12% and 8.2%, respectively. These findings call for re-examining RAG's role in medicine and highlight the importance of stage-aware evaluation and deliberate system design for reliable medical LLM applications.
Supervised Fine-Tuning LLMs to Behave as Pedagogical Agents in Programming Education
Feb 27, 2025Large language models (LLMs) are increasingly being explored in higher education, yet their effectiveness as teaching agents remains underexamined. In this paper, we present the development of GuideLM, a fine-tuned LLM designed for programming education. GuideLM has been integrated into the Debugging C Compiler (DCC), an educational C compiler that leverages LLMs to generate pedagogically sound error explanations. Previously, DCC relied on off-the-shelf OpenAI models, which, while accurate, often over-assisted students by directly providing solutions despite contrary prompting. To address this, we employed supervised fine-tuning (SFT) on a dataset of 528 student-question/teacher-answer pairs, creating two models: GuideLM and GuideLM-mini, fine-tuned on ChatGPT-4o and 4o-mini, respectively. We conducted an expert analysis of 400 responses per model, comparing their pedagogical effectiveness against base OpenAI models. Our evaluation, grounded in constructivism and cognitive load theory, assessed factors such as conceptual scaffolding, clarity, and Socratic guidance. Results indicate that GuideLM and GuideLM-mini improve pedagogical performance, with an 8% increase in Socratic guidance and a 58% improvement in economy of words compared to GPT-4o. However, this refinement comes at the cost of a slight reduction in general accuracy. While further work is needed, our findings suggest that fine-tuning LLMs with targeted datasets is a promising approach for developing models better suited to educational contexts.
Towards Pedagogical LLMs with Supervised Fine Tuning for Computing Education
Nov 04, 2024This paper investigates supervised fine-tuning of large language models (LLMs) to improve their pedagogical alignment in computing education, addressing concerns that LLMs may hinder learning outcomes. The project utilised a proprietary dataset of 2,500 high quality question/answer pairs from programming course forums, and explores two research questions: the suitability of university course forums in contributing to fine-tuning datasets, and how supervised fine-tuning can improve LLMs' alignment with educational principles such as constructivism. Initial findings suggest benefits in pedagogical alignment of LLMs, with deeper evaluations required.
