 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data
Mar 17, 2024Reconstructions of visual perception from brain activity have improved tremendously, but the practical utility of such methods has been limited. This is because such models are trained independently per subject where each subject requires dozens of hours of expensive fMRI training data to attain high-quality results. The present work showcases high-quality reconstructions using only 1 hour of fMRI training data. We pretrain our model across 7 subjects and then fine-tune on minimal data from a new subject. Our novel functional alignment procedure linearly maps all brain data to a shared-subject latent space, followed by a shared non-linear mapping to CLIP image space. We then map from CLIP space to pixel space by fine-tuning Stable Diffusion XL to accept CLIP latents as inputs instead of text. This approach improves out-of-subject generalization with limited training data and also attains state-of-the-art image retrieval and reconstruction metrics compared to single-subject approaches. MindEye2 demonstrates how accurate reconstructions of perception are possible from a single visit to the MRI facility. All code is available on GitHub.
CheXagent: Towards a Foundation Model for Chest X-Ray Interpretation
Jan 22, 2024



Chest X-rays (CXRs) are the most frequently performed imaging test in clinical practice. Recent advances in the development of vision-language foundation models (FMs) give rise to the possibility of performing automated CXR interpretation, which can assist physicians with clinical decision-making and improve patient outcomes. However, developing FMs that can accurately interpret CXRs is challenging due to the (1) limited availability of large-scale vision-language datasets in the medical image domain, (2) lack of vision and language encoders that can capture the complexities of medical data, and (3) absence of evaluation frameworks for benchmarking the abilities of FMs on CXR interpretation. In this work, we address these challenges by first introducing \emph{CheXinstruct} - a large-scale instruction-tuning dataset curated from 28 publicly-available datasets. We then present \emph{CheXagent} - an instruction-tuned FM capable of analyzing and summarizing CXRs. To build CheXagent, we design a clinical large language model (LLM) for parsing radiology reports, a vision encoder for representing CXR images, and a network to bridge the vision and language modalities. Finally, we introduce \emph{CheXbench} - a novel benchmark designed to systematically evaluate FMs across 8 clinically-relevant CXR interpretation tasks. Extensive quantitative evaluations and qualitative reviews with five expert radiologists demonstrate that CheXagent outperforms previously-developed general- and medical-domain FMs on CheXbench tasks. Furthermore, in an effort to improve model transparency, we perform a fairness evaluation across factors of sex, race and age to highlight potential performance disparities. Our project is at \url{https://stanford-aimi.github.io/chexagent.html}.
Scalable High-Resolution Pixel-Space Image Synthesis with Hourglass Diffusion Transformers
Jan 21, 2024We present the Hourglass Diffusion Transformer (HDiT), an image generative model that exhibits linear scaling with pixel count, supporting training at high-resolution (e.g. $1024 \times 1024$) directly in pixel-space. Building on the Transformer architecture, which is known to scale to billions of parameters, it bridges the gap between the efficiency of convolutional U-Nets and the scalability of Transformers. HDiT trains successfully without typical high-resolution training techniques such as multiscale architectures, latent autoencoders or self-conditioning. We demonstrate that HDiT performs competitively with existing models on ImageNet $256^2$, and sets a new state-of-the-art for diffusion models on FFHQ-$1024^2$.
Label- and slide-free tissue histology using 3D epi-mode quantitative phase imaging and virtual H&E staining
Jun 01, 2023



