 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Video Compression with In-Loop Contextual Filtering and Out-of-Loop Reconstruction Enhancement
Sep 04, 2025This paper explores the application of enhancement filtering techniques in neural video compression. Specifically, we categorize these techniques into in-loop contextual filtering and out-of-loop reconstruction enhancement based on whether the enhanced representation affects the subsequent coding loop. In-loop contextual filtering refines the temporal context by mitigating error propagation during frame-by-frame encoding. However, its influence on both the current and subsequent frames poses challenges in adaptively applying filtering throughout the sequence. To address this, we introduce an adaptive coding decision strategy that dynamically determines filtering application during encoding. Additionally, out-of-loop reconstruction enhancement is employed to refine the quality of reconstructed frames, providing a simple yet effective improvement in coding efficiency. To the best of our knowledge, this work presents the first systematic study of enhancement filtering in the context of conditional-based neural video compression. Extensive experiments demonstrate a 7.71% reduction in bit rate compared to state-of-the-art neural video codecs, validating the effectiveness of the proposed approach.
Label- and slide-free tissue histology using 3D epi-mode quantitative phase imaging and virtual H&E staining
Jun 01, 2023



Histological staining of tissue biopsies, especially hematoxylin and eosin (H&E) staining, serves as the benchmark for disease diagnosis and comprehensive clinical assessment of tissue. However, the process is laborious and time-consuming, often limiting its usage in crucial applications such as surgical margin assessment. To address these challenges, we combine an emerging 3D quantitative phase imaging technology, termed quantitative oblique back illumination microscopy (qOBM), with an unsupervised generative adversarial network pipeline to map qOBM phase images of unaltered thick tissues (i.e., label- and slide-free) to virtually stained H&E-like (vH&E) images. We demonstrate that the approach achieves high-fidelity conversions to H&E with subcellular detail using fresh tissue specimens from mouse liver, rat gliosarcoma, and human gliomas. We also show that the framework directly enables additional capabilities such as H&E-like contrast for volumetric imaging. The quality and fidelity of the vH&E images are validated using both a neural network classifier trained on real H&E images and tested on virtual H&E images, and a user study with neuropathologists. Given its simple and low-cost embodiment and ability to provide real-time feedback in vivo, this deep learning-enabled qOBM approach could enable new workflows for histopathology with the potential to significantly save time, labor, and costs in cancer screening, detection, treatment guidance, and more.
Robust Emotion Recognition from Low Quality and Low Bit Rate Video: A Deep Learning Approach
Sep 10, 2017
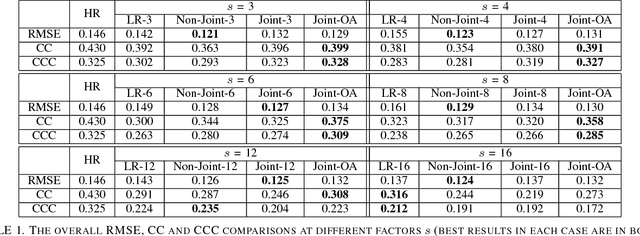

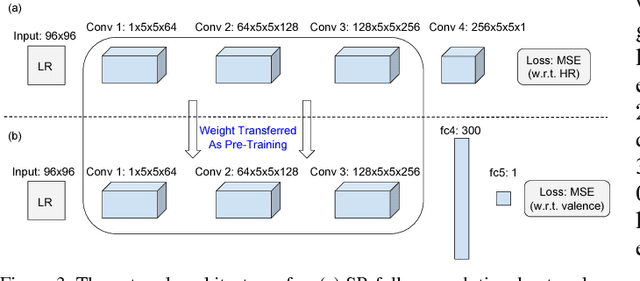
Emotion recognition from facial expressions is tremendously useful, especially when coupled with smart devices and wireless multimedia applications. However, the inadequate network bandwidth often limits the spatial resolution of the transmitted video, which will heavily degrade the recognition reliability. We develop a novel framework to achieve robust emotion recognition from low bit rate video. While video frames are downsampled at the encoder side, the decoder is embedded with a deep network model for joint super-resolution (SR) and recognition. Notably, we propose a novel max-mix training strategy, leading to a single "One-for-All" model that is remarkably robust to a vast range of downsampling factors. That makes our framework well adapted for the varied bandwidths in real transmission scenarios, without hampering scalability or efficiency. The proposed framework is evaluated on the AVEC 2016 benchmark, and demonstrates significantly improved stand-alone recognition performance, as well as rate-distortion (R-D) performance, than either directly recognizing from LR frames, or separating SR and recognition.