Scaling CS1 Support with Compiler-Integrated Conversational AI
Jul 22, 2024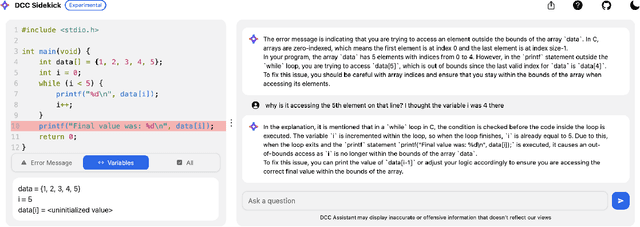

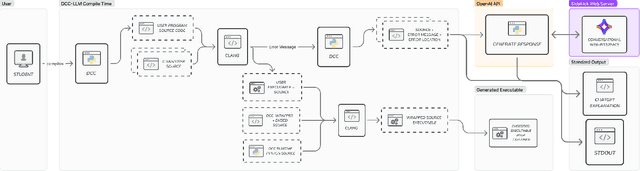
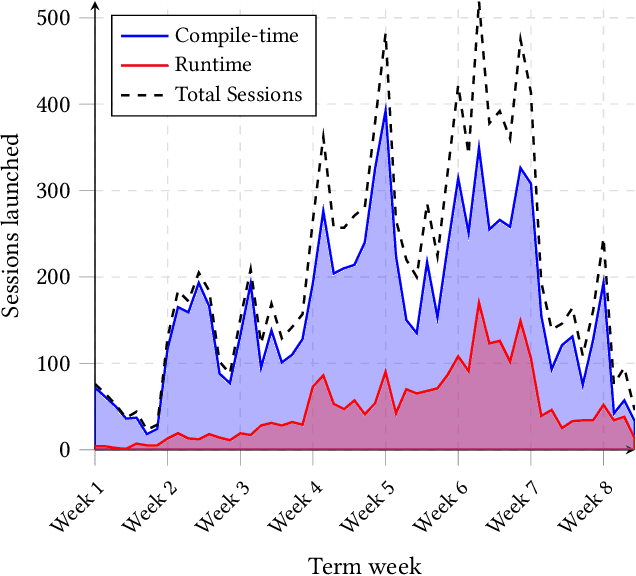
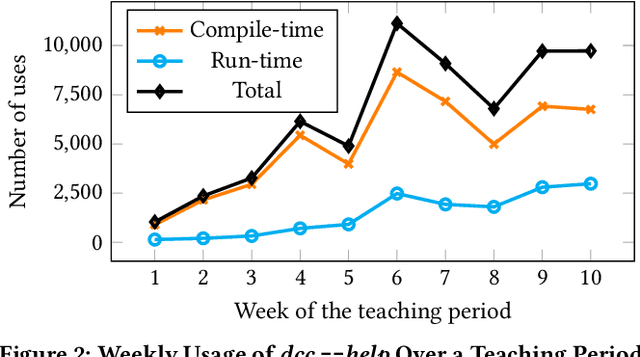
This paper introduces DCC Sidekick, a web-based conversational AI tool that enhances an existing LLM-powered C/C++ compiler by generating educational programming error explanations. The tool seamlessly combines code display, compile- and run-time error messages, and stack frame read-outs alongside an AI interface, leveraging compiler error context for improved explanations. We analyse usage data from a large Australian CS1 course, where 959 students engaged in 11,222 DCC Sidekick sessions, resulting in 17,982 error explanations over seven weeks. Notably, over 50% of interactions occurred outside business hours, underscoring the tool's value as an always-available resource. Our findings reveal strong adoption of AI-assisted debugging tools, demonstrating their scalability in supporting extensive CS1 courses. We provide implementation insights and recommendations for educators seeking to incorporate AI tools with appropriate pedagogical safeguards.
MedCalc-Bench: Evaluating Large Language Models for Medical Calculations
Jun 17, 2024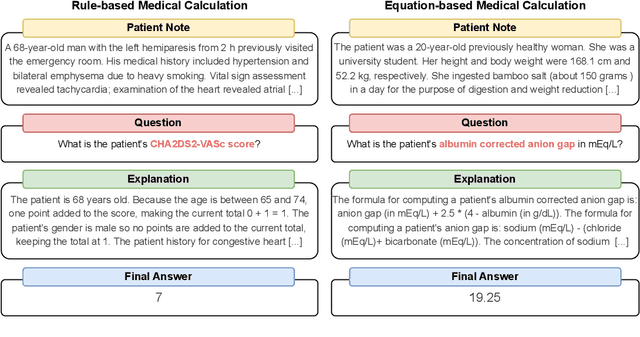
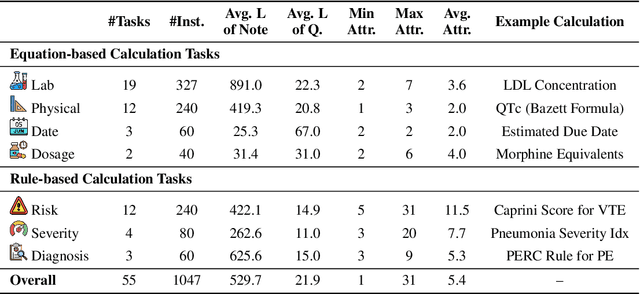
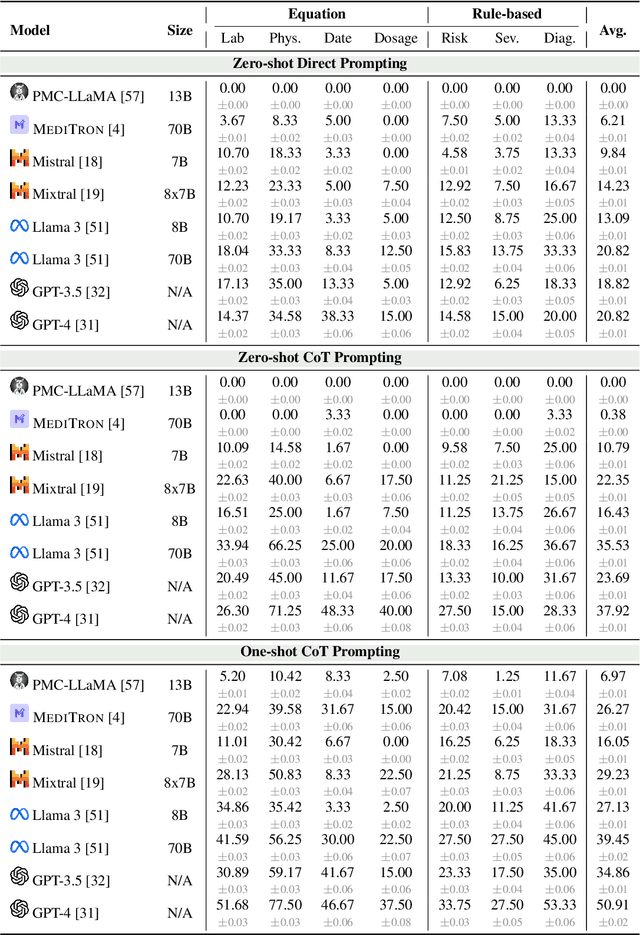
As opposed to evaluating computation and logic-based reasoning, current bench2 marks for evaluating large language models (LLMs) in medicine are primarily focused on question-answering involving domain knowledge and descriptive rea4 soning. While such qualitative capabilities are vital to medical diagnosis, in real5 world scenarios, doctors frequently use clinical calculators that follow quantitative equations and rule-based reasoning paradigms for evidence-based decision support. To this end, we propose MedCalc-Bench, a first-of-its-kind dataset focused on evaluating the medical calculation capability of LLMs. MedCalc-Bench contains an evaluation set of over 1000 manually reviewed instances from 55 different medical calculation