Histological staining of tissue biopsies, especially hematoxylin and eosin (H&E) staining, serves as the benchmark for disease diagnosis and comprehensive clinical assessment of tissue. However, the process is laborious and time-consuming, often limiting its usage in crucial applications such as surgical margin assessment. To address these challenges, we combine an emerging 3D quantitative phase imaging technology, termed quantitative oblique back illumination microscopy (qOBM), with an unsupervised generative adversarial network pipeline to map qOBM phase images of unaltered thick tissues (i.e., label- and slide-free) to virtually stained H&E-like (vH&E) images. We demonstrate that the approach achieves high-fidelity conversions to H&E with subcellular detail using fresh tissue specimens from mouse liver, rat gliosarcoma, and human gliomas. We also show that the framework directly enables additional capabilities such as H&E-like contrast for volumetric imaging. The quality and fidelity of the vH&E images are validated using both a neural network classifier trained on real H&E images and tested on virtual H&E images, and a user study with neuropathologists. Given its simple and low-cost embodiment and ability to provide real-time feedback in vivo, this deep learning-enabled qOBM approach could enable new workflows for histopathology with the potential to significantly save time, labor, and costs in cancer screening, detection, treatment guidance, and more.
Reconstructing the Mind's Eye: fMRI-to-Image with Contrastive Learning and Diffusion Priors
May 29, 2023
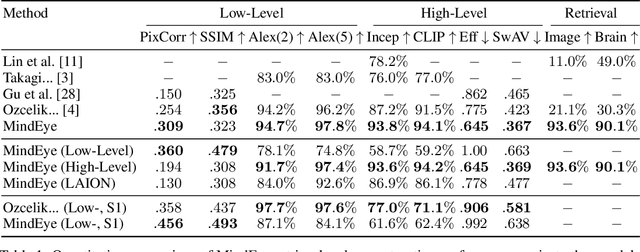
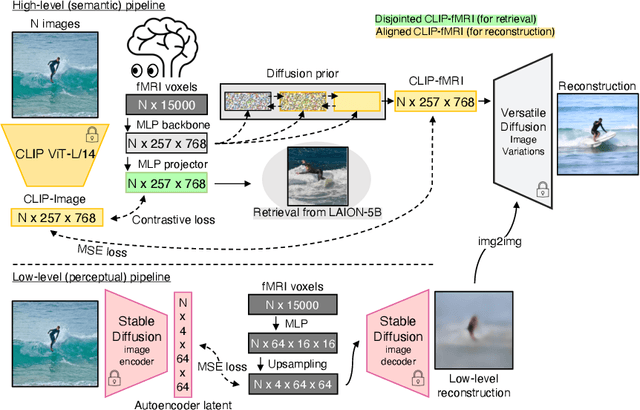
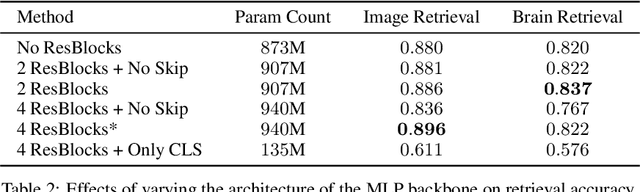
We present MindEye, a novel fMRI-to-image approach to retrieve and reconstruct viewed images from brain activity. Our model comprises two parallel submodules that are specialized for retrieval (using contrastive learning) and reconstruction (using a diffusion prior). MindEye can map fMRI brain activity to any high dimensional multimodal latent space, like CLIP image space, enabling image reconstruction using generative models that accept embeddings from this latent space. We comprehensively compare our approach with other existing methods, using both qualitative side-by-side comparisons and quantitative evaluations, and show that MindEye achieves state-of-the-art performance in both reconstruction and retrieval tasks. In particular, MindEye can retrieve the exact original image even among highly similar candidates indicating that its brain embeddings retain fine-grained image-specific information. This allows us to accurately retrieve images even from large-scale databases like LAION-5B. We demonstrate through ablations that MindEye's performance improvements over previous methods result from specialized submodules for retrieval and reconstruction, improved training techniques, and training models with orders of magnitude more parameters. Furthermore, we show that MindEye can better preserve low-level image features in the reconstructions by using img2img, with outputs from a separate autoencoder. All code is available on GitHub.
RoentGen: Vision-Language Foundation Model for Chest X-ray Generation
Nov 23, 2022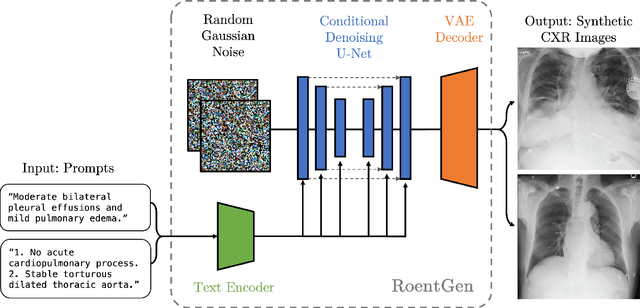



Multimodal models trained on large natural image-text pair datasets have exhibited astounding abilities in generating high-quality images. Medical imaging data is fundamentally different to natural images, and the language used to succinctly capture relevant details in medical data uses a different, narrow but semantically rich, domain-specific vocabulary. Not surprisingly, multi-modal models trained on natural image-text pairs do not tend to generalize well to the medical domain. Developing generative imaging models faithfully representing medical concepts while providing compositional diversity could mitigate the existing paucity of high-quality, annotated medical imaging datasets. In this work, we develop a strategy to overcome the large natural-medical distributional shift by adapting a pre-trained latent diffusion model on a corpus of publicly available chest x-rays (CXR) and their corresponding radiology (text) reports. We investigate the model's ability to generate high-fidelity, diverse synthetic CXR conditioned on text prompts. We assess the model outputs quantitatively using image quality metrics, and evaluate image quality and text-image alignment by human domain experts. We present evidence that the resulting model (RoentGen) is able to create visually convincing, diverse synthetic CXR images, and that the output can be controlled to a new extent by using free-form text prompts including radiology-specific language. Fine-tuning this model on a fixed training set and using it as a data augmentation method, we measure a 5% improvement of a classifier trained jointly on synthetic and real images, and a 3% improvement when trained on a larger but purely synthetic training set. Finally, we observe that this fine-tuning distills in-domain knowledge in the text-encoder and can improve its representation capabilities of certain diseases like pneumothorax by 25%.