tasks. Each instance in MedCalc-Bench consists of a patient note, a question requesting to compute a specific medical value, a ground truth answer, and a step-by-step explanation showing how the answer is obtained. While our evaluation results show the potential of LLMs in this area, none of them are effective enough for clinical settings. Common issues include extracting the incorrect entities, not using the correct equation or rules for a calculation task, or incorrectly performing the arithmetic for the computation. We hope our study highlights the quantitative knowledge and reasoning gaps in LLMs within medical settings, encouraging future improvements of LLMs for various clinical calculation tasks.
AgentMD: Empowering Language Agents for Risk Prediction with Large-Scale Clinical Tool Learning
Feb 20, 2024Clinical calculators play a vital role in healthcare by offering accurate evidence-based predictions for various purposes such as prognosis. Nevertheless, their widespread utilization is frequently hindered by usability challenges, poor dissemination, and restricted functionality. Augmenting large language models with extensive collections of clinical calculators presents an opportunity to overcome these obstacles and improve workflow efficiency, but the scalability of the manual curation process poses a significant challenge. In response, we introduce AgentMD, a novel language agent capable of curating and applying clinical calculators across various clinical contexts. Using the published literature, AgentMD has automatically curated a collection of 2,164 diverse clinical calculators with executable functions and structured documentation, collectively named RiskCalcs. Manual evaluations show that RiskCalcs tools achieve an accuracy of over 80% on three quality metrics. At inference time, AgentMD can automatically select and apply the relevant RiskCalcs tools given any patient description. On the newly established RiskQA benchmark, AgentMD significantly outperforms chain-of-thought prompting with GPT-4 (87.7% vs. 40.9% in accuracy). Additionally, we also applied AgentMD to real-world clinical notes for analyzing both population-level and risk-level patient characteristics. In summary, our study illustrates the utility of language agents augmented with clinical calculators for healthcare analytics and patient care.
Integrating Large Language Models into the Debugging C Compiler for generating contextual error explanations
Aug 23, 2023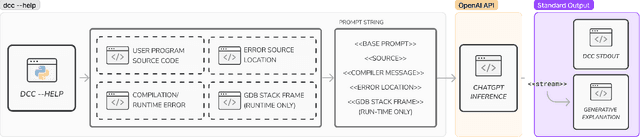
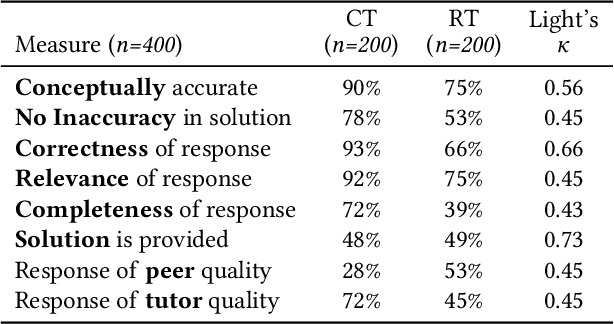
This paper introduces a method for Large Language Models (LLM) to produce enhanced compiler error explanations, in simple language, within our Debugging C Compiler (DCC). It is well documented that compiler error messages have been known to present a barrier for novices learning how to program. Although our initial use of DCC in introductory programming (CS1) has been instrumental in teaching C to novice programmers by providing safeguards to commonly occurring errors and translating the usually cryptic compiler error messages at both compile- and run-time, we proposed that incorporating LLM-generated explanations would further enhance the learning experience for novice programmers. Through an expert evaluation, we observed that LLM-generated explanations for compiler errors were conceptually accurate in 90% of compile-time errors, and 75% of run-time errors. Additionally, the new DCC-help tool has been increasingly adopted by students, with an average of 1047 unique runs per week, demonstrating a promising initial assessment of using LLMs to complement compiler output to enhance programming education for beginners. We release our tool as open-source to the community.
MotionInput v2.0 supporting DirectX: A modular library of open-source gesture-based machine learning and computer vision methods for interacting and controlling existing software with a webcam
Aug 10, 2021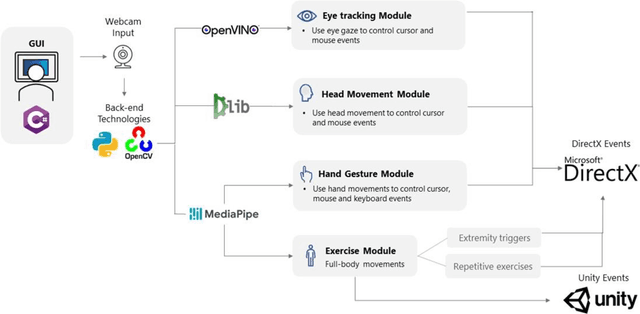
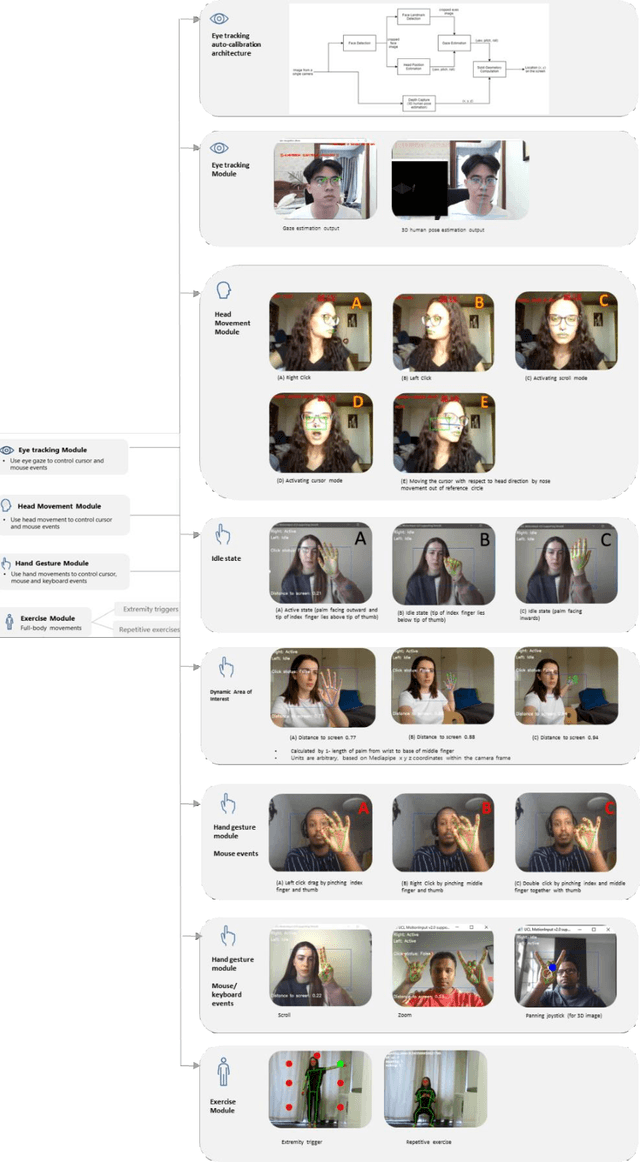
Touchless computer interaction has become an important consideration during the COVID-19 pandemic period. Despite progress in machine learning and computer vision that allows for advanced gesture recognition, an integrated collection of such open-source methods and a user-customisable approach to utilising them in a low-cost solution for touchless interaction in existing software is still missing. In this paper, we introduce the MotionInput v2.0 application. This application utilises published open-source libraries and additional gesture definitions developed to take the video stream from a standard RGB webcam as input. It then maps human motion gestures to input operations for existing applications and games. The user can choose their own preferred way of interacting from a series of motion types, including single and bi-modal hand gesturing, full-body repetitive or extremities-based exercises, head and facial movements, eye tracking, and combinations of the above. We also introduce a series of bespoke gesture recognition classifications as DirectInput triggers, including gestures for idle states, auto calibration, depth capture from a 2D RGB webcam stream and tracking of facial motions such as mouth motions, winking, and head direction with rotation. Three use case areas assisted the development of the modules: creativity software, office and clinical software, and gaming software. A collection of open-source libraries has been integrated and provide a layer of modular gesture mapping on top of existing mouse and keyboard controls in Windows via DirectX. With ease of access to webcams integrated into most laptops and desktop computers, touchless computing becomes more available with MotionInput v2.0, in a federated and locally processed method.
Learning for Safety-Critical Control with Control Barrier Functions
Dec 20, 2019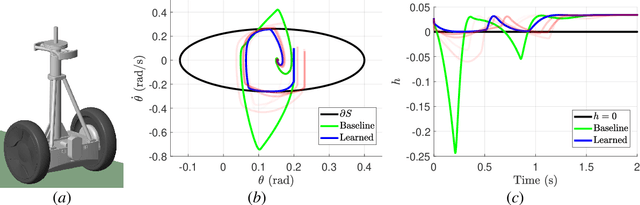
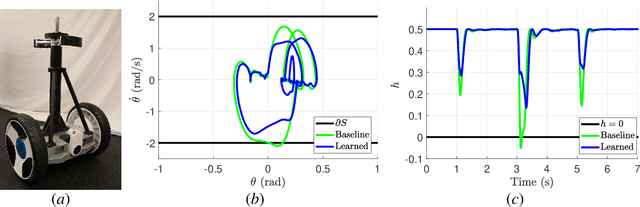
Modern nonlinear control theory seeks to endow systems with properties of stability and safety, and have been deployed successfully in multiple domains. Despite this success, model uncertainty remains a significant challenge in synthesizing safe controllers, leading to degradation in the properties provided by the controllers. This paper develops a machine learning framework utilizing Control Barrier Functions (CBFs) to reduce model uncertainty as it impact the safe behavior of a system. This approach iteratively collects data and updates a controller, ultimately achieving safe behavior. We validate this method in simulation and experimentally on a Segway platform.